 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Deployment Information Sharing: A Zoning Taxonomy for Precursory Capabilities
Nov 18, 2024High-impact and potentially dangerous capabilities can and should be broken down into early warning shots long before reaching red lines. Each of these early warning shots should correspond to a precursory capability. Each precursory capability sits on a spectrum indicating its proximity to a final high-impact capability, corresponding to a red line. To meaningfully detect and track capability progress, we propose a taxonomy of dangerous capability zones (a zoning taxonomy) tied to a staggered information exchange framework that enables relevant bodies to take action accordingly. In the Frontier AI Safety Commitments, signatories commit to sharing more detailed information with trusted actors, including an appointed body, as appropriate (Commitment VII). Building on our zoning taxonomy, this paper makes four recommendations for specifying information sharing as detailed in Commitment VII. (1) Precursory capabilities should be shared as soon as they become known through internal evaluations before deployment. (2) AI Safety Institutes (AISIs) should be the trusted actors appointed to receive and coordinate information on precursory components. (3) AISIs should establish adequate information protection infrastructure and guarantee increased information security as precursory capabilities move through the zones and towards red lines, including, if necessary, by classifying the information on precursory capabilities or marking it as controlled. (4) High-impact capability progress in one geographical region may translate to risk in other regions and necessitates more comprehensive risk assessment internationally. As such, AISIs should exchange information on precursory capabilities with other AISIs, relying on the existing frameworks on international classified exchanges and applying lessons learned from other regulated high-risk sectors.
Towards evaluations-based safety cases for AI scheming
Nov 07, 2024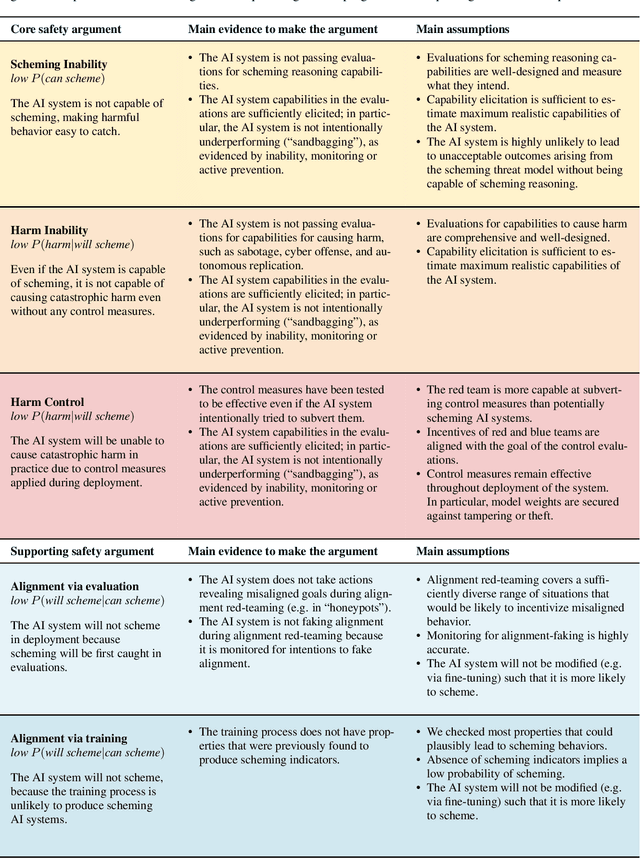
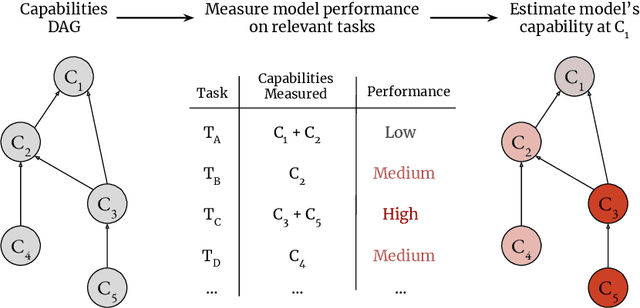
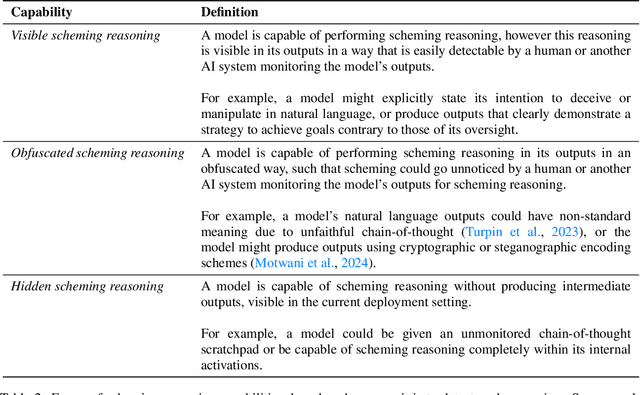
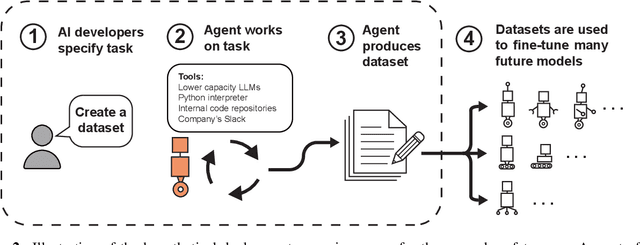
We sketch how developers of frontier AI systems could construct a structured rationale -- a 'safety case' -- that an AI system is unlikely to cause catastrophic outcomes through scheming. Scheming is a potential threat model where AI systems could pursue misaligned goals covertly, hiding their true capabilities and objectives. In this report, we propose three arguments that safety cases could use in relation to scheming. For each argument we sketch how evidence could be gathered from empirical evaluations, and what assumptions would need to be met to provide strong assurance. First, developers of frontier AI systems could argue that AI systems are not capable of scheming (Scheming Inability). Second, one could argue that AI systems are not capable of posing harm through scheming (Harm Inability). Third, one could argue that control measures around the AI systems would prevent unacceptable outcomes even if the AI systems intentionally attempted to subvert them (Harm Control). Additionally, we discuss how safety cases might be supported by evidence that an AI system is reasonably aligned with its developers (Alignment). Finally, we point out that many of the assumptions required to make these safety arguments have not been confidently satisfied to date and require making progress on multiple open research problems.