 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting and Fine-Tuning of Small LLMs for Length-Controllable Telephone Call Summarization
Oct 24, 2024



This paper explores the rapid development of a telephone call summarization system utilizing large language models (LLMs). Our approach involves initial experiments with prompting existing LLMs to generate summaries of telephone conversations, followed by the creation of a tailored synthetic training dataset utilizing stronger frontier models. We place special focus on the diversity of the generated data and on the ability to control the length of the generated summaries to meet various use-case specific requirements. The effectiveness of our method is evaluated using two state-of-the-art LLM-as-a-judge-based evaluation techniques to ensure the quality and relevance of the summaries. Our results show that fine-tuned Llama-2-7B-based summarization model performs on-par with GPT-4 in terms of factual accuracy, completeness and conciseness. Our findings demonstrate the potential for quickly bootstrapping a practical and efficient call summarization system.
Alternating Weak Triphone/BPE Alignment Supervision from Hybrid Model Improves End-to-End ASR
Feb 23, 2024



In this paper, alternating weak triphone/BPE alignment supervision is proposed to improve end-to-end model training. Towards this end, triphone and BPE alignments are extracted using a pre-existing hybrid ASR system. Then, regularization effect is obtained by cross-entropy based intermediate auxiliary losses computed on such alignments at a mid-layer representation of the encoder for triphone alignments and at the encoder for BPE alignments. Weak supervision is achieved through strong label smoothing with parameter of 0.5. Experimental results on TED-LIUM 2 indicate that either triphone or BPE alignment based weak supervision improves ASR performance over standard CTC auxiliary loss. Moreover, their combination lowers the word error rate further. We also investigate the alternation of the two auxiliary tasks during model training, and additional performance gain is observed. Overall, the proposed techniques result in over 10% relative error rate reduction over a CTC-regularized baseline system.
ClimateGPT: Towards AI Synthesizing Interdisciplinary Research on Climate Change
Jan 17, 2024This paper introduces ClimateGPT, a model family of domain-specific large language models that synthesize interdisciplinary research on climate change. We trained two 7B models from scratch on a science-oriented dataset of 300B tokens. For the first model, the 4.2B domain-specific tokens were included during pre-training and the second was adapted to the climate domain after pre-training. Additionally, ClimateGPT-7B, 13B and 70B are continuously pre-trained from Llama~2 on a domain-specific dataset of 4.2B tokens. Each model is instruction fine-tuned on a high-quality and human-generated domain-specific dataset that has been created in close cooperation with climate scientists. To reduce the number of hallucinations, we optimize the model for retrieval augmentation and propose a hierarchical retrieval strategy. To increase the accessibility of our model to non-English speakers, we propose to make use of cascaded machine translation and show that this approach can perform comparably to natively multilingual models while being easier to scale to a large number of languages. Further, to address the intrinsic interdisciplinary aspect of climate change we consider different research perspectives. Therefore, the model can produce in-depth answers focusing on different perspectives in addition to an overall answer. We propose a suite of automatic climate-specific benchmarks to evaluate LLMs. On these benchmarks, ClimateGPT-7B performs on par with the ten times larger Llama-2-70B Chat model while not degrading results on general domain benchmarks. Our human evaluation confirms the trends we saw in our benchmarks. All models were trained and evaluated using renewable energy and are released publicly.
Weak Alignment Supervision from Hybrid Model Improves End-to-end ASR
Nov 30, 2023



In this paper, we aim to create weak alignment supervision from an existing hybrid system to aid the end-to-end modeling of automatic speech recognition. Towards this end, we use the existing hybrid ASR system to produce triphone alignments of the training audios. We then create a cross-entropy loss at a certain layer of the encoder using the derived alignments. In contrast to the general one-hot cross-entropy losses, here we use a cross-entropy loss with a label smoothing parameter to regularize the supervision. As a comparison, we also conduct the experiments with one-hot cross-entropy losses and CTC losses with loss weighting. The results show that placing the weak alignment supervision with the label smoothing parameter of 0.5 at the third encoder layer outperforms the other two approaches and leads to about 5\% relative WER reduction on the TED-LIUM 2 dataset over the baseline. We see similar improvements when applying the method out-of-the-box on a Tagalog end-to-end ASR system.
Improving Language Model Integration for Neural Machine Translation
Jun 08, 2023The integration of language models for neural machine translation has been extensively studied in the past. It has been shown that an external language model, trained on additional target-side monolingual data, can help improve translation quality. However, there has always been the assumption that the translation model also learns an implicit target-side language model during training, which interferes with the external language model at decoding time. Recently, some works on automatic speech recognition have demonstrated that, if the implicit language model is neutralized in decoding, further improvements can be gained when integrating an external language model. In this work, we transfer this concept to the task of machine translation and compare with the most prominent way of including additional monolingual data - namely back-translation. We find that accounting for the implicit language model significantly boosts the performance of language model fusion, although this approach is still outperformed by back-translation.
Does Joint Training Really Help Cascaded Speech Translation?
Oct 24, 2022

Currently, in speech translation, the straightforward approach - cascading a recognition system with a translation system - delivers state-of-the-art results. However, fundamental challenges such as error propagation from the automatic speech recognition system still remain. To mitigate these problems, recently, people turn their attention to direct data and propose various joint training methods. In this work, we seek to answer the question of whether joint training really helps cascaded speech translation. We review recent papers on the topic and also investigate a joint training criterion by marginalizing the transcription posterior probabilities. Our findings show that a strong cascaded baseline can diminish any improvements obtained using joint training, and we suggest alternatives to joint training. We hope this work can serve as a refresher of the current speech translation landscape, and motivate research in finding more efficient and creative ways to utilize the direct data for speech translation.
Self-Normalized Importance Sampling for Neural Language Modeling
Nov 11, 2021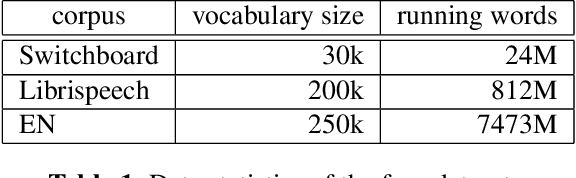
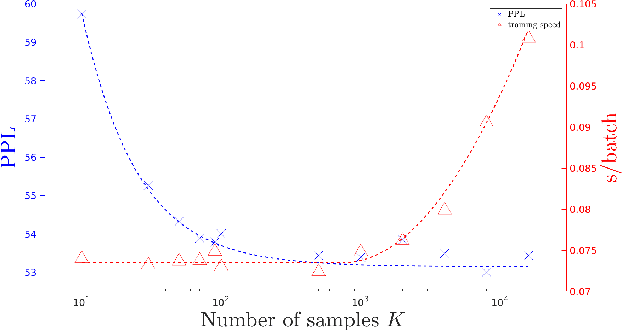
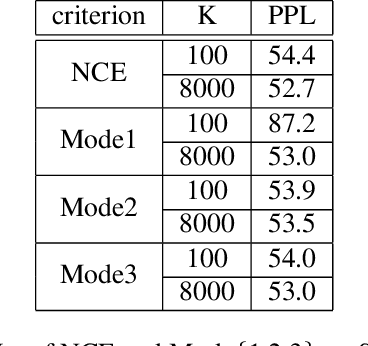

To mitigate the problem of having to traverse over the full vocabulary in the softmax normalization of a neural language model, sampling-based training criteria are proposed and investigated in the context of large vocabulary word-based neural language models. These training criteria typically enjoy the benefit of faster training and testing, at a cost of slightly degraded performance in terms of perplexity and almost no visible drop in word error rate. While noise contrastive estimation is one of the most popular choices, recently we show that other sampling-based criteria can also perform well, as long as an extra correction step is done, where the intended class posterior probability is recovered from the raw model outputs. In this work, we propose self-normalized importance sampling. Compared to our previous work, the criteria considered in this work are self-normalized and there is no need to further conduct a correction step. Compared to noise contrastive estimation, our method is directly comparable in terms of complexity in application. Through self-normalized language model training as well as lattice rescoring experiments, we show that our proposed self-normalized importance sampling is competitive in both research-oriented and production-oriented automatic speech recognition tasks.
On Sampling-Based Training Criteria for Neural Language Modeling
Apr 21, 2021



As the vocabulary size of modern word-based language models becomes ever larger, many sampling-based training criteria are proposed and investigated. The essence of these sampling methods is that the softmax-related traversal over the entire vocabulary can be simplified, giving speedups compared to the baseline. A problem we notice about the current landscape of such sampling methods is the lack of a systematic comparison and some myths about preferring one over another. In this work, we consider Monte Carlo sampling, importance sampling, a novel method we call compensated partial summation, and noise contrastive estimation. Linking back to the three traditional criteria, namely mean squared error, binary cross-entropy, and cross-entropy, we derive the theoretical solutions to the training problems. Contrary to some common belief, we show that all these sampling methods can perform equally well, as long as we correct for the intended class posterior probabilities. Experimental results in language modeling and automatic speech recognition on Switchboard and LibriSpeech support our claim, with all sampling-based methods showing similar perplexities and word error rates while giving the expected speedups.
Diving Deep into Context-Aware Neural Machine Translation
Oct 19, 2020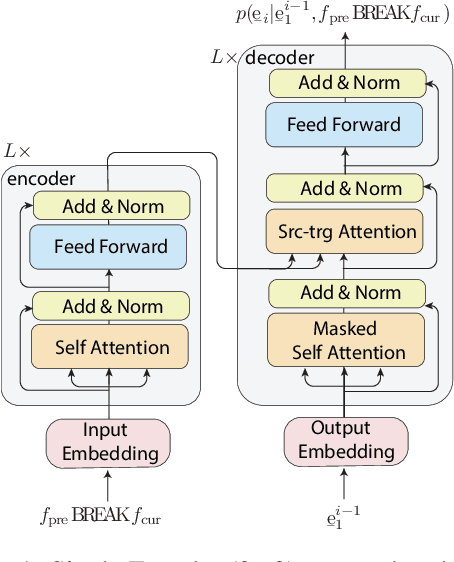

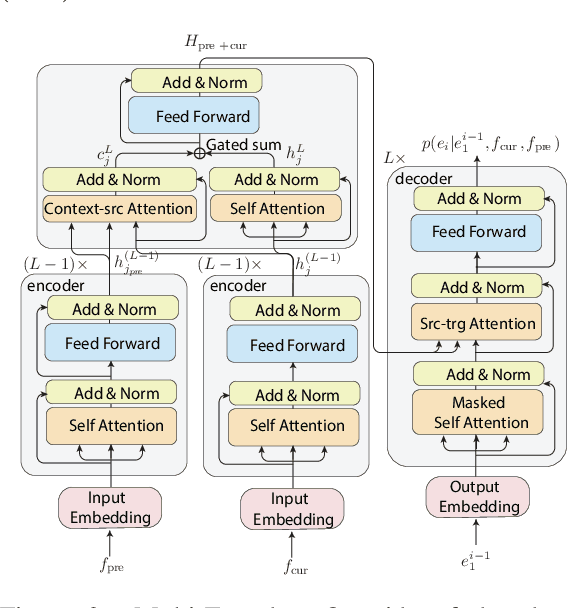
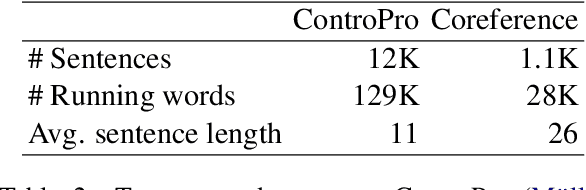
Context-aware neural machine translation (NMT) is a promising direction to improve the translation quality by making use of the additional context, e.g., document-level translation, or having meta-information. Although there exist various architectures and analyses, the effectiveness of different context-aware NMT models is not well explored yet. This paper analyzes the performance of document-level NMT models on four diverse domains with a varied amount of parallel document-level bilingual data. We conduct a comprehensive set of experiments to investigate the impact of document-level NMT. We find that there is no single best approach to document-level NMT, but rather that different architectures come out on top on different tasks. Looking at task-specific problems, such as pronoun resolution or headline translation, we find improvements in the context-aware systems, even in cases where the corpus-level metrics like BLEU show no significant improvement. We also show that document-level back-translation significantly helps to compensate for the lack of document-level bi-texts.
Investigation of Large-Margin Softmax in Neural Language Modeling
May 20, 2020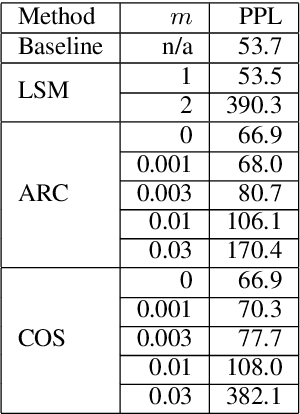
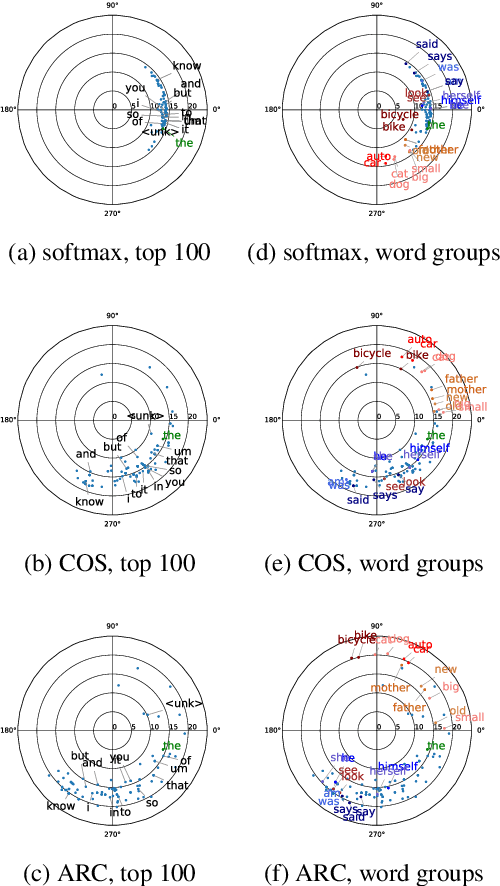
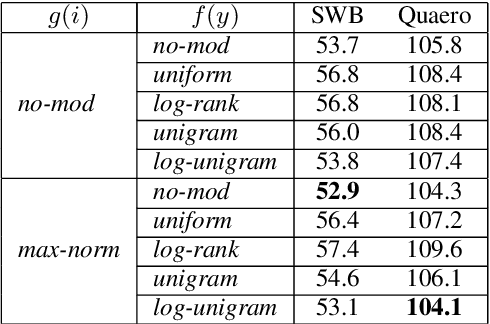
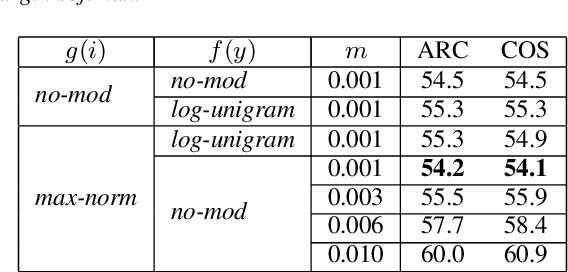
To encourage intra-class compactness and inter-class separability among trainable feature vectors, large-margin softmax methods are developed and widely applied in the face recognition community. The introduction of the large-margin concept into the softmax is reported to have good properties such as enhanced discriminative power, less overfitting and well-defined geometric intuitions. Nowadays, language modeling is commonly approached with neural networks using softmax and cross entropy. In this work, we are curious to see if introducing large-margins to neural language models would improve the perplexity and consequently word error rate in automatic speech recognition. Specifically, we first implement and test various types of conventional margins following the previous works in face recognition. To address the distribution of natural language data, we then compare different strategies for word vector norm-scaling. After that, we apply the best norm-scaling setup in combination with various margins and conduct neural language models rescoring experiments in automatic speech recognition. We find that although perplexity is slightly deteriorated, neural language models with large-margin softmax can yield word error rate similar to that of the standard softmax baseline. Finally, expected margins are analyzed through visualization of word vectors, showing that the syntactic and semantic relationships are also preserved.