 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-aware Stopping for Bayesian Optimization
Jul 16, 2025In automated machine learning, scientific discovery, and other applications of Bayesian optimization, deciding when to stop evaluating expensive black-box functions is an important practical consideration. While several adaptive stopping rules have been proposed, in the cost-aware setting they lack guarantees ensuring they stop before incurring excessive function evaluation costs. We propose a cost-aware stopping rule for Bayesian optimization that adapts to varying evaluation costs and is free of heuristic tuning. Our rule is grounded in a theoretical connection to state-of-the-art cost-aware acquisition functions, namely the Pandora's Box Gittins Index (PBGI) and log expected improvement per cost. We prove a theoretical guarantee bounding the expected cumulative evaluation cost incurred by our stopping rule when paired with these two acquisition functions. In experiments on synthetic and empirical tasks, including hyperparameter optimization and neural architecture size search, we show that combining our stopping rule with the PBGI acquisition function consistently matches or outperforms other acquisition-function--stopping-rule pairs in terms of cost-adjusted simple regret, a metric capturing trade-offs between solution quality and cumulative evaluation cost.
Faster Diffusion-based Sampling with Randomized Midpoints: Sequential and Parallel
Jun 03, 2024In recent years, there has been a surge of interest in proving discretization bounds for diffusion models. These works show that for essentially any data distribution, one can approximately sample in polynomial time given a sufficiently accurate estimate of its score functions at different noise levels. In this work, we propose a new discretization scheme for diffusion models inspired by Shen and Lee's randomized midpoint method for log-concave sampling~\cite{ShenL19}. We prove that this approach achieves the best known dimension dependence for sampling from arbitrary smooth distributions in total variation distance ($\widetilde O(d^{5/12})$ compared to $\widetilde O(\sqrt{d})$ from prior work). We also show that our algorithm can be parallelized to run in only $\widetilde O(\log^2 d)$ parallel rounds, constituting the first provable guarantees for parallel sampling with diffusion models. As a byproduct of our methods, for the well-studied problem of log-concave sampling in total variation distance, we give an algorithm and simple analysis achieving dimension dependence $\widetilde O(d^{5/12})$ compared to $\widetilde O(\sqrt{d})$ from prior work.
Baechi: Fast Device Placement of Machine Learning Graphs
Jan 20, 2023

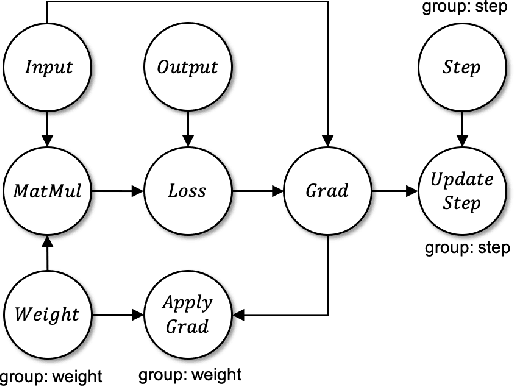

Machine Learning graphs (or models) can be challenging or impossible to train when either devices have limited memory, or models are large. To split the model across devices, learning-based approaches are still popular. While these result in model placements that train fast on data (i.e., low step times), learning-based model-parallelism is time-consuming, taking many hours or days to create a placement plan of operators on devices. We present the Baechi system, the first to adopt an algorithmic approach to the placement problem for running machine learning training graphs on small clusters of memory-constrained devices. We integrate our implementation of Baechi into two popular open-source learning frameworks: TensorFlow and PyTorch. Our experimental results using GPUs show that: (i) Baechi generates placement plans 654 X - 206K X faster than state-of-the-art learning-based approaches, and (ii) Baechi-placed model's step (training) time is comparable to expert placements in PyTorch, and only up to 6.2% worse than expert placements in TensorFlow. We prove mathematically that our two algorithms are within a constant factor of the optimal. Our work shows that compared to learning-based approaches, algorithmic approaches can face different challenges for adaptation to Machine learning systems, but also they offer proven bounds, and significant performance benefits.