 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputation-Utility-Privacy Tradeoffs in Bayesian Estimation
Mar 18, 2026Bayesian methods lie at the heart of modern data science and provide a powerful scaffolding for estimation in data-constrained settings and principled quantification and propagation of uncertainty. Yet in many real-world use cases where these methods are deployed, there is a natural need to preserve the privacy of the individuals whose data is being scrutinized. While a number of works have attempted to approach the problem of differentially private Bayesian estimation through either reasoning about the inherent privacy of the posterior distribution or privatizing off-the-shelf Bayesian methods, these works generally do not come with rigorous utility guarantees beyond low-dimensional settings. In fact, even for the prototypical tasks of Gaussian mean estimation and linear regression, it was unknown how close one could get to the Bayes-optimal error with a private algorithm, even in the simplest case where the unknown parameter comes from a Gaussian prior. In this work, we give the first efficient algorithms for both of these problems that achieve mean-squared error $(1+o(1))\mathrm{OPT}$ and additionally show that both tasks exhibit an intriguing computational-statistical gap. For Bayesian mean estimation, we prove that the excess risk achieved by our method is optimal among all efficient algorithms within the low-degree framework, yet is provably worse than what is achievable by an exponential-time algorithm. For linear regression, we prove a qualitatively similar lower bound. Our algorithms draw upon the privacy-to-robustness framework of arXiv:2212.05015, but with the curious twist that to achieve private Bayes-optimal estimation, we need to design sum-of-squares-based robust estimators for inherently non-robust objects like the empirical mean and OLS estimator. Along the way we also add to the sum-of-squares toolkit a new kind of constraint based on short-flat decompositions.
Stop Training for the Worst: Progressive Unmasking Accelerates Masked Diffusion Training
Feb 10, 2026Masked Diffusion Models (MDMs) have emerged as a promising approach for generative modeling in discrete spaces. By generating sequences in any order and allowing for parallel decoding, they enable fast inference and strong performance on non-causal tasks. However, this flexibility comes with a training complexity trade-off: MDMs train on an exponentially large set of masking patterns, which is not only computationally expensive, but also creates a train--test mismatch between the random masks used in training and the highly structured masks induced by inference-time unmasking. In this work, we propose Progressive UnMAsking (PUMA), a simple modification of the forward masking process that aligns training-time and inference-time masking patterns, thereby focusing optimization on inference-aligned masks and speeding up training. Empirically, PUMA speeds up pretraining at the 125M scale by $\approx 2.5\times$ and offers complementary advantages on top of common recipes like autoregressive initialization. We open-source our codebase at https://github.com/JaeyeonKim01/PUMA.
High-accuracy and dimension-free sampling with diffusions
Jan 15, 2026Diffusion models have shown remarkable empirical success in sampling from rich multi-modal distributions. Their inference relies on numerically solving a certain differential equation. This differential equation cannot be solved in closed form, and its resolution via discretization typically requires many small iterations to produce \emph{high-quality} samples. More precisely, prior works have shown that the iteration complexity of discretization methods for diffusion models scales polynomially in the ambient dimension and the inverse accuracy $1/\varepsilon$. In this work, we propose a new solver for diffusion models relying on a subtle interplay between low-degree approximation and the collocation method (Lee, Song, Vempala 2018), and we prove that its iteration complexity scales \emph{polylogarithmically} in $1/\varepsilon$, yielding the first ``high-accuracy'' guarantee for a diffusion-based sampler that only uses (approximate) access to the scores of the data distribution. In addition, our bound does not depend explicitly on the ambient dimension; more precisely, the dimension affects the complexity of our solver through the \emph{effective radius} of the support of the target distribution only.
Sublinear iterations can suffice even for DDPMs
Nov 06, 2025SDE-based methods such as denoising diffusion probabilistic models (DDPMs) have shown remarkable success in real-world sample generation tasks. Prior analyses of DDPMs have been focused on the exponential Euler discretization, showing guarantees that generally depend at least linearly on the dimension or initial Fisher information. Inspired by works in log-concave sampling (Shen and Lee, 2019), we analyze an integrator -- the denoising diffusion randomized midpoint method (DDRaM) -- that leverages an additional randomized midpoint to better approximate the SDE. Using a recently-developed analytic framework called the "shifted composition rule", we show that this algorithm enjoys favorable discretization properties under appropriate smoothness assumptions, with sublinear $\widetilde{O}(\sqrt{d})$ score evaluations needed to ensure convergence. This is the first sublinear complexity bound for pure DDPM sampling -- prior works which obtained such bounds worked instead with ODE-based sampling and had to make modifications to the sampler which deviate from how they are used in practice. We also provide experimental validation of the advantages of our method, showing that it performs well in practice with pre-trained image synthesis models.
Optimal Inference Schedules for Masked Diffusion Models
Nov 06, 2025A major bottleneck of standard auto-regressive large language models is that their inference process is inherently sequential, resulting in very long and costly inference times. To circumvent this, practitioners proposed a class of language models called diffusion language models, of which the masked diffusion model (MDM) is the most successful. The MDM is able to sample tokens out-of-order and, ostensibly, many tokens at once and in parallel. However, there is very limited rigorous understanding of how much parallel sampling these models can perform without noticeable degradation in their sampling performance. Prior work of Li and Cai obtained some preliminary bounds, but these are not tight for many natural classes of distributions. In this work, we give a new, exact characterization of the expected divergence between the true distribution and the sampled distribution, for any distribution and any unmasking schedule for the sampler, showing an elegant connection to the theory of univariate function approximation. By leveraging this connection, we then attain a number of novel lower and upper bounds for this problem. While the connection to function approximation in principle gives the optimal unmasking schedule for any distribution, we show that it is in general impossible to compete with it without strong a priori knowledge of the distribution, even in seemingly benign settings. However, we also demonstrate new upper bounds and new sampling schedules in terms of well-studied information-theoretic properties of the base distribution, namely, its total correlation and dual total correlation, which show that in some natural settings, one can sample in $O(log n)$ steps without any visible loss in performance, where $n$ is the total sequence length.
Selective Underfitting in Diffusion Models
Oct 01, 2025Diffusion models have emerged as the principal paradigm for generative modeling across various domains. During training, they learn the score function, which in turn is used to generate samples at inference. They raise a basic yet unsolved question: which score do they actually learn? In principle, a diffusion model that matches the empirical score in the entire data space would simply reproduce the training data, failing to generate novel samples. Recent work addresses this question by arguing that diffusion models underfit the empirical score due to training-time inductive biases. In this work, we refine this perspective, introducing the notion of selective underfitting: instead of underfitting the score everywhere, better diffusion models more accurately approximate the score in certain regions of input space, while underfitting it in others. We characterize these regions and design empirical interventions to validate our perspective. Our results establish that selective underfitting is essential for understanding diffusion models, yielding new, testable insights into their generalization and generative performance.
Fine-Tuning Masked Diffusion for Provable Self-Correction
Oct 01, 2025A natural desideratum for generative models is self-correction--detecting and revising low-quality tokens at inference. While Masked Diffusion Models (MDMs) have emerged as a promising approach for generative modeling in discrete spaces, their capacity for self-correction remains poorly understood. Prior attempts to incorporate self-correction into MDMs either require overhauling MDM architectures/training or rely on imprecise proxies for token quality, limiting their applicability. Motivated by this, we introduce PRISM--Plug-in Remasking for Inference-time Self-correction of Masked Diffusions--a lightweight, model-agnostic approach that applies to any pretrained MDM. Theoretically, PRISM defines a self-correction loss that provably learns per-token quality scores, without RL or a verifier. These quality scores are computed in the same forward pass with MDM and used to detect low-quality tokens. Empirically, PRISM advances MDM inference across domains and scales: Sudoku; unconditional text (170M); and code with LLaDA (8B).
ReGuidance: A Simple Diffusion Wrapper for Boosting Sample Quality on Hard Inverse Problems
Jun 12, 2025There has been a flurry of activity around using pretrained diffusion models as informed data priors for solving inverse problems, and more generally around steering these models using reward models. Training-free methods like diffusion posterior sampling (DPS) and its many variants have offered flexible heuristic algorithms for these tasks, but when the reward is not informative enough, e.g., in hard inverse problems with low signal-to-noise ratio, these techniques veer off the data manifold, failing to produce realistic outputs. In this work, we devise a simple wrapper, ReGuidance, for boosting both the sample realism and reward achieved by these methods. Given a candidate solution $\hat{x}$ produced by an algorithm of the user's choice, we propose inverting the solution by running the unconditional probability flow ODE in reverse starting from $\hat{x}$, and then using the resulting latent as an initialization for DPS. We evaluate our wrapper on hard inverse problems like large box in-painting and super-resolution with high upscaling. Whereas state-of-the-art baselines visibly fail, we find that applying our wrapper on top of these baselines significantly boosts sample quality and measurement consistency. We complement these findings with theory proving that on certain multimodal data distributions, ReGuidance simultaneously boosts the reward and brings the candidate solution closer to the data manifold. To our knowledge, this constitutes the first rigorous algorithmic guarantee for DPS.
Information-Computation Gaps in Quantum Learning via Low-Degree Likelihood
May 28, 2025In a variety of physically relevant settings for learning from quantum data, designing protocols that can computationally efficiently extract information remains largely an art, and there are important cases where we believe this to be impossible, that is, where there is an information-computation gap. While there is a large array of tools in the classical literature for giving evidence for average-case hardness of statistical inference problems, the corresponding tools in the quantum literature are far more limited. One such framework in the classical literature, the low-degree method, makes predictions about hardness of inference problems based on the failure of estimators given by low-degree polynomials. In this work, we extend this framework to the quantum setting. We establish a general connection between state designs and low-degree hardness. We use this to obtain the first information-computation gaps for learning Gibbs states of random, sparse, non-local Hamiltonians. We also use it to prove hardness for learning random shallow quantum circuit states in a challenging model where states can be measured in adaptively chosen bases. To our knowledge, the ability to model adaptivity within the low-degree framework was open even in classical settings. In addition, we also obtain a low-degree hardness result for quantum error mitigation against strategies with single-qubit measurements. We define a new quantum generalization of the planted biclique problem and identify the threshold at which this problem becomes computationally hard for protocols that perform local measurements. Interestingly, the complexity landscape for this problem shifts when going from local measurements to more entangled single-copy measurements. We show average-case hardness for the "standard" variant of Learning Stabilizers with Noise and for agnostically learning product states.
S4S: Solving for a Diffusion Model Solver
Feb 24, 2025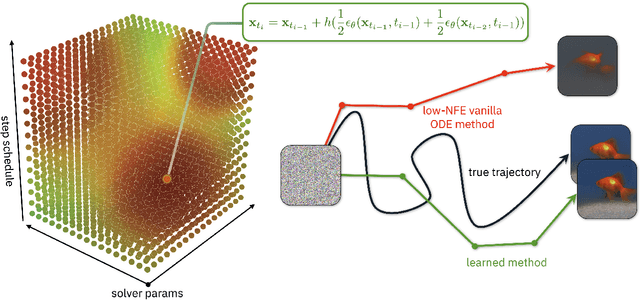


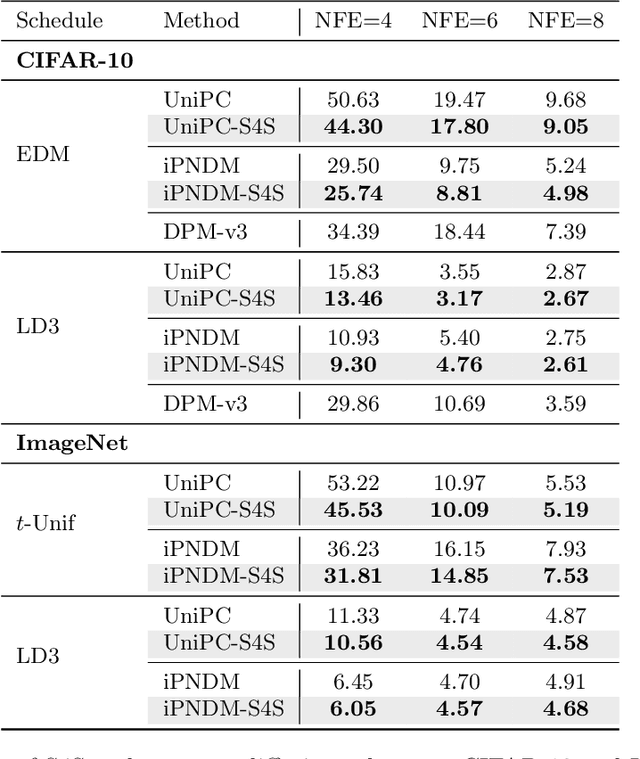
Diffusion models (DMs) create samples from a data distribution by starting from random noise and iteratively solving a reverse-time ordinary differential equation (ODE). Because each step in the iterative solution requires an expensive neural function evaluation (NFE), there has been significant interest in approximately solving these diffusion ODEs with only a few NFEs without modifying the underlying model. However, in the few NFE regime, we observe that tracking the true ODE evolution is fundamentally impossible using traditional ODE solvers. In this work, we propose a new method that learns a good solver for the DM, which we call Solving for the Solver (S4S). S4S directly optimizes a solver to obtain good generation quality by learning to match the output of a strong teacher solver. We evaluate S4S on six different pre-trained DMs, including pixel-space and latent-space DMs for both conditional and unconditional sampling. In all settings, S4S uniformly improves the sample quality relative to traditional ODE solvers. Moreover, our method is lightweight, data-free, and can be plugged in black-box on top of any discretization schedule or architecture to improve performance. Building on top of this, we also propose S4S-Alt, which optimizes both the solver and the discretization schedule. By exploiting the full design space of DM solvers, with 5 NFEs, we achieve an FID of 3.73 on CIFAR10 and 13.26 on MS-COCO, representing a $1.5\times$ improvement over previous training-free ODE methods.