 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStress Testing Deliberative Alignment for Anti-Scheming Training
Sep 19, 2025



Highly capable AI systems could secretly pursue misaligned goals -- what we call "scheming". Because a scheming AI would deliberately try to hide its misaligned goals and actions, measuring and mitigating scheming requires different strategies than are typically used in ML. We propose that assessing anti-scheming interventions requires at least (1) testing propensity to scheme on far out-of-distribution (OOD) tasks, (2) evaluating whether lack of scheming is driven by situational awareness, and (3) checking for robustness to pre-existing misaligned goals. We use a broad category of "covert actions" -- such as secretly breaking rules or intentionally underperforming in tests -- as a proxy for scheming, and design evaluations for covert actions. We then stress-test deliberative alignment as a case study for anti-scheming. Across 26 OOD evaluations (180+ environments), deliberative alignment reduces covert action rates (OpenAI o3: 13%->0.4%) but does not fully eliminate them. Our mitigation is also able to largely stop agents from pursuing a hidden goal previously trained into the model, but we still find misbehavior after additional red-teaming. We find that models' chain-of-thought (CoT) often demonstrates awareness of being evaluated for alignment, and show causal evidence that this awareness decreases covert behavior, while unawareness increases it. Therefore, we cannot exclude that the observed reductions in covert action rates are at least partially driven by situational awareness. While we rely on human-legible CoT for training, studying situational awareness, and demonstrating clear evidence of misalignment, our ability to rely on this degrades as models continue to depart from reasoning in standard English. We encourage research into alignment mitigations for scheming and their assessment, especially for the adversarial case of deceptive alignment, which this paper does not address.
Detecting Strategic Deception Using Linear Probes
Feb 05, 2025



AI models might use deceptive strategies as part of scheming or misaligned behaviour. Monitoring outputs alone is insufficient, since the AI might produce seemingly benign outputs while their internal reasoning is misaligned. We thus evaluate if linear probes can robustly detect deception by monitoring model activations. We test two probe-training datasets, one with contrasting instructions to be honest or deceptive (following Zou et al., 2023) and one of responses to simple roleplaying scenarios. We test whether these probes generalize to realistic settings where Llama-3.3-70B-Instruct behaves deceptively, such as concealing insider trading (Scheurer et al., 2023) and purposely underperforming on safety evaluations (Benton et al., 2024). We find that our probe distinguishes honest and deceptive responses with AUROCs between 0.96 and 0.999 on our evaluation datasets. If we set the decision threshold to have a 1% false positive rate on chat data not related to deception, our probe catches 95-99% of the deceptive responses. Overall we think white-box probes are promising for future monitoring systems, but current performance is insufficient as a robust defence against deception. Our probes' outputs can be viewed at data.apolloresearch.ai/dd and our code at github.com/ApolloResearch/deception-detection.
Open Problems in Mechanistic Interpretability
Jan 27, 2025



Mechanistic interpretability aims to understand the computational mechanisms underlying neural networks' capabilities in order to accomplish concrete scientific and engineering goals. Progress in this field thus promises to provide greater assurance over AI system behavior and shed light on exciting scientific questions about the nature of intelligence. Despite recent progress toward these goals, there are many open problems in the field that require solutions before many scientific and practical benefits can be realized: Our methods require both conceptual and practical improvements to reveal deeper insights; we must figure out how best to apply our methods in pursuit of specific goals; and the field must grapple with socio-technical challenges that influence and are influenced by our work. This forward-facing review discusses the current frontier of mechanistic interpretability and the open problems that the field may benefit from prioritizing.
Towards evaluations-based safety cases for AI scheming
Nov 07, 2024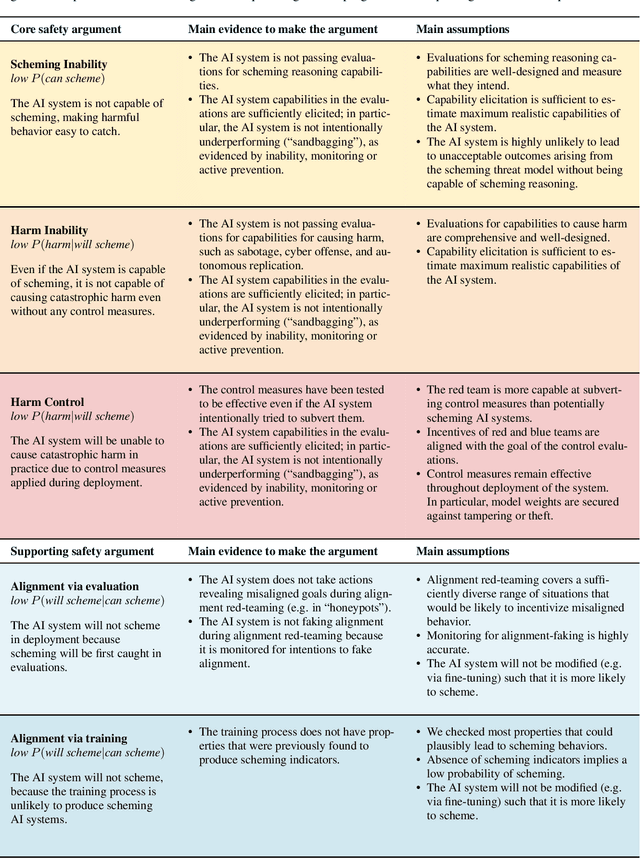
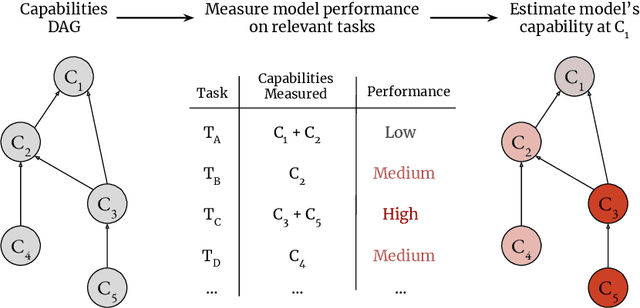
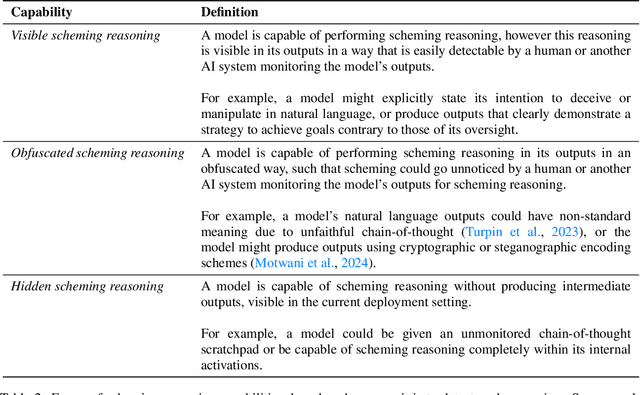
We sketch how developers of frontier AI systems could construct a structured rationale -- a 'safety case' -- that an AI system is unlikely to cause catastrophic outcomes through scheming. Scheming is a potential threat model where AI systems could pursue misaligned goals covertly, hiding their true capabilities and objectives. In this report, we propose three arguments that safety cases could use in relation to scheming. For each argument we sketch how evidence could be gathered from empirical evaluations, and what assumptions would need to be met to provide strong assurance. First, developers of frontier AI systems could argue that AI systems are not capable of scheming (Scheming Inability). Second, one could argue that AI systems are not capable of posing harm through scheming (Harm Inability). Third, one could argue that control measures around the AI systems would prevent unacceptable outcomes even if the AI systems intentionally attempted to subvert them (Harm Control). Additionally, we discuss how safety cases might be supported by evidence that an AI system is reasonably aligned with its developers (Alignment). Finally, we point out that many of the assumptions required to make these safety arguments have not been confidently satisfied to date and require making progress on multiple open research problems.
Using Degeneracy in the Loss Landscape for Mechanistic Interpretability
May 17, 2024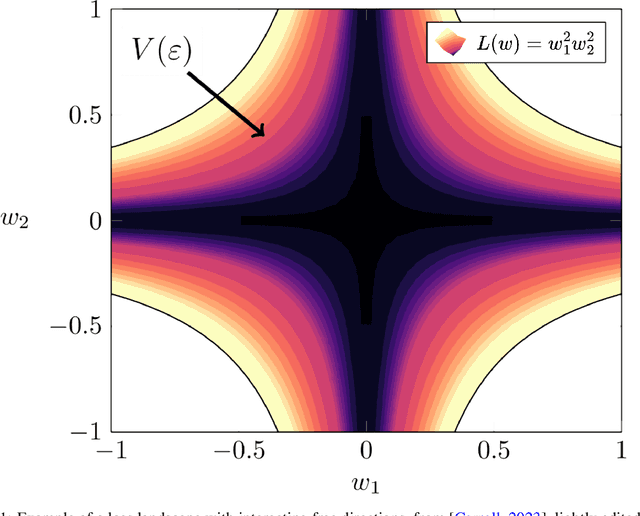
Mechanistic Interpretability aims to reverse engineer the algorithms implemented by neural networks by studying their weights and activations. An obstacle to reverse engineering neural networks is that many of the parameters inside a network are not involved in the computation being implemented by the network. These degenerate parameters may obfuscate internal structure. Singular learning theory teaches us that neural network parameterizations are biased towards being more degenerate, and parameterizations with more degeneracy are likely to generalize further. We identify 3 ways that network parameters can be degenerate: linear dependence between activations in a layer; linear dependence between gradients passed back to a layer; ReLUs which fire on the same subset of datapoints. We also present a heuristic argument that modular networks are likely to be more degenerate, and we develop a metric for identifying modules in a network that is based on this argument. We propose that if we can represent a neural network in a way that is invariant to reparameterizations that exploit the degeneracies, then this representation is likely to be more interpretable, and we provide some evidence that such a representation is likely to have sparser interactions. We introduce the Interaction Basis, a tractable technique to obtain a representation that is invariant to degeneracies from linear dependence of activations or Jacobians.
Identifying Functionally Important Features with End-to-End Sparse Dictionary Learning
May 17, 2024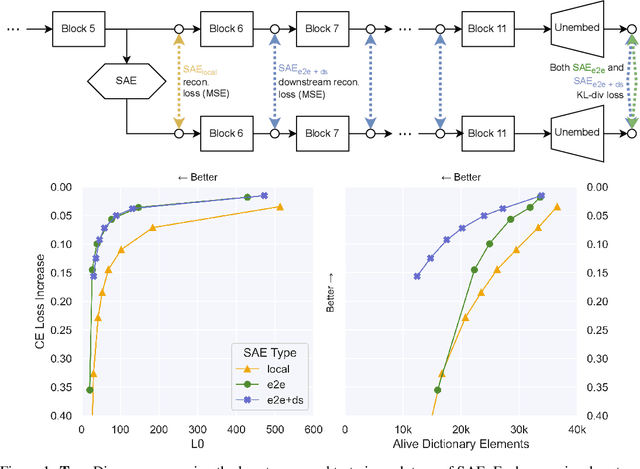

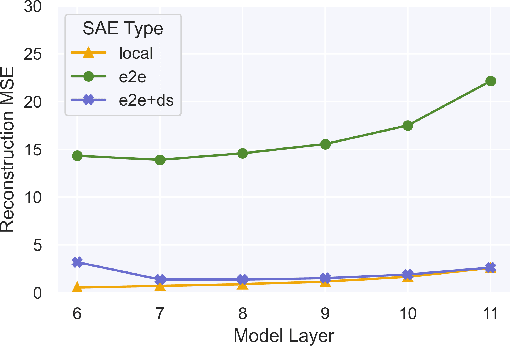
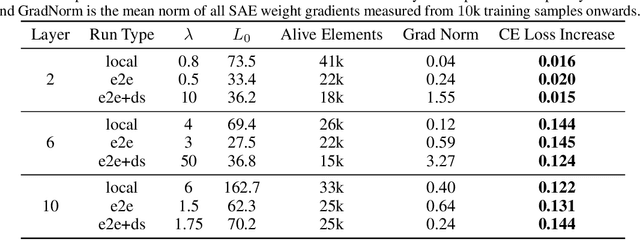
Identifying the features learned by neural networks is a core challenge in mechanistic interpretability. Sparse autoencoders (SAEs), which learn a sparse, overcomplete dictionary that reconstructs a network's internal activations, have been used to identify these features. However, SAEs may learn more about the structure of the datatset than the computational structure of the network. There is therefore only indirect reason to believe that the directions found in these dictionaries are functionally important to the network. We propose end-to-end (e2e) sparse dictionary learning, a method for training SAEs that ensures the features learned are functionally important by minimizing the KL divergence between the output distributions of the original model and the model with SAE activations inserted. Compared to standard SAEs, e2e SAEs offer a Pareto improvement: They explain more network performance, require fewer total features, and require fewer simultaneously active features per datapoint, all with no cost to interpretability. We explore geometric and qualitative differences between e2e SAE features and standard SAE features. E2e dictionary learning brings us closer to methods that can explain network behavior concisely and accurately. We release our library for training e2e SAEs and reproducing our analysis at https://github.com/ApolloResearch/e2e_sae
Localizing Model Behavior with Path Patching
Apr 12, 2023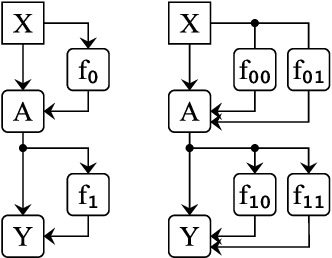
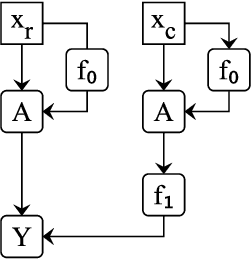

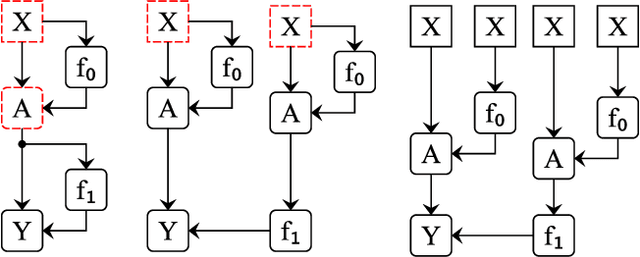
Localizing behaviors of neural networks to a subset of the network's components or a subset of interactions between components is a natural first step towards analyzing network mechanisms and possible failure modes. Existing work is often qualitative and ad-hoc, and there is no consensus on the appropriate way to evaluate localization claims. We introduce path patching, a technique for expressing and quantitatively testing a natural class of hypotheses expressing that behaviors are localized to a set of paths. We refine an explanation of induction heads, characterize a behavior of GPT-2, and open source a framework for efficiently running similar experiments.