 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human experts
Nov 22, 2024Frontier AI safety policies highlight automation of AI research and development (R&D) by AI agents as an important capability to anticipate. However, there exist few evaluations for AI R&D capabilities, and none that are highly realistic and have a direct comparison to human performance. We introduce RE-Bench (Research Engineering Benchmark, v1), which consists of 7 challenging, open-ended ML research engineering environments and data from 71 8-hour attempts by 61 distinct human experts. We confirm that our experts make progress in the environments given 8 hours, with 82% of expert attempts achieving a non-zero score and 24% matching or exceeding our strong reference solutions. We compare humans to several public frontier models through best-of-k with varying time budgets and agent designs, and find that the best AI agents achieve a score 4x higher than human experts when both are given a total time budget of 2 hours per environment. However, humans currently display better returns to increasing time budgets, narrowly exceeding the top AI agent scores given an 8-hour budget, and achieving 2x the score of the top AI agent when both are given 32 total hours (across different attempts). Qualitatively, we find that modern AI agents possess significant expertise in many ML topics -- e.g. an agent wrote a faster custom Triton kernel than any of our human experts' -- and can generate and test solutions over ten times faster than humans, at much lower cost. We open-source the evaluation environments, human expert data, analysis code and agent trajectories to facilitate future research.
Localizing Model Behavior with Path Patching
Apr 12, 2023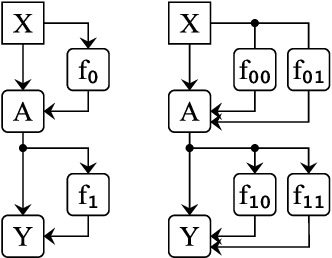
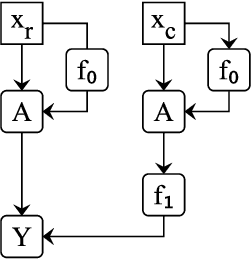

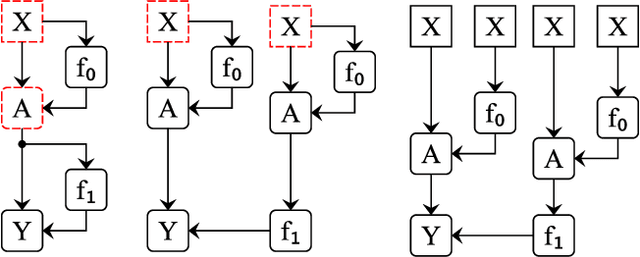
Localizing behaviors of neural networks to a subset of the network's components or a subset of interactions between components is a natural first step towards analyzing network mechanisms and possible failure modes. Existing work is often qualitative and ad-hoc, and there is no consensus on the appropriate way to evaluate localization claims. We introduce path patching, a technique for expressing and quantitatively testing a natural class of hypotheses expressing that behaviors are localized to a set of paths. We refine an explanation of induction heads, characterize a behavior of GPT-2, and open source a framework for efficiently running similar experiments.