 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-optimal high-precision shadow tomography with few-copy measurements: A metrological approach
Feb 04, 2026We study the sample complexity of shadow tomography in the high-precision regime under realistic measurement constraints. Given an unknown $d$-dimensional quantum state $ρ$ and a known set of observables $\{O_i\}_{i=1}^m$, the goal is to estimate expectation values $\{\mathrm{tr}(O_iρ)\}_{i=1}^m$ to accuracy $ε$ in $L_p$-norm, using possibly adaptive measurements that act on $O(\mathrm{polylog}(d))$ number of copies of $ρ$ at a time. We focus on the regime where $ε$ is below an instance-dependent threshold. Our main contribution is an instance-optimal characterization of the sample complexity as $\tildeΘ(Γ_p/ε^2)$, where $Γ_p$ is a function of $\{O_i\}_{i=1}^m$ defined via an optimization formula involving the inverse Fisher information matrix. Previously, tight bounds were known only in special cases, e.g. Pauli shadow tomography with $L_\infty$-norm error. Concretely, we first analyze a simpler oblivious variant where the goal is to estimate an observable of the form $\sum_{i=1}^m α_i O_i$ with $\|α\|_q = 1$ (where $q$ is dual to $p$) revealed after the measurement. For single-copy measurements, we obtain a sample complexity of $Θ(Γ^{\mathrm{ob}}_p/ε^2)$. We then show $\tildeΘ(Γ_p/ε^2)$ is necessary and sufficient for the original problem, with the lower bound applying to unbiased, bounded estimators. Our upper bounds rely on a two-step algorithm combining coarse tomography with local estimation. Notably, $Γ^{\mathrm{ob}}_\infty = Γ_\infty$. In both cases, allowing $c$-copy measurements improves the sample complexity by at most $Ω(1/c)$. Our results establish a quantitative correspondence between quantum learning and metrology, unifying asymptotic metrological limits with finite-sample learning guarantees.
Noisy Quantum Learning Theory
Dec 11, 2025We develop a framework for learning from noisy quantum experiments, focusing on fault-tolerant devices accessing uncharacterized systems through noisy couplings. Our starting point is the complexity class $\textsf{NBQP}$ ("noisy BQP"), modeling noisy fault-tolerant quantum computers that cannot, in general, error-correct the oracle systems they query. Using this class, we show that for natural oracle problems, noise can eliminate exponential quantum learning advantages of ideal noiseless learners while preserving a superpolynomial gap between NISQ and fault-tolerant devices. Beyond oracle separations, we study concrete noisy learning tasks. For purity testing, the exponential two-copy advantage collapses under a single application of local depolarizing noise. Nevertheless, we identify a setting motivated by AdS/CFT in which noise-resilient structure restores a quantum learning advantage in a noisy regime. We then analyze noisy Pauli shadow tomography, deriving lower bounds that characterize how instance size, quantum memory, and noise control sample complexity, and design algorithms with parametrically similar scalings. Together, our results show that the Bell-basis and SWAP-test primitives underlying most exponential quantum learning advantages are fundamentally fragile to noise unless the experimental system has latent noise-robust structure. Thus, realizing meaningful quantum advantages in future experiments will require understanding how noise-robust physical properties interface with available algorithmic techniques.
Instance-Optimal Matrix Multiplicative Weight Update and Its Quantum Applications
Sep 10, 2025The Matrix Multiplicative Weight Update (MMWU) is a seminal online learning algorithm with numerous applications. Applied to the matrix version of the Learning from Expert Advice (LEA) problem on the $d$-dimensional spectraplex, it is well known that MMWU achieves the minimax-optimal regret bound of $O(\sqrt{T\log d})$, where $T$ is the time horizon. In this paper, we present an improved algorithm achieving the instance-optimal regret bound of $O(\sqrt{T\cdot S(X||d^{-1}I_d)})$, where $X$ is the comparator in the regret, $I_d$ is the identity matrix, and $S(\cdot||\cdot)$ denotes the quantum relative entropy. Furthermore, our algorithm has the same computational complexity as MMWU, indicating that the improvement in the regret bound is ``free''. Technically, we first develop a general potential-based framework for matrix LEA, with MMWU being its special case induced by the standard exponential potential. Then, the crux of our analysis is a new ``one-sided'' Jensen's trace inequality built on a Laplace transform technique, which allows the application of general potential functions beyond exponential to matrix LEA. Our algorithm is finally induced by an optimal potential function from the vector LEA problem, based on the imaginary error function. Complementing the above, we provide a memory lower bound for matrix LEA, and explore the applications of our algorithm in quantum learning theory. We show that it outperforms the state of the art for learning quantum states corrupted by depolarization noise, random quantum states, and Gibbs states. In addition, applying our algorithm to linearized convex losses enables predicting nonlinear quantum properties, such as purity, quantum virtual cooling, and R\'{e}nyi-$2$ correlation.
Information-Computation Gaps in Quantum Learning via Low-Degree Likelihood
May 28, 2025In a variety of physically relevant settings for learning from quantum data, designing protocols that can computationally efficiently extract information remains largely an art, and there are important cases where we believe this to be impossible, that is, where there is an information-computation gap. While there is a large array of tools in the classical literature for giving evidence for average-case hardness of statistical inference problems, the corresponding tools in the quantum literature are far more limited. One such framework in the classical literature, the low-degree method, makes predictions about hardness of inference problems based on the failure of estimators given by low-degree polynomials. In this work, we extend this framework to the quantum setting. We establish a general connection between state designs and low-degree hardness. We use this to obtain the first information-computation gaps for learning Gibbs states of random, sparse, non-local Hamiltonians. We also use it to prove hardness for learning random shallow quantum circuit states in a challenging model where states can be measured in adaptively chosen bases. To our knowledge, the ability to model adaptivity within the low-degree framework was open even in classical settings. In addition, we also obtain a low-degree hardness result for quantum error mitigation against strategies with single-qubit measurements. We define a new quantum generalization of the planted biclique problem and identify the threshold at which this problem becomes computationally hard for protocols that perform local measurements. Interestingly, the complexity landscape for this problem shifts when going from local measurements to more entangled single-copy measurements. We show average-case hardness for the "standard" variant of Learning Stabilizers with Noise and for agnostically learning product states.
Ansatz-free Hamiltonian learning with Heisenberg-limited scaling
Feb 17, 2025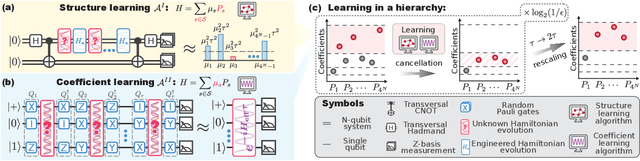
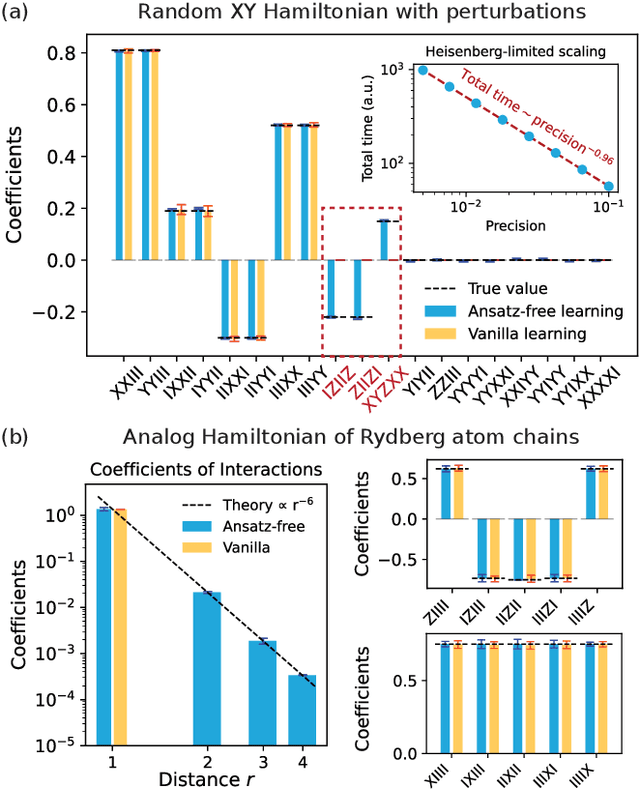
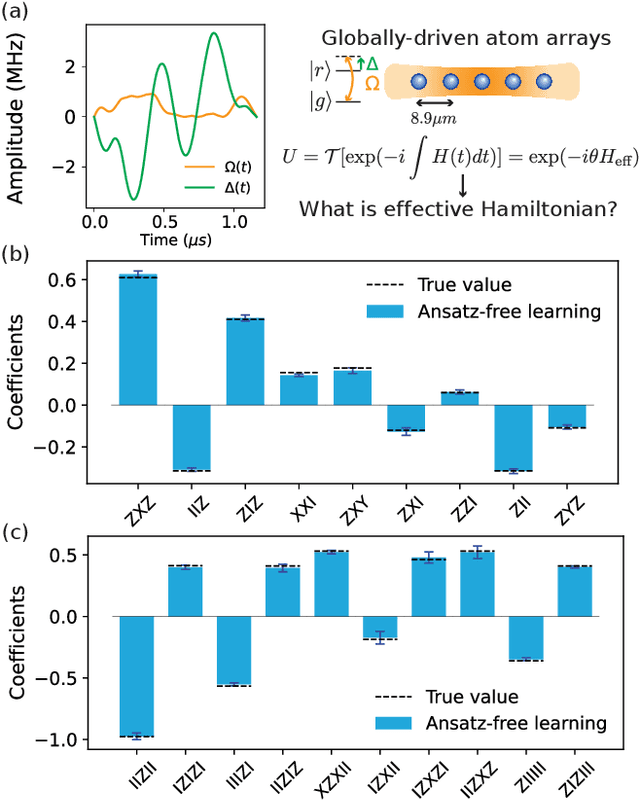

Learning the unknown interactions that govern a quantum system is crucial for quantum information processing, device benchmarking, and quantum sensing. The problem, known as Hamiltonian learning, is well understood under the assumption that interactions are local, but this assumption may not hold for arbitrary Hamiltonians. Previous methods all require high-order inverse polynomial dependency with precision, unable to surpass the standard quantum limit and reach the gold standard Heisenberg-limited scaling. Whether Heisenberg-limited Hamiltonian learning is possible without prior assumptions about the interaction structures, a challenge we term \emph{ansatz-free Hamiltonian learning}, remains an open question. In this work, we present a quantum algorithm to learn arbitrary sparse Hamiltonians without any structure constraints using only black-box queries of the system's real-time evolution and minimal digital controls to attain Heisenberg-limited scaling in estimation error. Our method is also resilient to state-preparation-and-measurement errors, enhancing its practical feasibility. Moreover, we establish a fundamental trade-off between total evolution time and quantum control on learning arbitrary interactions, revealing the intrinsic interplay between controllability and total evolution time complexity for any learning algorithm. These results pave the way for further exploration into Heisenberg-limited Hamiltonian learning in complex quantum systems under minimal assumptions, potentially enabling new benchmarking and verification protocols.
Adaptivity can help exponentially for shadow tomography
Dec 26, 2024In recent years there has been significant interest in understanding the statistical complexity of learning from quantum data under the constraint that one can only make unentangled measurements. While a key challenge in establishing tight lower bounds in this setting is to deal with the fact that the measurements can be chosen in an adaptive fashion, a recurring theme has been that adaptivity offers little advantage over more straightforward, nonadaptive protocols. In this note, we offer a counterpoint to this. We show that for the basic task of shadow tomography, protocols that use adaptively chosen two-copy measurements can be exponentially more sample-efficient than any protocol that uses nonadaptive two-copy measurements.
On the sample complexity of purity and inner product estimation
Oct 16, 2024We study the sample complexity of the prototypical tasks quantum purity estimation and quantum inner product estimation. In purity estimation, we are to estimate $tr(\rho^2)$ of an unknown quantum state $\rho$ to additive error $\epsilon$. Meanwhile, for quantum inner product estimation, Alice and Bob are to estimate $tr(\rho\sigma)$ to additive error $\epsilon$ given copies of unknown quantum state $\rho$ and $\sigma$ using classical communication and restricted quantum communication. In this paper, we show a strong connection between the sample complexity of purity estimation with bounded quantum memory and inner product estimation with bounded quantum communication and unentangled measurements. We propose a protocol that solves quantum inner product estimation with $k$-qubit one-way quantum communication and unentangled local measurements using $O(median\{1/\epsilon^2,2^{n/2}/\epsilon,2^{n-k}/\epsilon^2\})$ copies of $\rho$ and $\sigma$. Our protocol can be modified to estimate the purity of an unknown quantum state $\rho$ using $k$-qubit quantum memory with the same complexity. We prove that arbitrary protocols with $k$-qubit quantum memory that estimate purity to error $\epsilon$ require $\Omega(median\{1/\epsilon^2,2^{n/2}/\sqrt{\epsilon},2^{n-k}/\epsilon^2\})$ copies of $\rho$. This indicates the same lower bound for quantum inner product estimation with one-way $k$-qubit quantum communication and classical communication, and unentangled local measurements. For purity estimation, we further improve the lower bound to $\Omega(\max\{1/\epsilon^2,2^{n/2}/\epsilon\})$ for any protocols using an identical single-copy projection-valued measurement. Additionally, we investigate a decisional variant of quantum distributed inner product estimation without quantum communication for mixed state and provide a lower bound on the sample complexity.
Stabilizer bootstrapping: A recipe for efficient agnostic tomography and magic estimation
Aug 13, 2024We study the task of agnostic tomography: given copies of an unknown $n$-qubit state $\rho$ which has fidelity $\tau$ with some state in a given class $C$, find a state which has fidelity $\ge \tau - \epsilon$ with $\rho$. We give a new framework, stabilizer bootstrapping, for designing computationally efficient protocols for this task, and use this to get new agnostic tomography protocols for the following classes: Stabilizer states: We give a protocol that runs in time $\mathrm{poly}(n,1/\epsilon)\cdot (1/\tau)^{O(\log(1/\tau))}$, answering an open question posed by Grewal, Iyer, Kretschmer, Liang [40] and Anshu and Arunachalam [6]. Previous protocols ran in time $\mathrm{exp}(\Theta(n))$ or required $\tau>\cos^2(\pi/8)$. States with stabilizer dimension $n - t$: We give a protocol that runs in time $n^3\cdot(2^t/\tau)^{O(\log(1/\epsilon))}$, extending recent work on learning quantum states prepared by circuits with few non-Clifford gates, which only applied in the realizable setting where $\tau = 1$ [30, 37, 46, 61]. Discrete product states: If $C = K^{\otimes n}$ for some $\mu$-separated discrete set $K$ of single-qubit states, we give a protocol that runs in time $(n/\mu)^{O((1 + \log (1/\tau))/\mu)}/\epsilon^2$. This strictly generalizes a prior guarantee which applied to stabilizer product states [39]. For stabilizer product states, we give a further improved protocol that runs in time $(n^2/\epsilon^2)\cdot (1/\tau)^{O(\log(1/\tau))}$. As a corollary, we give the first protocol for estimating stabilizer fidelity, a standard measure of magic for quantum states, to error $\epsilon$ in $n^3 \mathrm{quasipoly}(1/\epsilon)$ time.
Quantum-Classical Separations in Shallow-Circuit-Based Learning with and without Noises
May 01, 2024We study quantum-classical separations between classical and quantum supervised learning models based on constant depth (i.e., shallow) circuits, in scenarios with and without noises. We construct a classification problem defined by a noiseless shallow quantum circuit and rigorously prove that any classical neural network with bounded connectivity requires logarithmic depth to output correctly with a larger-than-exponentially-small probability. This unconditional near-optimal quantum-classical separation originates from the quantum nonlocality property that distinguishes quantum circuits from their classical counterparts. We further derive the noise thresholds for demonstrating such a separation on near-term quantum devices under the depolarization noise model. We prove that this separation will persist if the noise strength is upper bounded by an inverse polynomial with respect to the system size, and vanish if the noise strength is greater than an inverse polylogarithmic function. In addition, for quantum devices with constant noise strength, we prove that no super-polynomial classical-quantum separation exists for any classification task defined by shallow Clifford circuits, independent of the structures of the circuits that specify the learning models.
Futility and utility of a few ancillas for Pauli channel learning
Sep 25, 2023In this paper we revisit one of the prototypical tasks for characterizing the structure of noise in quantum devices, estimating the eigenvalues of an $n$-qubit Pauli noise channel. Prior work (Chen et al., 2022) established exponential lower bounds for this task for algorithms with limited quantum memory. We first improve upon their lower bounds and show: (1) Any algorithm without quantum memory must make $\Omega(2^n/\epsilon^2)$ measurements to estimate each eigenvalue within error $\epsilon$. This is tight and implies the randomized benchmarking protocol is optimal, resolving an open question of (Flammia and Wallman, 2020). (2) Any algorithm with $\le k$ ancilla qubits of quantum memory must make $\Omega(2^{(n-k)/3})$ queries to the unknown channel. Crucially, unlike in (Chen et al., 2022), our bound holds even if arbitrary adaptive control and channel concatenation are allowed. In fact these lower bounds, like those of (Chen et al., 2022), hold even for the easier hypothesis testing problem of determining whether the underlying channel is completely depolarizing or has exactly one other nontrivial eigenvalue. Surprisingly, we show that: (3) With only $k=2$ ancilla qubits of quantum memory, there is an algorithm that solves this hypothesis testing task with high probability using a single measurement. Note that (3) does not contradict (2) as the protocol concatenates exponentially many queries to the channel before the measurement. This result suggests a novel mechanism by which channel concatenation and $O(1)$ qubits of quantum memory could work in tandem to yield striking speedups for quantum process learning that are not possible for quantum state learning.