 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimateGPT: Towards AI Synthesizing Interdisciplinary Research on Climate Change
Jan 17, 2024This paper introduces ClimateGPT, a model family of domain-specific large language models that synthesize interdisciplinary research on climate change. We trained two 7B models from scratch on a science-oriented dataset of 300B tokens. For the first model, the 4.2B domain-specific tokens were included during pre-training and the second was adapted to the climate domain after pre-training. Additionally, ClimateGPT-7B, 13B and 70B are continuously pre-trained from Llama~2 on a domain-specific dataset of 4.2B tokens. Each model is instruction fine-tuned on a high-quality and human-generated domain-specific dataset that has been created in close cooperation with climate scientists. To reduce the number of hallucinations, we optimize the model for retrieval augmentation and propose a hierarchical retrieval strategy. To increase the accessibility of our model to non-English speakers, we propose to make use of cascaded machine translation and show that this approach can perform comparably to natively multilingual models while being easier to scale to a large number of languages. Further, to address the intrinsic interdisciplinary aspect of climate change we consider different research perspectives. Therefore, the model can produce in-depth answers focusing on different perspectives in addition to an overall answer. We propose a suite of automatic climate-specific benchmarks to evaluate LLMs. On these benchmarks, ClimateGPT-7B performs on par with the ten times larger Llama-2-70B Chat model while not degrading results on general domain benchmarks. Our human evaluation confirms the trends we saw in our benchmarks. All models were trained and evaluated using renewable energy and are released publicly.
Cats, not CAT scans: a study of dataset similarity in transfer learning for 2D medical image classification
Jul 13, 2021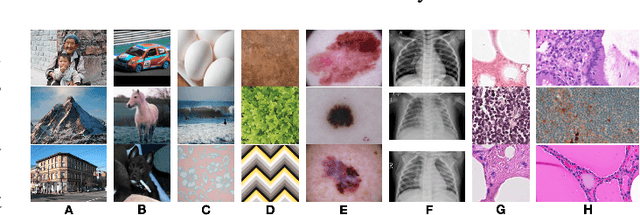
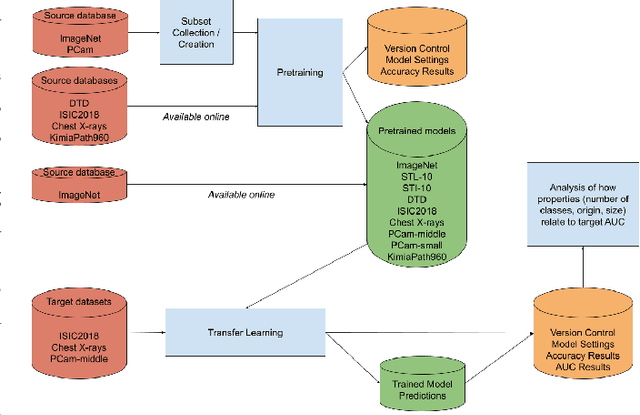
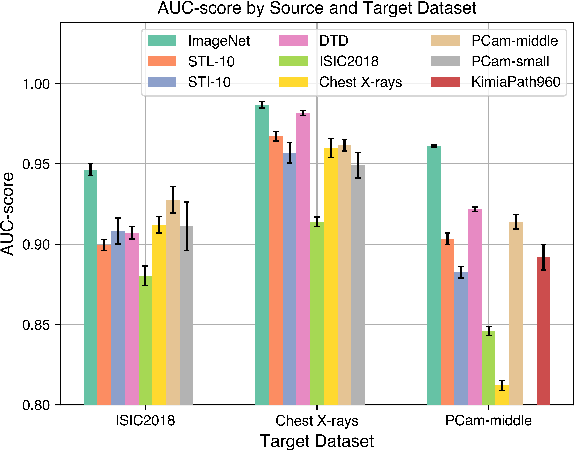
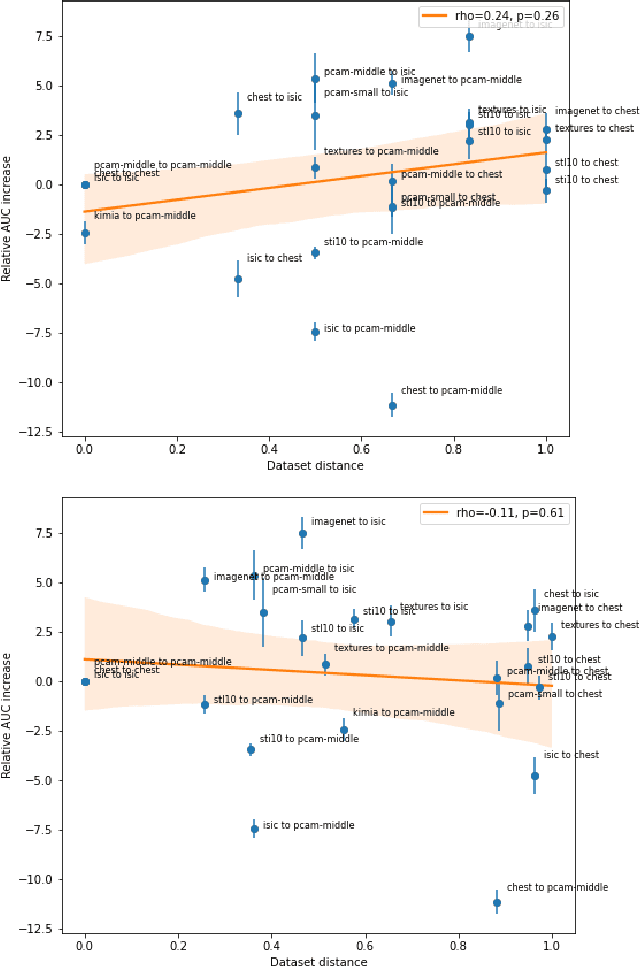
Transfer learning is a commonly used strategy for medical image classification, especially via pretraining on source data and fine-tuning on target data. There is currently no consensus on how to choose appropriate source data, and in the literature we can find both evidence of favoring large natural image datasets such as ImageNet, and evidence of favoring more specialized medical datasets. In this paper we perform a systematic study with nine source datasets with natural or medical images, and three target medical datasets, all with 2D images. We find that ImageNet is the source leading to the highest performances, but also that larger datasets are not necessarily better. We also study different definitions of data similarity. We show that common intuitions about similarity may be inaccurate, and therefore not sufficient to predict an appropriate source a priori. Finally, we discuss several steps needed for further research in this field, especially with regard to other types (for example 3D) medical images. Our experiments and pretrained models are available via \url{https://www.github.com/vcheplygina/cats-scans}