 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaechi: Fast Device Placement of Machine Learning Graphs
Paper and Code
Jan 20, 2023

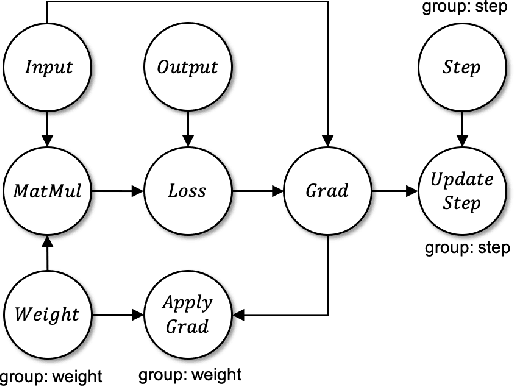

Machine Learning graphs (or models) can be challenging or impossible to train when either devices have limited memory, or models are large. To split the model across devices, learning-based approaches are still popular. While these result in model placements that train fast on data (i.e., low step times), learning-based model-parallelism is time-consuming, taking many hours or days to create a placement plan of operators on devices. We present the Baechi system, the first to adopt an algorithmic approach to the placement problem for running machine learning training graphs on small clusters of memory-constrained devices. We integrate our implementation of Baechi into two popular open-source learning frameworks: TensorFlow and PyTorch. Our experimental results using GPUs show that: (i) Baechi generates placement plans 654 X - 206K X faster than state-of-the-art learning-based approaches, and (ii) Baechi-placed model's step (training) time is comparable to expert placements in PyTorch, and only up to 6.2% worse than expert placements in TensorFlow. We prove mathematically that our two algorithms are within a constant factor of the optimal. Our work shows that compared to learning-based approaches, algorithmic approaches can face different challenges for adaptation to Machine learning systems, but also they offer proven bounds, and significant performance benefits.