 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Algorithmic Gaze: An Audit and Ethnography of the LAION-Aesthetics Predictor Model
Jan 14, 2026Visual generative AI models are trained using a one-size-fits-all measure of aesthetic appeal. However, what is deemed "aesthetic" is inextricably linked to personal taste and cultural values, raising the question of whose taste is represented in visual generative AI models. In this work, we study an aesthetic evaluation model--LAION Aesthetic Predictor (LAP)--that is widely used to curate datasets to train visual generative image models, like Stable Diffusion, and evaluate the quality of AI-generated images. To understand what LAP measures, we audited the model across three datasets. First, we examined the impact of aesthetic filtering on the LAION-Aesthetics Dataset (approximately 1.2B images), which was curated from LAION-5B using LAP. We find that the LAP disproportionally filters in images with captions mentioning women, while filtering out images with captions mentioning men or LGBTQ+ people. Then, we used LAP to score approximately 330k images across two art datasets, finding the model rates realistic images of landscapes, cityscapes, and portraits from western and Japanese artists most highly. In doing so, the algorithmic gaze of this aesthetic evaluation model reinforces the imperial and male gazes found within western art history. In order to understand where these biases may have originated, we performed a digital ethnography of public materials related to the creation of LAP. We find that the development of LAP reflects the biases we found in our audits, such as the aesthetic scores used to train LAP primarily coming from English-speaking photographers and western AI-enthusiasts. In response, we discuss how aesthetic evaluation can perpetuate representational harms and call on AI developers to shift away from prescriptive measures of "aesthetics" toward more pluralistic evaluation.
Auditing Games for Sandbagging
Dec 08, 2025Future AI systems could conceal their capabilities ('sandbagging') during evaluations, potentially misleading developers and auditors. We stress-tested sandbagging detection techniques using an auditing game. First, a red team fine-tuned five models, some of which conditionally underperformed, as a proxy for sandbagging. Second, a blue team used black-box, model-internals, or training-based approaches to identify sandbagging models. We found that the blue team could not reliably discriminate sandbaggers from benign models. Black-box approaches were defeated by effective imitation of a weaker model. Linear probes, a model-internals approach, showed more promise but their naive application was vulnerable to behaviours instilled by the red team. We also explored capability elicitation as a strategy for detecting sandbagging. Although Prompt-based elicitation was not reliable, training-based elicitation consistently elicited full performance from the sandbagging models, using only a single correct demonstration of the evaluation task. However the performance of benign models was sometimes also raised, so relying on elicitation as a detection strategy was prone to false-positives. In the short-term, we recommend developers remove potential sandbagging using on-distribution training for elicitation. In the longer-term, further research is needed to ensure the efficacy of training-based elicitation, and develop robust methods for sandbagging detection. We open source our model organisms at https://github.com/AI-Safety-Institute/sandbagging_auditing_games and select transcripts and results at https://huggingface.co/datasets/sandbagging-games/evaluation_logs . A demo illustrating the game can be played at https://sandbagging-demo.far.ai/ .
Un-Straightening Generative AI: How Queer Artists Surface and Challenge the Normativity of Generative AI Models
Mar 12, 2025Queer people are often discussed as targets of bias, harm, or discrimination in research on generative AI. However, the specific ways that queer people engage with generative AI, and thus possible uses that support queer people, have yet to be explored. We conducted a workshop study with 13 queer artists, during which we gave participants access to GPT-4 and DALL-E 3 and facilitated group sensemaking activities. We found our participants struggled to use these models due to various normative values embedded in their designs, such as hyper-positivity and anti-sexuality. We describe various strategies our participants developed to overcome these models' limitations and how, nevertheless, our participants found value in these highly-normative technologies. Drawing on queer feminist theory, we discuss implications for the conceptualization of "state-of-the-art" models and consider how FAccT researchers might support queer alternatives.
Obfuscated Activations Bypass LLM Latent-Space Defenses
Dec 12, 2024Recent latent-space monitoring techniques have shown promise as defenses against LLM attacks. These defenses act as scanners that seek to detect harmful activations before they lead to undesirable actions. This prompts the question: Can models execute harmful behavior via inconspicuous latent states? Here, we study such obfuscated activations. We show that state-of-the-art latent-space defenses -- including sparse autoencoders, representation probing, and latent OOD detection -- are all vulnerable to obfuscated activations. For example, against probes trained to classify harmfulness, our attacks can often reduce recall from 100% to 0% while retaining a 90% jailbreaking rate. However, obfuscation has limits: we find that on a complex task (writing SQL code), obfuscation reduces model performance. Together, our results demonstrate that neural activations are highly malleable: we can reshape activation patterns in a variety of ways, often while preserving a network's behavior. This poses a fundamental challenge to latent-space defenses.
Identifying Functionally Important Features with End-to-End Sparse Dictionary Learning
May 17, 2024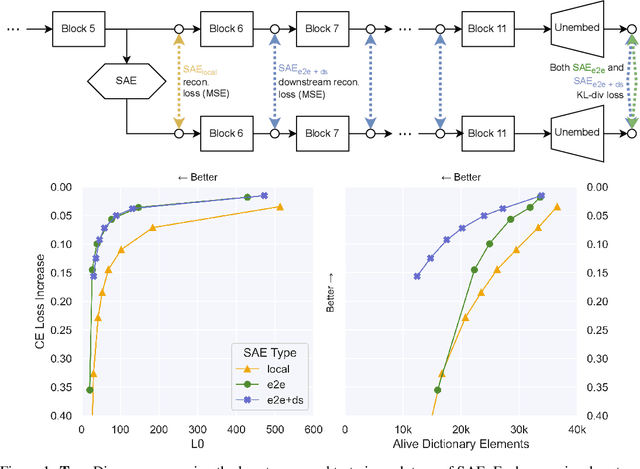

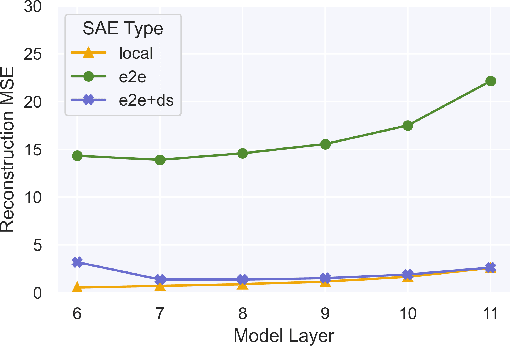
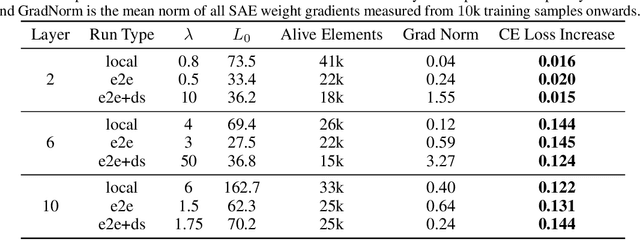
Identifying the features learned by neural networks is a core challenge in mechanistic interpretability. Sparse autoencoders (SAEs), which learn a sparse, overcomplete dictionary that reconstructs a network's internal activations, have been used to identify these features. However, SAEs may learn more about the structure of the datatset than the computational structure of the network. There is therefore only indirect reason to believe that the directions found in these dictionaries are functionally important to the network. We propose end-to-end (e2e) sparse dictionary learning, a method for training SAEs that ensures the features learned are functionally important by minimizing the KL divergence between the output distributions of the original model and the model with SAE activations inserted. Compared to standard SAEs, e2e SAEs offer a Pareto improvement: They explain more network performance, require fewer total features, and require fewer simultaneously active features per datapoint, all with no cost to interpretability. We explore geometric and qualitative differences between e2e SAE features and standard SAE features. E2e dictionary learning brings us closer to methods that can explain network behavior concisely and accurately. We release our library for training e2e SAEs and reproducing our analysis at https://github.com/ApolloResearch/e2e_sae
ClimateGPT: Towards AI Synthesizing Interdisciplinary Research on Climate Change
Jan 17, 2024This paper introduces ClimateGPT, a model family of domain-specific large language models that synthesize interdisciplinary research on climate change. We trained two 7B models from scratch on a science-oriented dataset of 300B tokens. For the first model, the 4.2B domain-specific tokens were included during pre-training and the second was adapted to the climate domain after pre-training. Additionally, ClimateGPT-7B, 13B and 70B are continuously pre-trained from Llama~2 on a domain-specific dataset of 4.2B tokens. Each model is instruction fine-tuned on a high-quality and human-generated domain-specific dataset that has been created in close cooperation with climate scientists. To reduce the number of hallucinations, we optimize the model for retrieval augmentation and propose a hierarchical retrieval strategy. To increase the accessibility of our model to non-English speakers, we propose to make use of cascaded machine translation and show that this approach can perform comparably to natively multilingual models while being easier to scale to a large number of languages. Further, to address the intrinsic interdisciplinary aspect of climate change we consider different research perspectives. Therefore, the model can produce in-depth answers focusing on different perspectives in addition to an overall answer. We propose a suite of automatic climate-specific benchmarks to evaluate LLMs. On these benchmarks, ClimateGPT-7B performs on par with the ten times larger Llama-2-70B Chat model while not degrading results on general domain benchmarks. Our human evaluation confirms the trends we saw in our benchmarks. All models were trained and evaluated using renewable energy and are released publicly.
LLMs as Workers in Human-Computational Algorithms? Replicating Crowdsourcing Pipelines with LLMs
Jul 20, 2023

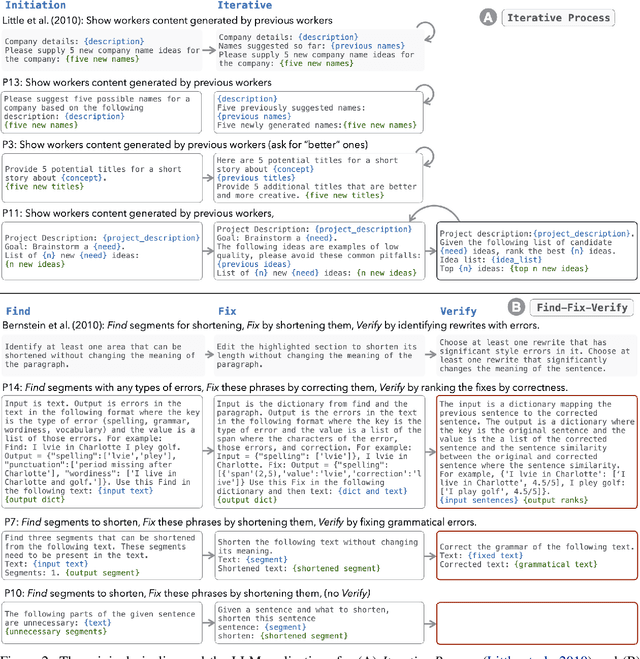
LLMs have shown promise in replicating human-like behavior in crowdsourcing tasks that were previously thought to be exclusive to human abilities. However, current efforts focus mainly on simple atomic tasks. We explore whether LLMs can replicate more complex crowdsourcing pipelines. We find that modern LLMs can simulate some of crowdworkers' abilities in these "human computation algorithms," but the level of success is variable and influenced by requesters' understanding of LLM capabilities, the specific skills required for sub-tasks, and the optimal interaction modality for performing these sub-tasks. We reflect on human and LLMs' different sensitivities to instructions, stress the importance of enabling human-facing safeguards for LLMs, and discuss the potential of training humans and LLMs with complementary skill sets. Crucially, we show that replicating crowdsourcing pipelines offers a valuable platform to investigate (1) the relative strengths of LLMs on different tasks (by cross-comparing their performances on sub-tasks) and (2) LLMs' potential in complex tasks, where they can complete part of the tasks while leaving others to humans.
Seeing Seeds Beyond Weeds: Green Teaming Generative AI for Beneficial Uses
May 30, 2023
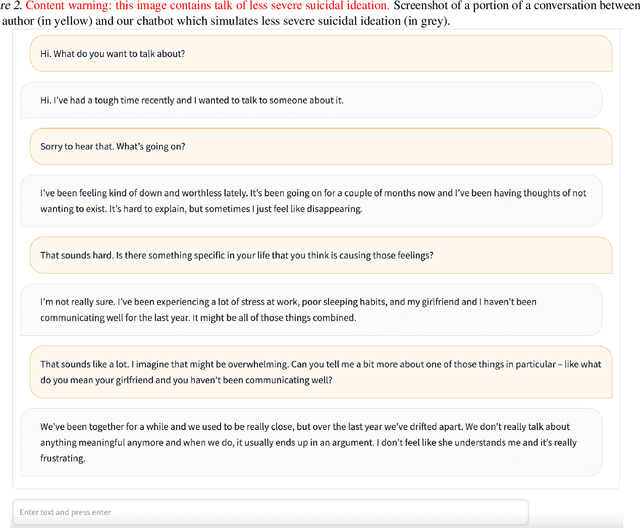
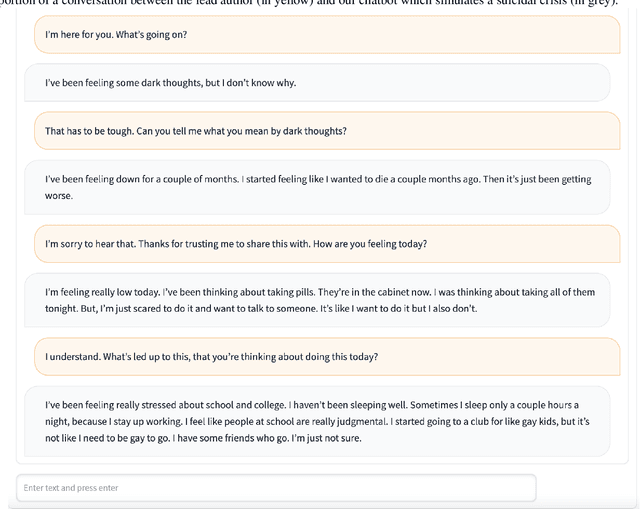
Large generative AI models (GMs) like GPT and DALL-E are trained to generate content for general, wide-ranging purposes. GM content filters are generalized to filter out content which has a risk of harm in many cases, e.g., hate speech. However, prohibited content is not always harmful -- there are instances where generating prohibited content can be beneficial. So, when GMs filter out content, they preclude beneficial use cases along with harmful ones. Which use cases are precluded reflects the values embedded in GM content filtering. Recent work on red teaming proposes methods to bypass GM content filters to generate harmful content. We coin the term green teaming to describe methods of bypassing GM content filters to design for beneficial use cases. We showcase green teaming by: 1) Using ChatGPT as a virtual patient to simulate a person experiencing suicidal ideation, for suicide support training; 2) Using Codex to intentionally generate buggy solutions to train students on debugging; and 3) Examining an Instagram page using Midjourney to generate images of anti-LGBTQ+ politicians in drag. Finally, we discuss how our use cases demonstrate green teaming as both a practical design method and a mode of critique, which problematizes and subverts current understandings of harms and values in generative AI.