 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaechi: Fast Device Placement of Machine Learning Graphs
Jan 20, 2023

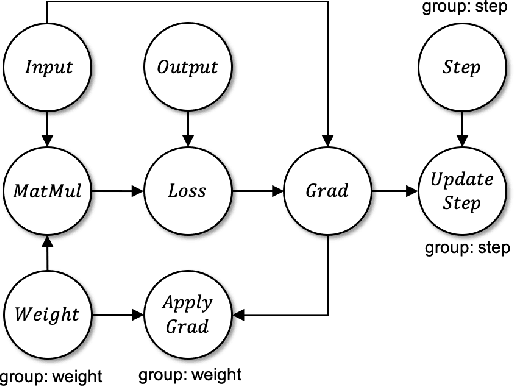

Machine Learning graphs (or models) can be challenging or impossible to train when either devices have limited memory, or models are large. To split the model across devices, learning-based approaches are still popular. While these result in model placements that train fast on data (i.e., low step times), learning-based model-parallelism is time-consuming, taking many hours or days to create a placement plan of operators on devices. We present the Baechi system, the first to adopt an algorithmic approach to the placement problem for running machine learning training graphs on small clusters of memory-constrained devices. We integrate our implementation of Baechi into two popular open-source learning frameworks: TensorFlow and PyTorch. Our experimental results using GPUs show that: (i) Baechi generates placement plans 654 X - 206K X faster than state-of-the-art learning-based approaches, and (ii) Baechi-placed model's step (training) time is comparable to expert placements in PyTorch, and only up to 6.2% worse than expert placements in TensorFlow. We prove mathematically that our two algorithms are within a constant factor of the optimal. Our work shows that compared to learning-based approaches, algorithmic approaches can face different challenges for adaptation to Machine learning systems, but also they offer proven bounds, and significant performance benefits.
CSER: Communication-efficient SGD with Error Reset
Jul 29, 2020
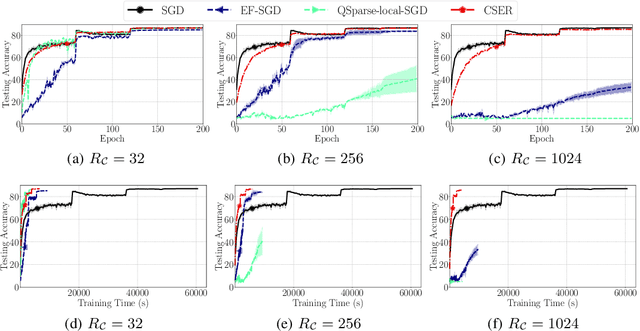

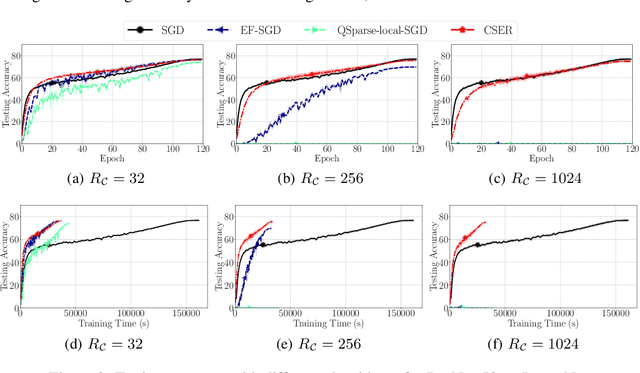
The scalability of Distributed Stochastic Gradient Descent (SGD) is today limited by communication bottlenecks. We propose a novel SGD variant: Communication-efficient SGD with Error Reset, or CSER. The key idea in CSER is first a new technique called "error reset" that adapts arbitrary compressors for SGD, producing bifurcated local models with periodic reset of resulting local residual errors. Second we introduce partial synchronization for both the gradients and the models, leveraging advantages from them. We prove the convergence of CSER for smooth non-convex problems. Empirical results show that when combined with highly aggressive compressors, the CSER algorithms: i) cause no loss of accuracy, and ii) accelerate the training by nearly $10\times$ for CIFAR-100, and by $4.5\times$ for ImageNet.
Local AdaAlter: Communication-Efficient Stochastic Gradient Descent with Adaptive Learning Rates
Nov 20, 2019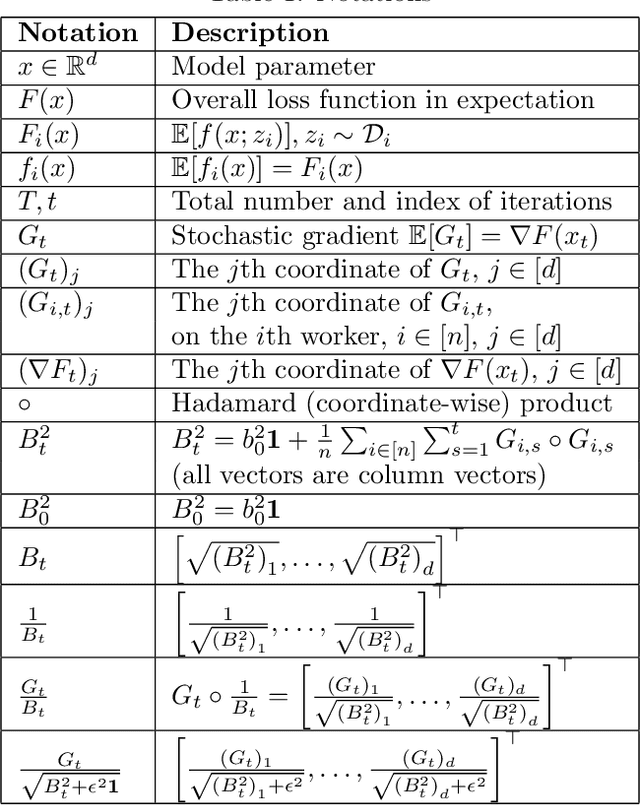
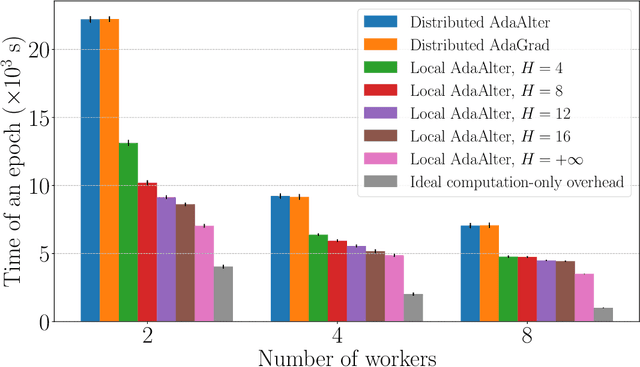
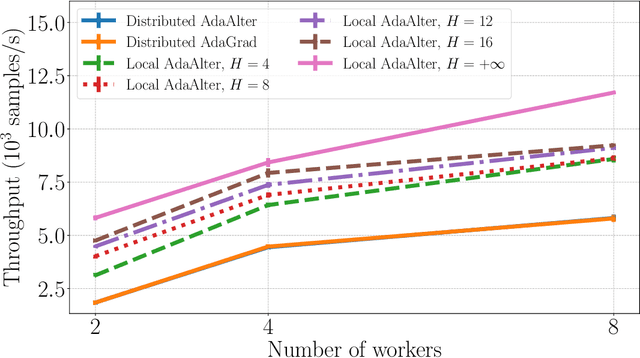
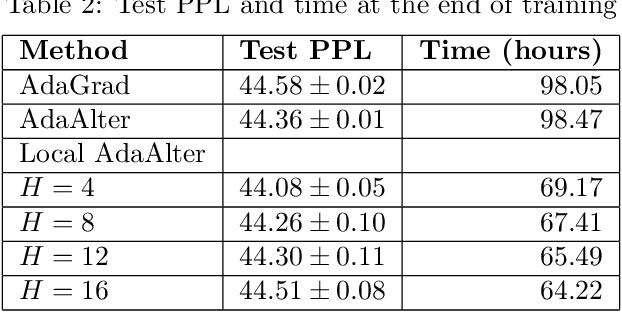
Recent years have witnessed the growth of large-scale distributed machine learning algorithms -- specifically designed to accelerate model training by distributing computation across multiple machines. When scaling distributed training in this way, the communication overhead is often the bottleneck. In this paper, we study the local distributed Stochastic Gradient Descent~(SGD) algorithm, which reduces the communication overhead by decreasing the frequency of synchronization. While SGD with adaptive learning rates is a widely adopted strategy for training neural networks, it remains unknown how to implement adaptive learning rates in local SGD. To this end, we propose a novel SGD variant with reduced communication and adaptive learning rates, with provable convergence. Empirical results show that the proposed algorithm has fast convergence and efficiently reduces the communication overhead.
SLSGD: Secure and Efficient Distributed On-device Machine Learning
Apr 05, 2019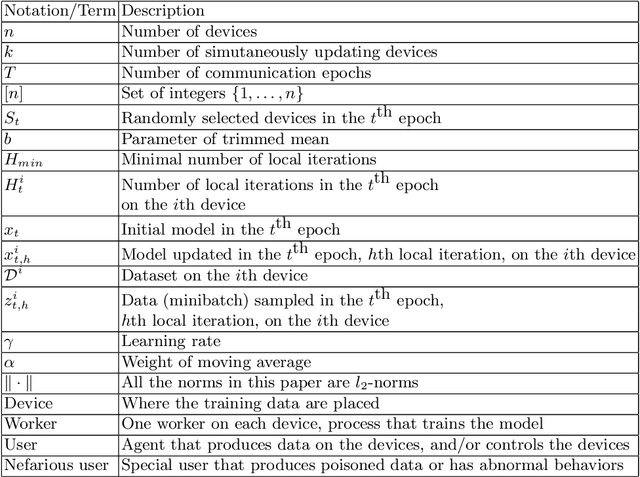
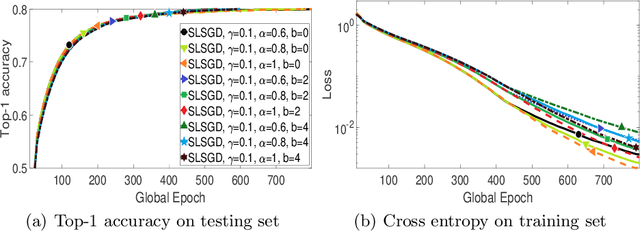
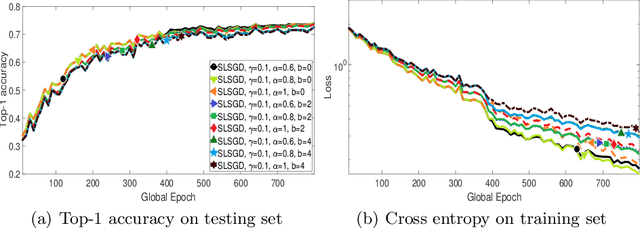
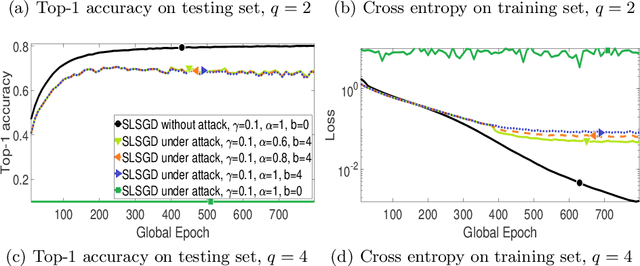
We consider distributed on-device learning with limited communication and security requirements. We propose a new robust distributed optimization algorithm with efficient communication and attack tolerance. The proposed algorithm has provable convergence and robustness under non-IID settings. Empirical results show that the proposed algorithm stabilizes the convergence and tolerates data poisoning on a small number of workers.
Asynchronous Federated Optimization
Mar 13, 2019
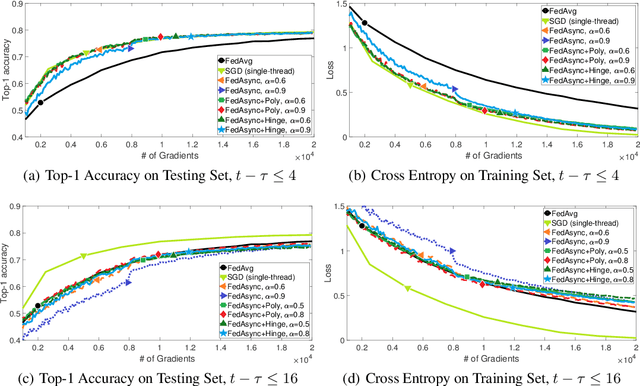
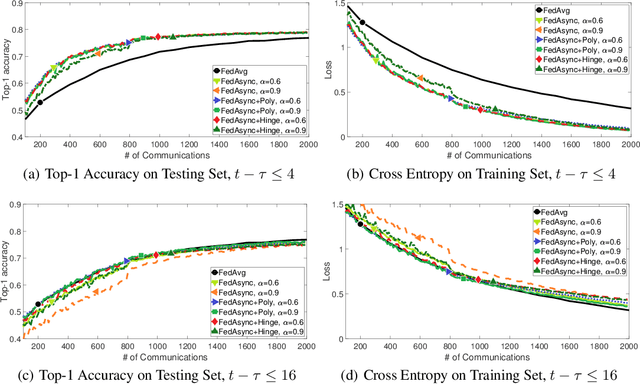
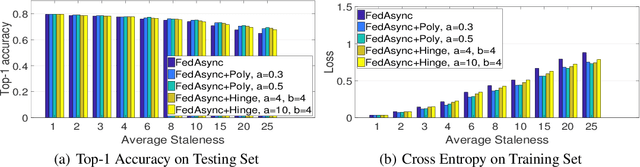
Federated learning enables training on a massive number of edge devices. To improve flexibility and scalability, we propose a new asynchronous federated optimization algorithm. We prove that the proposed approach has near-linear convergence to a global optimum, for both strongly and non-strongly convex problems, as well as a restricted family of non-convex problems. Empirical results show that the proposed algorithm converges fast and tolerates staleness.
Fall of Empires: Breaking Byzantine-tolerant SGD by Inner Product Manipulation
Mar 10, 2019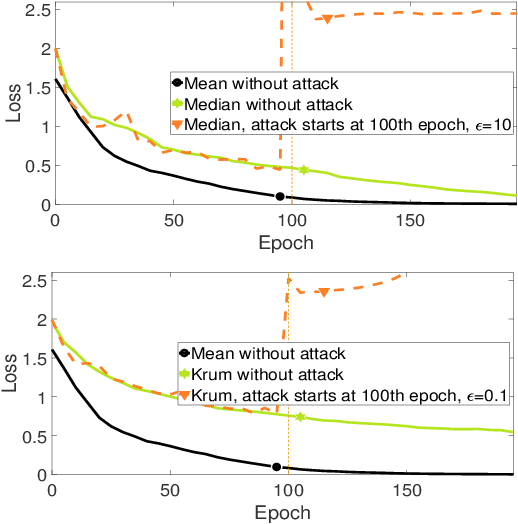
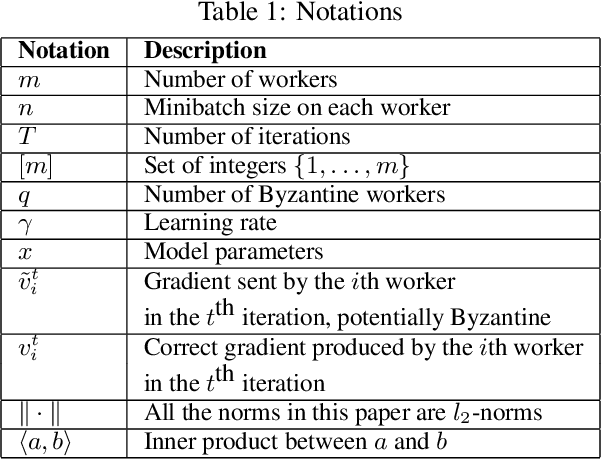
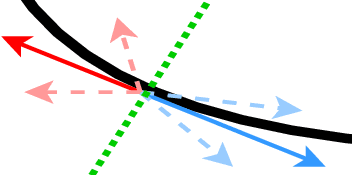

Recently, new defense techniques have been developed to tolerate Byzantine failures for distributed machine learning. The Byzantine model captures workers that behave arbitrarily, including malicious and compromised workers. In this paper, we break two prevailing Byzantine-tolerant techniques. Specifically we show robust aggregation methods for synchronous SGD -- coordinate-wise median and Krum -- can be broken using new attack strategies based on inner product manipulation. We prove our results theoretically, as well as show empirical validation.
Zeno: Byzantine-suspicious stochastic gradient descent
Sep 16, 2018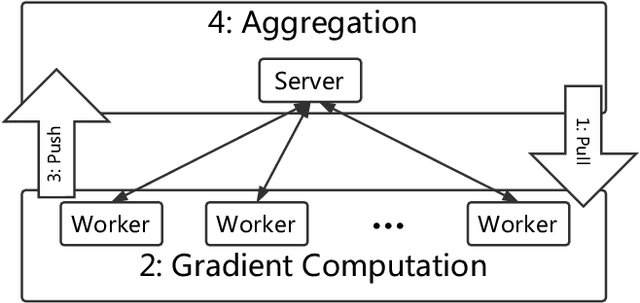
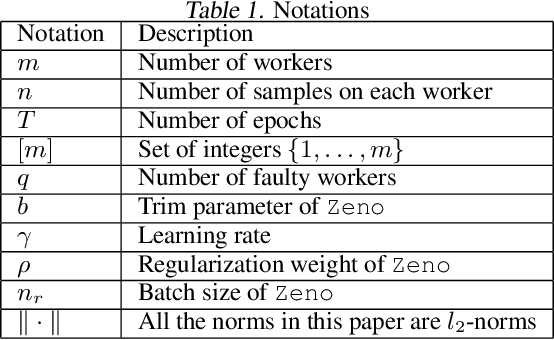
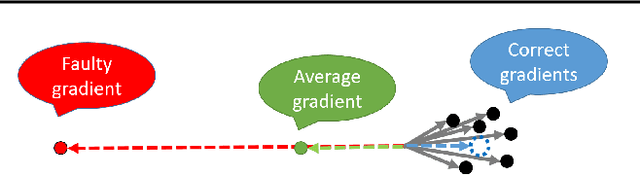
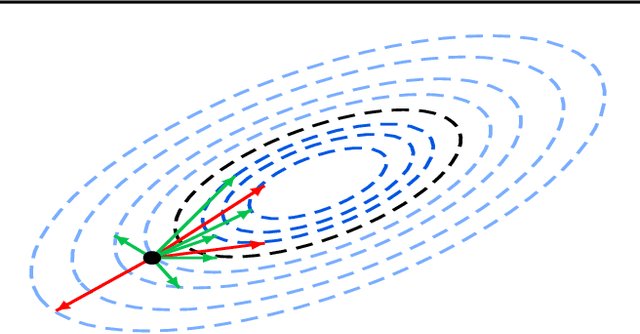
We propose Zeno, a new robust aggregation rule, for distributed synchronous Stochastic Gradient Descent~(SGD) under a general Byzantine failure model. The key idea is to suspect the workers that are potentially malicious, and use a ranking-based preference mechanism. This allows us to generalize beyond past work--in our case, the number of malicious workers can be arbitrarily large, and we use only the weakest assumption on honest workers~(at least one honest worker). We prove the convergence of SGD under these scenarios. Empirical results show that Zeno outperforms existing approaches under various attacks.
Phocas: dimensional Byzantine-resilient stochastic gradient descent
May 23, 2018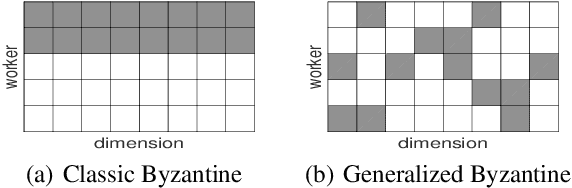
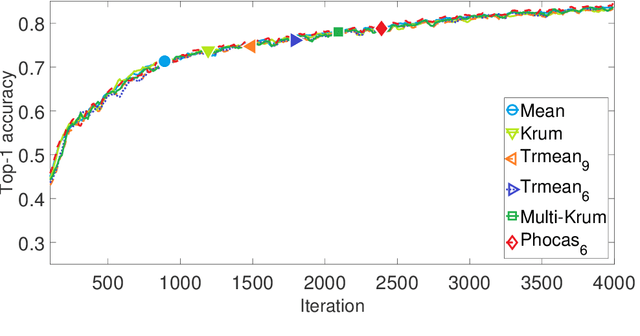
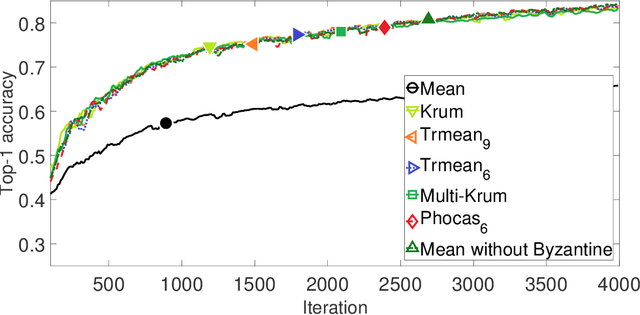
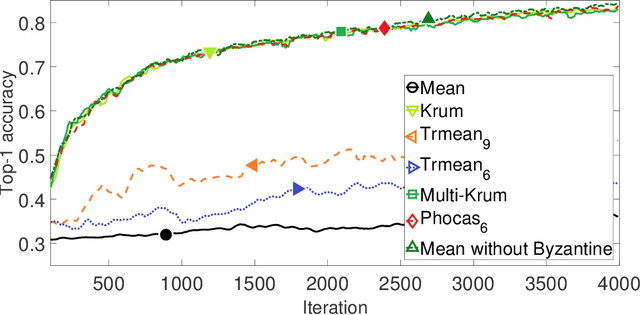
We propose a novel robust aggregation rule for distributed synchronous Stochastic Gradient Descent~(SGD) under a general Byzantine failure model. The attackers can arbitrarily manipulate the data transferred between the servers and the workers in the parameter server~(PS) architecture. We prove the Byzantine resilience of the proposed aggregation rules. Empirical analysis shows that the proposed techniques outperform current approaches for realistic use cases and Byzantine attack scenarios.
Generalized Byzantine-tolerant SGD
Mar 23, 2018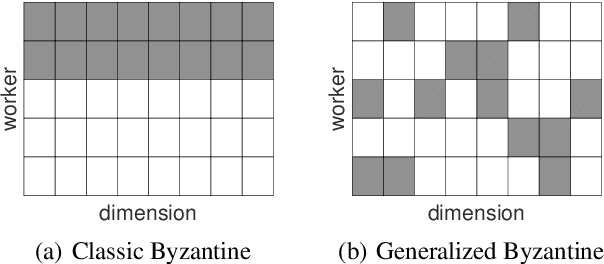
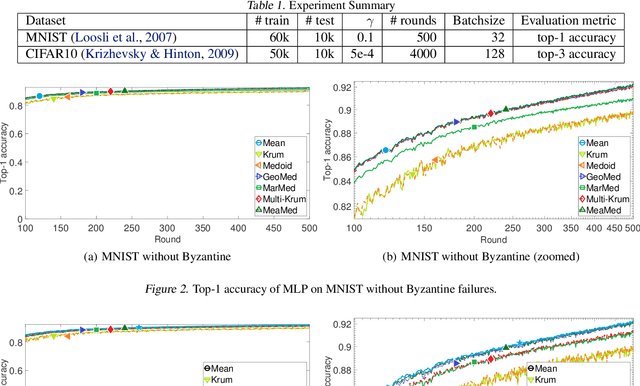
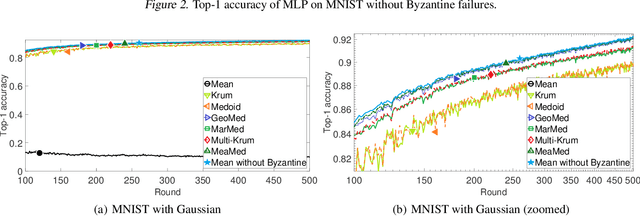
We propose three new robust aggregation rules for distributed synchronous Stochastic Gradient Descent~(SGD) under a general Byzantine failure model. The attackers can arbitrarily manipulate the data transferred between the servers and the workers in the parameter server~(PS) architecture. We prove the Byzantine resilience properties of these aggregation rules. Empirical analysis shows that the proposed techniques outperform current approaches for realistic use cases and Byzantine attack scenarios.