 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Gender Bias in Large Language Models: An In-depth Dive into the German Language
Jul 22, 2025


In recent years, various methods have been proposed to evaluate gender bias in large language models (LLMs). A key challenge lies in the transferability of bias measurement methods initially developed for the English language when applied to other languages. This work aims to contribute to this research strand by presenting five German datasets for gender bias evaluation in LLMs. The datasets are grounded in well-established concepts of gender bias and are accessible through multiple methodologies. Our findings, reported for eight multilingual LLM models, reveal unique challenges associated with gender bias in German, including the ambiguous interpretation of male occupational terms and the influence of seemingly neutral nouns on gender perception. This work contributes to the understanding of gender bias in LLMs across languages and underscores the necessity for tailored evaluation frameworks.
Listen to the Context: Towards Faithful Large Language Models for Retrieval Augmented Generation on Climate Questions
May 21, 2025Large language models that use retrieval augmented generation have the potential to unlock valuable knowledge for researchers, policymakers, and the public by making long and technical climate-related documents more accessible. While this approach can help alleviate factual hallucinations by relying on retrieved passages as additional context, its effectiveness depends on whether the model's output remains faithful to these passages. To address this, we explore the automatic assessment of faithfulness of different models in this setting. We then focus on ClimateGPT, a large language model specialised in climate science, to examine which factors in its instruction fine-tuning impact the model's faithfulness. By excluding unfaithful subsets of the model's training data, we develop ClimateGPT Faithful+, which achieves an improvement in faithfulness from 30% to 57% in supported atomic claims according to our automatic metric.
Prompting and Fine-Tuning of Small LLMs for Length-Controllable Telephone Call Summarization
Oct 24, 2024



This paper explores the rapid development of a telephone call summarization system utilizing large language models (LLMs). Our approach involves initial experiments with prompting existing LLMs to generate summaries of telephone conversations, followed by the creation of a tailored synthetic training dataset utilizing stronger frontier models. We place special focus on the diversity of the generated data and on the ability to control the length of the generated summaries to meet various use-case specific requirements. The effectiveness of our method is evaluated using two state-of-the-art LLM-as-a-judge-based evaluation techniques to ensure the quality and relevance of the summaries. Our results show that fine-tuned Llama-2-7B-based summarization model performs on-par with GPT-4 in terms of factual accuracy, completeness and conciseness. Our findings demonstrate the potential for quickly bootstrapping a practical and efficient call summarization system.
ClimateGPT: Towards AI Synthesizing Interdisciplinary Research on Climate Change
Jan 17, 2024This paper introduces ClimateGPT, a model family of domain-specific large language models that synthesize interdisciplinary research on climate change. We trained two 7B models from scratch on a science-oriented dataset of 300B tokens. For the first model, the 4.2B domain-specific tokens were included during pre-training and the second was adapted to the climate domain after pre-training. Additionally, ClimateGPT-7B, 13B and 70B are continuously pre-trained from Llama~2 on a domain-specific dataset of 4.2B tokens. Each model is instruction fine-tuned on a high-quality and human-generated domain-specific dataset that has been created in close cooperation with climate scientists. To reduce the number of hallucinations, we optimize the model for retrieval augmentation and propose a hierarchical retrieval strategy. To increase the accessibility of our model to non-English speakers, we propose to make use of cascaded machine translation and show that this approach can perform comparably to natively multilingual models while being easier to scale to a large number of languages. Further, to address the intrinsic interdisciplinary aspect of climate change we consider different research perspectives. Therefore, the model can produce in-depth answers focusing on different perspectives in addition to an overall answer. We propose a suite of automatic climate-specific benchmarks to evaluate LLMs. On these benchmarks, ClimateGPT-7B performs on par with the ten times larger Llama-2-70B Chat model while not degrading results on general domain benchmarks. Our human evaluation confirms the trends we saw in our benchmarks. All models were trained and evaluated using renewable energy and are released publicly.
Exploring Spoken Named Entity Recognition: A Cross-Lingual Perspective
Jul 03, 2023



Recent advancements in Named Entity Recognition (NER) have significantly improved the identification of entities in textual data. However, spoken NER, a specialized field of spoken document retrieval, lags behind due to its limited research and scarce datasets. Moreover, cross-lingual transfer learning in spoken NER has remained unexplored. This paper utilizes transfer learning across Dutch, English, and German using pipeline and End-to-End (E2E) schemes. We employ Wav2Vec2-XLS-R models on custom pseudo-annotated datasets and investigate several architectures for the adaptability of cross-lingual systems. Our results demonstrate that End-to-End spoken NER outperforms pipeline-based alternatives over our limited annotations. Notably, transfer learning from German to Dutch surpasses the Dutch E2E system by 7% and the Dutch pipeline system by 4%. This study not only underscores the feasibility of transfer learning in spoken NER but also sets promising outcomes for future evaluations, hinting at the need for comprehensive data collection to augment the results.
Task-oriented Document-Grounded Dialog Systems by HLTPR@RWTH for DSTC9 and DSTC10
Apr 14, 2023

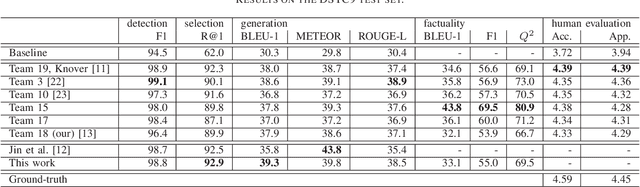
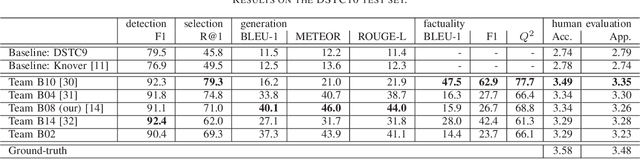
This paper summarizes our contributions to the document-grounded dialog tasks at the 9th and 10th Dialog System Technology Challenges (DSTC9 and DSTC10). In both iterations the task consists of three subtasks: first detect whether the current turn is knowledge seeking, second select a relevant knowledge document, and third generate a response grounded on the selected document. For DSTC9 we proposed different approaches to make the selection task more efficient. The best method, Hierarchical Selection, actually improves the results compared to the original baseline and gives a speedup of 24x. In the DSTC10 iteration of the task, the challenge was to adapt systems trained on written dialogs to perform well on noisy automatic speech recognition transcripts. Therefore, we proposed data augmentation techniques to increase the robustness of the models as well as methods to adapt the style of generated responses to fit well into the proceeding dialog. Additionally, we proposed a noisy channel model that allows for increasing the factuality of the generated responses. In addition to summarizing our previous contributions, in this work, we also report on a few small improvements and reconsider the automatic evaluation metrics for the generation task which have shown a low correlation to human judgments.
Mask More and Mask Later: Efficient Pre-training of Masked Language Models by Disentangling the Token
Nov 15, 2022The pre-training of masked language models (MLMs) consumes massive computation to achieve good results on downstream NLP tasks, resulting in a large carbon footprint. In the vanilla MLM, the virtual tokens, [MASK]s, act as placeholders and gather the contextualized information from unmasked tokens to restore the corrupted information. It raises the question of whether we can append [MASK]s at a later layer, to reduce the sequence length for earlier layers and make the pre-training more efficient. We show: (1) [MASK]s can indeed be appended at a later layer, being disentangled from the word embedding; (2) The gathering of contextualized information from unmasked tokens can be conducted with a few layers. By further increasing the masking rate from 15% to 50%, we can pre-train RoBERTa-base and RoBERTa-large from scratch with only 78% and 68% of the original computational budget without any degradation on the GLUE benchmark. When pre-training with the original budget, our method outperforms RoBERTa for 6 out of 8 GLUE tasks, on average by 0.4%.
Controllable Factuality in Document-Grounded Dialog Systems Using a Noisy Channel Model
Oct 31, 2022



In this work, we present a model for document-grounded response generation in dialog that is decomposed into two components according to Bayes theorem. One component is a traditional ungrounded response generation model and the other component models the reconstruction of the grounding document based on the dialog context and generated response. We propose different approximate decoding schemes and evaluate our approach on multiple open-domain and task-oriented document-grounded dialog datasets. Our experiments show that the model is more factual in terms of automatic factuality metrics than the baseline model. Furthermore, we outline how introducing scaling factors between the components allows for controlling the tradeoff between factuality and fluency in the model output. Finally, we compare our approach to a recently proposed method to control factuality in grounded dialog, CTRL (arXiv:2107.06963), and show that both approaches can be combined to achieve additional improvements.
Does Joint Training Really Help Cascaded Speech Translation?
Oct 24, 2022

Currently, in speech translation, the straightforward approach - cascading a recognition system with a translation system - delivers state-of-the-art results. However, fundamental challenges such as error propagation from the automatic speech recognition system still remain. To mitigate these problems, recently, people turn their attention to direct data and propose various joint training methods. In this work, we seek to answer the question of whether joint training really helps cascaded speech translation. We review recent papers on the topic and also investigate a joint training criterion by marginalizing the transcription posterior probabilities. Our findings show that a strong cascaded baseline can diminish any improvements obtained using joint training, and we suggest alternatives to joint training. We hope this work can serve as a refresher of the current speech translation landscape, and motivate research in finding more efficient and creative ways to utilize the direct data for speech translation.
Adapting Document-Grounded Dialog Systems to Spoken Conversations using Data Augmentation and a Noisy Channel Model
Dec 16, 2021


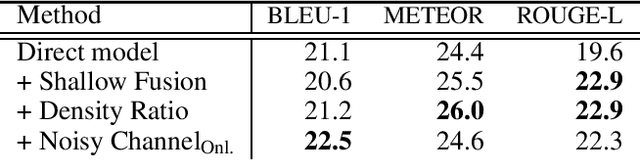
This paper summarizes our submission to Task 2 of the second track of the 10th Dialog System Technology Challenge (DSTC10) "Knowledge-grounded Task-oriented Dialogue Modeling on Spoken Conversations". Similar to the previous year's iteration, the task consists of three subtasks: detecting whether a turn is knowledge seeking, selecting the relevant knowledge document and finally generating a grounded response. This year, the focus lies on adapting the system to noisy ASR transcripts. We explore different approaches to make the models more robust to this type of input and to adapt the generated responses to the style of spoken conversations. For the latter, we get the best results with a noisy channel model that additionally reduces the number of short and generic responses. Our best system achieved the 1st rank in the automatic and the 3rd rank in the human evaluation of the challenge.