 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal AdaAlter: Communication-Efficient Stochastic Gradient Descent with Adaptive Learning Rates
Paper and Code
Nov 20, 2019
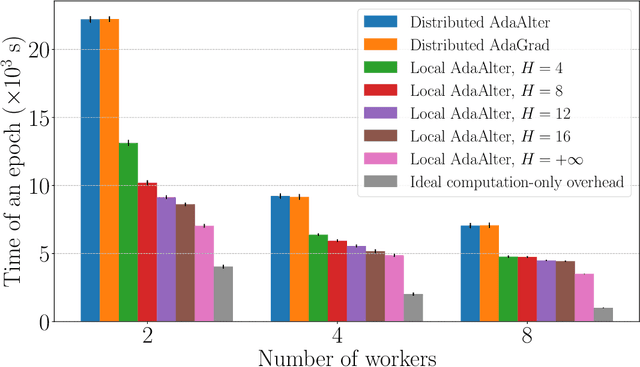
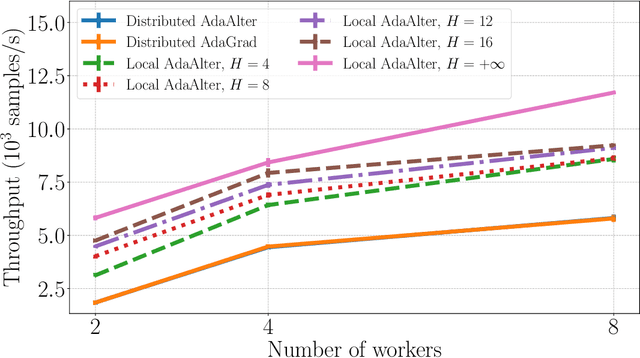
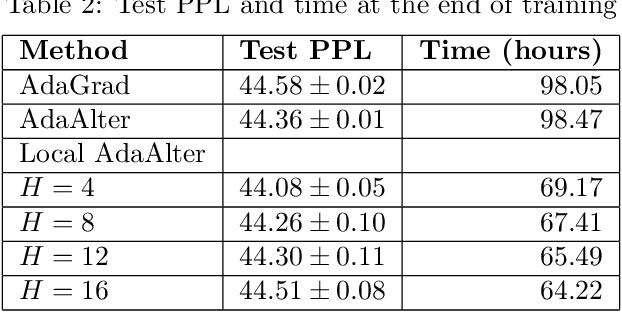
Recent years have witnessed the growth of large-scale distributed machine learning algorithms -- specifically designed to accelerate model training by distributing computation across multiple machines. When scaling distributed training in this way, the communication overhead is often the bottleneck. In this paper, we study the local distributed Stochastic Gradient Descent~(SGD) algorithm, which reduces the communication overhead by decreasing the frequency of synchronization. While SGD with adaptive learning rates is a widely adopted strategy for training neural networks, it remains unknown how to implement adaptive learning rates in local SGD. To this end, we propose a novel SGD variant with reduced communication and adaptive learning rates, with provable convergence. Empirical results show that the proposed algorithm has fast convergence and efficiently reduces the communication overhead.