Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalizing Model Behavior with Path Patching
Paper and Code
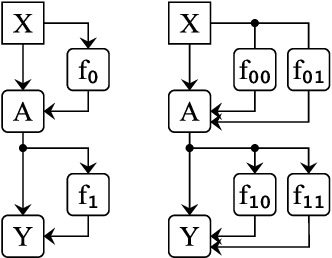
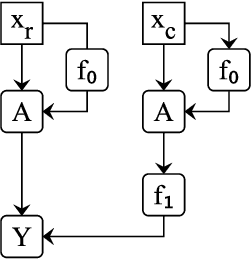

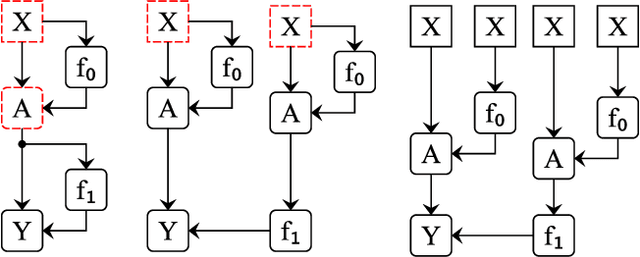
Localizing behaviors of neural networks to a subset of the network's components or a subset of interactions between components is a natural first step towards analyzing network mechanisms and possible failure modes. Existing work is often qualitative and ad-hoc, and there is no consensus on the appropriate way to evaluate localization claims. We introduce path patching, a technique for expressing and quantitatively testing a natural class of hypotheses expressing that behaviors are localized to a set of paths. We refine an explanation of induction heads, characterize a behavior of GPT-2, and open source a framework for efficiently running similar experiments.
* 20 pages, 16 figures
View paper on