 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Normalized Importance Sampling for Neural Language Modeling
Nov 11, 2021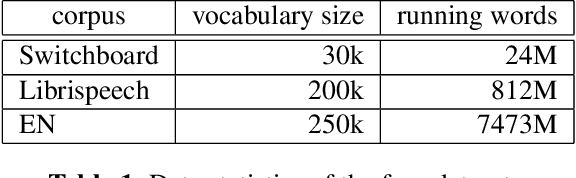
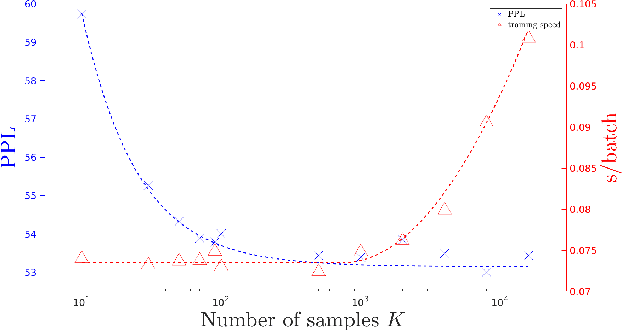
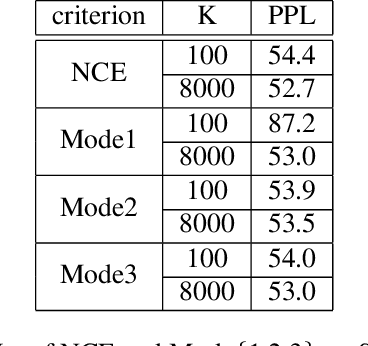

To mitigate the problem of having to traverse over the full vocabulary in the softmax normalization of a neural language model, sampling-based training criteria are proposed and investigated in the context of large vocabulary word-based neural language models. These training criteria typically enjoy the benefit of faster training and testing, at a cost of slightly degraded performance in terms of perplexity and almost no visible drop in word error rate. While noise contrastive estimation is one of the most popular choices, recently we show that other sampling-based criteria can also perform well, as long as an extra correction step is done, where the intended class posterior probability is recovered from the raw model outputs. In this work, we propose self-normalized importance sampling. Compared to our previous work, the criteria considered in this work are self-normalized and there is no need to further conduct a correction step. Compared to noise contrastive estimation, our method is directly comparable in terms of complexity in application. Through self-normalized language model training as well as lattice rescoring experiments, we show that our proposed self-normalized importance sampling is competitive in both research-oriented and production-oriented automatic speech recognition tasks.
Conformer-based Hybrid ASR System for Switchboard Dataset
Nov 05, 2021



The recently proposed conformer architecture has been successfully used for end-to-end automatic speech recognition (ASR) architectures achieving state-of-the-art performance on different datasets. To our best knowledge, the impact of using conformer acoustic model for hybrid ASR is not investigated. In this paper, we present and evaluate a competitive conformer-based hybrid model training recipe. We study different training aspects and methods to improve word-error-rate as well as to increase training speed. We apply time downsampling methods for efficient training and use transposed convolutions to upsample the output sequence again. We conduct experiments on Switchboard 300h dataset and our conformer-based hybrid model achieves competitive results compared to other architectures. It generalizes very well on Hub5'01 test set and outperforms the BLSTM-based hybrid model significantly.
On Sampling-Based Training Criteria for Neural Language Modeling
Apr 21, 2021



As the vocabulary size of modern word-based language models becomes ever larger, many sampling-based training criteria are proposed and investigated. The essence of these sampling methods is that the softmax-related traversal over the entire vocabulary can be simplified, giving speedups compared to the baseline. A problem we notice about the current landscape of such sampling methods is the lack of a systematic comparison and some myths about preferring one over another. In this work, we consider Monte Carlo sampling, importance sampling, a novel method we call compensated partial summation, and noise contrastive estimation. Linking back to the three traditional criteria, namely mean squared error, binary cross-entropy, and cross-entropy, we derive the theoretical solutions to the training problems. Contrary to some common belief, we show that all these sampling methods can perform equally well, as long as we correct for the intended class posterior probabilities. Experimental results in language modeling and automatic speech recognition on Switchboard and LibriSpeech support our claim, with all sampling-based methods showing similar perplexities and word error rates while giving the expected speedups.