 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlternating Weak Triphone/BPE Alignment Supervision from Hybrid Model Improves End-to-End ASR
Feb 23, 2024



In this paper, alternating weak triphone/BPE alignment supervision is proposed to improve end-to-end model training. Towards this end, triphone and BPE alignments are extracted using a pre-existing hybrid ASR system. Then, regularization effect is obtained by cross-entropy based intermediate auxiliary losses computed on such alignments at a mid-layer representation of the encoder for triphone alignments and at the encoder for BPE alignments. Weak supervision is achieved through strong label smoothing with parameter of 0.5. Experimental results on TED-LIUM 2 indicate that either triphone or BPE alignment based weak supervision improves ASR performance over standard CTC auxiliary loss. Moreover, their combination lowers the word error rate further. We also investigate the alternation of the two auxiliary tasks during model training, and additional performance gain is observed. Overall, the proposed techniques result in over 10% relative error rate reduction over a CTC-regularized baseline system.
Weak Alignment Supervision from Hybrid Model Improves End-to-end ASR
Nov 30, 2023



In this paper, we aim to create weak alignment supervision from an existing hybrid system to aid the end-to-end modeling of automatic speech recognition. Towards this end, we use the existing hybrid ASR system to produce triphone alignments of the training audios. We then create a cross-entropy loss at a certain layer of the encoder using the derived alignments. In contrast to the general one-hot cross-entropy losses, here we use a cross-entropy loss with a label smoothing parameter to regularize the supervision. As a comparison, we also conduct the experiments with one-hot cross-entropy losses and CTC losses with loss weighting. The results show that placing the weak alignment supervision with the label smoothing parameter of 0.5 at the third encoder layer outperforms the other two approaches and leads to about 5\% relative WER reduction on the TED-LIUM 2 dataset over the baseline. We see similar improvements when applying the method out-of-the-box on a Tagalog end-to-end ASR system.
Baechi: Fast Device Placement of Machine Learning Graphs
Jan 20, 2023

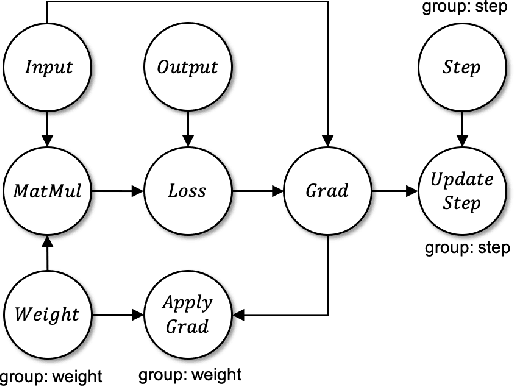

Machine Learning graphs (or models) can be challenging or impossible to train when either devices have limited memory, or models are large. To split the model across devices, learning-based approaches are still popular. While these result in model placements that train fast on data (i.e., low step times), learning-based model-parallelism is time-consuming, taking many hours or days to create a placement plan of operators on devices. We present the Baechi system, the first to adopt an algorithmic approach to the placement problem for running machine learning training graphs on small clusters of memory-constrained devices. We integrate our implementation of Baechi into two popular open-source learning frameworks: TensorFlow and PyTorch. Our experimental results using GPUs show that: (i) Baechi generates placement plans 654 X - 206K X faster than state-of-the-art learning-based approaches, and (ii) Baechi-placed model's step (training) time is comparable to expert placements in PyTorch, and only up to 6.2% worse than expert placements in TensorFlow. We prove mathematically that our two algorithms are within a constant factor of the optimal. Our work shows that compared to learning-based approaches, algorithmic approaches can face different challenges for adaptation to Machine learning systems, but also they offer proven bounds, and significant performance benefits.
Self-Normalized Importance Sampling for Neural Language Modeling
Nov 11, 2021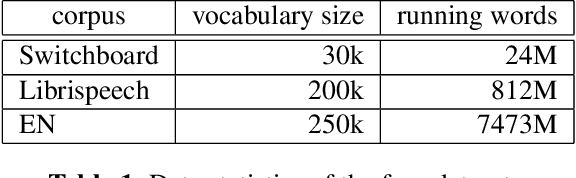
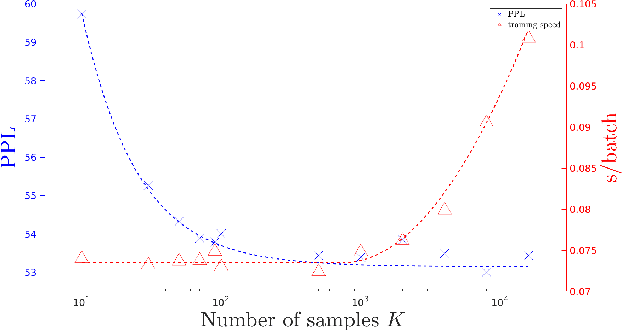
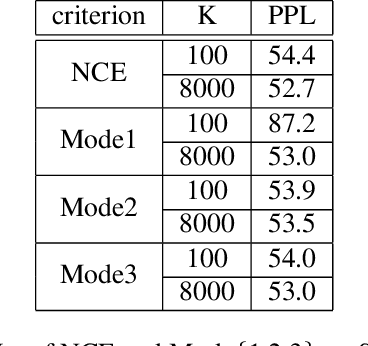

To mitigate the problem of having to traverse over the full vocabulary in the softmax normalization of a neural language model, sampling-based training criteria are proposed and investigated in the context of large vocabulary word-based neural language models. These training criteria typically enjoy the benefit of faster training and testing, at a cost of slightly degraded performance in terms of perplexity and almost no visible drop in word error rate. While noise contrastive estimation is one of the most popular choices, recently we show that other sampling-based criteria can also perform well, as long as an extra correction step is done, where the intended class posterior probability is recovered from the raw model outputs. In this work, we propose self-normalized importance sampling. Compared to our previous work, the criteria considered in this work are self-normalized and there is no need to further conduct a correction step. Compared to noise contrastive estimation, our method is directly comparable in terms of complexity in application. Through self-normalized language model training as well as lattice rescoring experiments, we show that our proposed self-normalized importance sampling is competitive in both research-oriented and production-oriented automatic speech recognition tasks.