 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlink of an eye: a simple theory for feature localization in generative models
Feb 02, 2025Large language models (LLMs) can exhibit undesirable and unexpected behavior in the blink of an eye. In a recent Anthropic demo, Claude switched from coding to Googling pictures of Yellowstone, and these sudden shifts in behavior have also been observed in reasoning patterns and jailbreaks. This phenomenon is not unique to autoregressive models: in diffusion models, key features of the final output are decided in narrow ``critical windows'' of the generation process. In this work we develop a simple, unifying theory to explain this phenomenon. We show that it emerges generically as the generation process localizes to a sub-population of the distribution it models. While critical windows have been studied at length in diffusion models, existing theory heavily relies on strong distributional assumptions and the particulars of Gaussian diffusion. In contrast to existing work our theory (1) applies to autoregressive and diffusion models; (2) makes no distributional assumptions; (3) quantitatively improves previous bounds even when specialized to diffusions; and (4) requires basic tools and no stochastic calculus or statistical physics-based machinery. We also identify an intriguing connection to the all-or-nothing phenomenon from statistical inference. Finally, we validate our predictions empirically for LLMs and find that critical windows often coincide with failures in problem solving for various math and reasoning benchmarks.
Bias Begets Bias: The Impact of Biased Embeddings on Diffusion Models
Sep 15, 2024With the growing adoption of Text-to-Image (TTI) systems, the social biases of these models have come under increased scrutiny. Herein we conduct a systematic investigation of one such source of bias for diffusion models: embedding spaces. First, because traditional classifier-based fairness definitions require true labels not present in generative modeling, we propose statistical group fairness criteria based on a model's internal representation of the world. Using these definitions, we demonstrate theoretically and empirically that an unbiased text embedding space for input prompts is a necessary condition for representationally balanced diffusion models, meaning the distribution of generated images satisfy diversity requirements with respect to protected attributes. Next, we investigate the impact of biased embeddings on evaluating the alignment between generated images and prompts, a process which is commonly used to assess diffusion models. We find that biased multimodal embeddings like CLIP can result in lower alignment scores for representationally balanced TTI models, thus rewarding unfair behavior. Finally, we develop a theoretical framework through which biases in alignment evaluation can be studied and propose bias mitigation methods. By specifically adapting the perspective of embedding spaces, we establish new fairness conditions for diffusion model development and evaluation.
Critical windows: non-asymptotic theory for feature emergence in diffusion models
Mar 03, 2024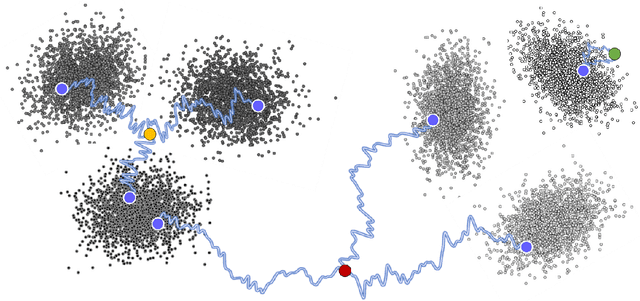
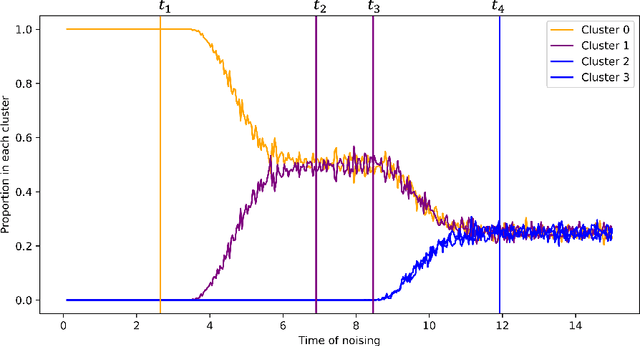

We develop theory to understand an intriguing property of diffusion models for image generation that we term critical windows. Empirically, it has been observed that there are narrow time intervals in sampling during which particular features of the final image emerge, e.g. the image class or background color (Ho et al., 2020b; Georgiev et al., 2023; Raya & Ambrogioni, 2023; Sclocchi et al., 2024; Biroli et al., 2024). While this is advantageous for interpretability as it implies one can localize properties of the generation to a small segment of the trajectory, it seems at odds with the continuous nature of the diffusion. We propose a formal framework for studying these windows and show that for data coming from a mixture of strongly log-concave densities, these windows can be provably bounded in terms of certain measures of inter- and intra-group separation. We also instantiate these bounds for concrete examples like well-conditioned Gaussian mixtures. Finally, we use our bounds to give a rigorous interpretation of diffusion models as hierarchical samplers that progressively "decide" output features over a discrete sequence of times. We validate our bounds with synthetic experiments. Additionally, preliminary experiments on Stable Diffusion suggest critical windows may serve as a useful tool for diagnosing fairness and privacy violations in real-world diffusion models.
Pandora's White-Box: Increased Training Data Leakage in Open LLMs
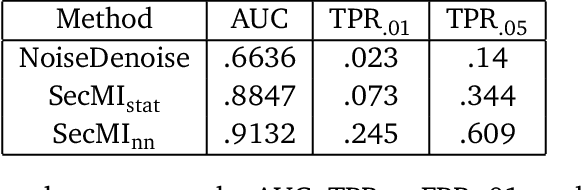
Feb 26, 2024In this paper we undertake a systematic study of privacy attacks against open source Large Language Models (LLMs), where an adversary has access to either the model weights, gradients, or losses, and tries to exploit them to learn something about the underlying training data. Our headline results are the first membership inference attacks (MIAs) against pre-trained LLMs that are able to simultaneously achieve high TPRs and low FPRs, and a pipeline showing that over $50\%$ (!) of the fine-tuning dataset can be extracted from a fine-tuned LLM in natural settings. We consider varying degrees of access to the underlying model, customization of the language model, and resources available to the attacker. In the pre-trained setting, we propose three new white-box MIAs: an attack based on the gradient norm, a supervised neural network classifier, and a single step loss ratio attack. All outperform existing black-box baselines, and our supervised attack closes the gap between MIA attack success against LLMs and other types of models. In fine-tuning, we find that given access to the loss of the fine-tuned and base models, a fine-tuned loss ratio attack FLoRA is able to achieve near perfect MIA peformance. We then leverage these MIAs to extract fine-tuning data from fine-tuned language models. We find that the pipeline of generating from fine-tuned models prompted with a small snippet of the prefix of each training example, followed by using FLoRa to select the most likely training sample, succeeds the majority of the fine-tuning dataset after only $3$ epochs of fine-tuning. Taken together, these findings show that highly effective MIAs are available in almost all LLM training settings, and highlight that great care must be taken before LLMs are fine-tuned on highly sensitive data and then deployed.
MoPe: Model Perturbation-based Privacy Attacks on Language Models
Oct 22, 2023Recent work has shown that Large Language Models (LLMs) can unintentionally leak sensitive information present in their training data. In this paper, we present Model Perturbations (MoPe), a new method to identify with high confidence if a given text is in the training data of a pre-trained language model, given white-box access to the models parameters. MoPe adds noise to the model in parameter space and measures the drop in log-likelihood at a given point $x$, a statistic we show approximates the trace of the Hessian matrix with respect to model parameters. Across language models ranging from $70$M to $12$B parameters, we show that MoPe is more effective than existing loss-based attacks and recently proposed perturbation-based methods. We also examine the role of training point order and model size in attack success, and empirically demonstrate that MoPe accurately approximate the trace of the Hessian in practice. Our results show that the loss of a point alone is insufficient to determine extractability -- there are training points we can recover using our method that have average loss. This casts some doubt on prior works that use the loss of a point as evidence of memorization or unlearning.