 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Dynamics with Globally Controlled Analog Quantum Simulators
Aug 26, 2025


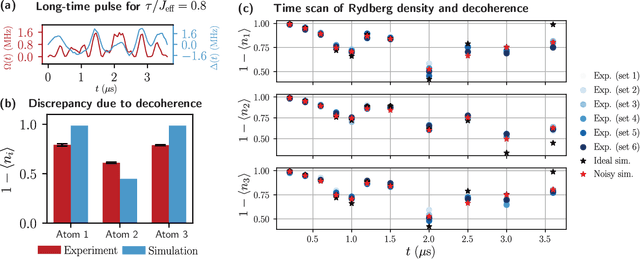
Analog quantum simulators with global control fields have emerged as powerful platforms for exploring complex quantum phenomena. Recent breakthroughs, such as the coherent control of thousands of atoms, highlight the growing potential for quantum applications at scale. Despite these advances, a fundamental theoretical question remains unresolved: to what extent can such systems realize universal quantum dynamics under global control? Here we establish a necessary and sufficient condition for universal quantum computation using only global pulse control, proving that a broad class of analog quantum simulators is, in fact, universal. We further extend this framework to fermionic and bosonic systems, including modern platforms such as ultracold atoms in optical superlattices. Crucially, to connect the theoretical possibility with experimental reality, we introduce a new control technique into the experiment - direct quantum optimal control. This method enables the synthesis of complex effective Hamiltonians and allows us to incorporate realistic hardware constraints. To show its practical power, we experimentally engineer three-body interactions outside the blockade regime and demonstrate topological dynamics on a Rydberg atom array. Using the new control framework, we overcome key experimental challenges, including hardware limitations and atom position fluctuations in the non-blockade regime, by identifying smooth, short-duration pulses that achieve high-fidelity dynamics. Experimental measurements reveal dynamical signatures of symmetry-protected-topological edge modes, confirming both the expressivity and feasibility of our approach. Our work opens a new avenue for quantum simulation beyond native hardware Hamiltonians, enabling the engineering of effective multi-body interactions and advancing the frontier of quantum information processing with globally-controlled analog platforms.
Ansatz-free Hamiltonian learning with Heisenberg-limited scaling
Feb 17, 2025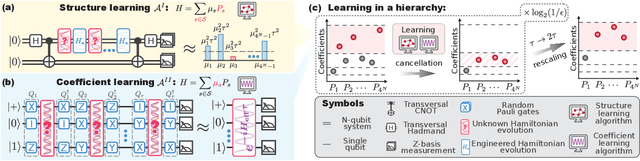
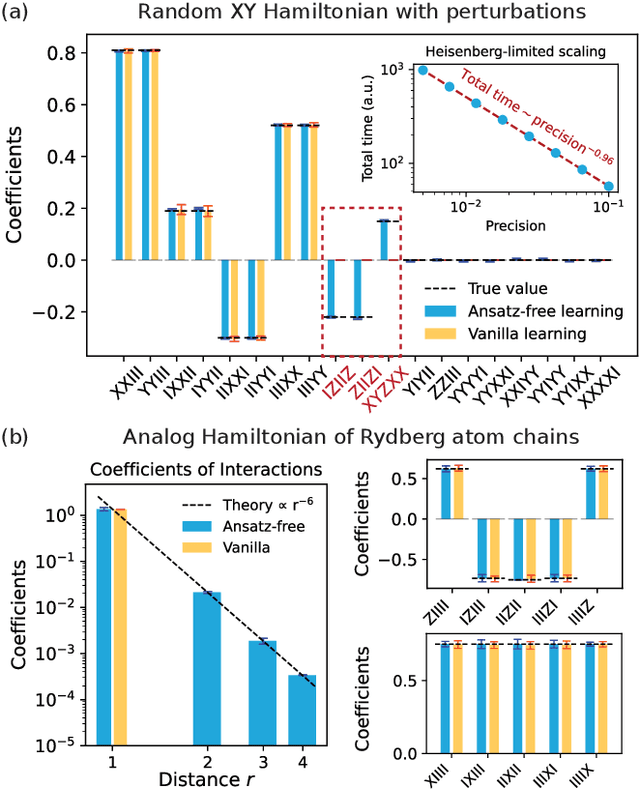
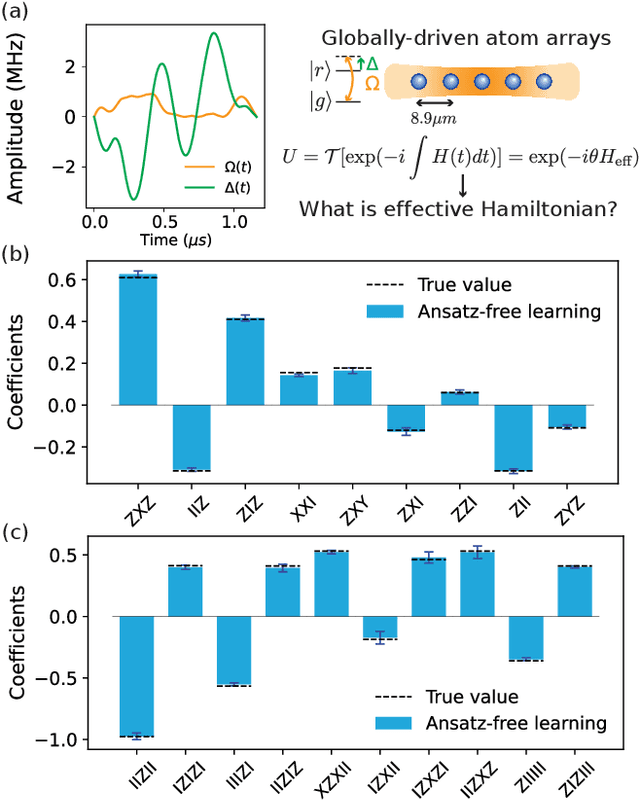

Learning the unknown interactions that govern a quantum system is crucial for quantum information processing, device benchmarking, and quantum sensing. The problem, known as Hamiltonian learning, is well understood under the assumption that interactions are local, but this assumption may not hold for arbitrary Hamiltonians. Previous methods all require high-order inverse polynomial dependency with precision, unable to surpass the standard quantum limit and reach the gold standard Heisenberg-limited scaling. Whether Heisenberg-limited Hamiltonian learning is possible without prior assumptions about the interaction structures, a challenge we term \emph{ansatz-free Hamiltonian learning}, remains an open question. In this work, we present a quantum algorithm to learn arbitrary sparse Hamiltonians without any structure constraints using only black-box queries of the system's real-time evolution and minimal digital controls to attain Heisenberg-limited scaling in estimation error. Our method is also resilient to state-preparation-and-measurement errors, enhancing its practical feasibility. Moreover, we establish a fundamental trade-off between total evolution time and quantum control on learning arbitrary interactions, revealing the intrinsic interplay between controllability and total evolution time complexity for any learning algorithm. These results pave the way for further exploration into Heisenberg-limited Hamiltonian learning in complex quantum systems under minimal assumptions, potentially enabling new benchmarking and verification protocols.
Derandomized shallow shadows: Efficient Pauli learning with bounded-depth circuits
Dec 25, 2024


Efficiently estimating large numbers of non-commuting observables is an important subroutine of many quantum science tasks. We present the derandomized shallow shadows (DSS) algorithm for efficiently learning a large set of non-commuting observables, using shallow circuits to rotate into measurement bases. Exploiting tensor network techniques to ensure polynomial scaling of classical resources, our algorithm outputs a set of shallow measurement circuits that approximately minimizes the sample complexity of estimating a given set of Pauli strings. We numerically demonstrate systematic improvement, in comparison with state-of-the-art techniques, for energy estimation of quantum chemistry benchmarks and verification of quantum many-body systems, and we observe DSS's performance consistently improves as one allows deeper measurement circuits. These results indicate that in addition to being an efficient, low-depth, stand-alone algorithm, DSS can also benefit many larger quantum algorithms requiring estimation of multiple non-commuting observables.
Demonstration of Robust and Efficient Quantum Property Learning with Shallow Shadows
Feb 27, 2024



Extracting information efficiently from quantum systems is a major component of quantum information processing tasks. Randomized measurements, or classical shadows, enable predicting many properties of arbitrary quantum states using few measurements. While random single qubit measurements are experimentally friendly and suitable for learning low-weight Pauli observables, they perform poorly for nonlocal observables. Prepending a shallow random quantum circuit before measurements maintains this experimental friendliness, but also has favorable sample complexities for observables beyond low-weight Paulis, including high-weight Paulis and global low-rank properties such as fidelity. However, in realistic scenarios, quantum noise accumulated with each additional layer of the shallow circuit biases the results. To address these challenges, we propose the robust shallow shadows protocol. Our protocol uses Bayesian inference to learn the experimentally relevant noise model and mitigate it in postprocessing. This mitigation introduces a bias-variance trade-off: correcting for noise-induced bias comes at the cost of a larger estimator variance. Despite this increased variance, as we demonstrate on a superconducting quantum processor, our protocol correctly recovers state properties such as expectation values, fidelity, and entanglement entropy, while maintaining a lower sample complexity compared to the random single qubit measurement scheme. We also theoretically analyze the effects of noise on sample complexity and show how the optimal choice of the shallow shadow depth varies with noise strength. This combined theoretical and experimental analysis positions the robust shallow shadow protocol as a scalable, robust, and sample-efficient protocol for characterizing quantum states on current quantum computing platforms.
Digital-analog quantum learning on Rydberg atom arrays
Jan 05, 2024We propose hybrid digital-analog learning algorithms on Rydberg atom arrays, combining the potentially practical utility and near-term realizability of quantum learning with the rapidly scaling architectures of neutral atoms. Our construction requires only single-qubit operations in the digital setting and global driving according to the Rydberg Hamiltonian in the analog setting. We perform a comprehensive numerical study of our algorithm on both classical and quantum data, given respectively by handwritten digit classification and unsupervised quantum phase boundary learning. We show in the two representative problems that digital-analog learning is not only feasible in the near term, but also requires shorter circuit depths and is more robust to realistic error models as compared to digital learning schemes. Our results suggest that digital-analog learning opens a promising path towards improved variational quantum learning experiments in the near term.
Discovery of Optimal Quantum Error Correcting Codes via Reinforcement Learning
May 10, 2023The recently introduced Quantum Lego framework provides a powerful method for generating complex quantum error correcting codes (QECCs) out of simple ones. We gamify this process and unlock a new avenue for code design and discovery using reinforcement learning (RL). One benefit of RL is that we can specify \textit{arbitrary} properties of the code to be optimized. We train on two such properties, maximizing the code distance, and minimizing the probability of logical error under biased Pauli noise. For the first, we show that the trained agent identifies ways to increase code distance beyond naive concatenation, saturating the linear programming bound for CSS codes on 13 qubits. With a learning objective to minimize the logical error probability under biased Pauli noise, we find the best known CSS code at this task for $\lesssim 20$ qubits. Compared to other (locally deformed) CSS codes, including Surface, XZZX, and 2D Color codes, our $[[17,1,3]]$ code construction actually has \textit{lower} adversarial distance, yet better protects the logical information, highlighting the importance of QECC desiderata. Lastly, we comment on how this RL framework can be used in conjunction with physical quantum devices to tailor a code without explicit characterization of the noise model.
Differentiable Programming of Isometric Tensor Networks
Nov 01, 2021
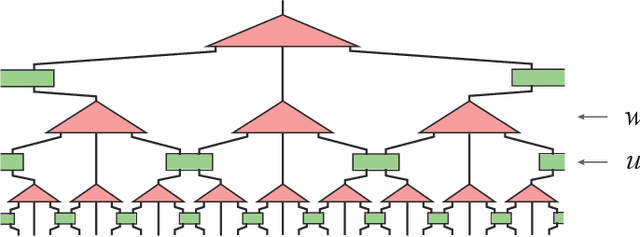
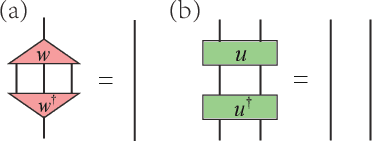
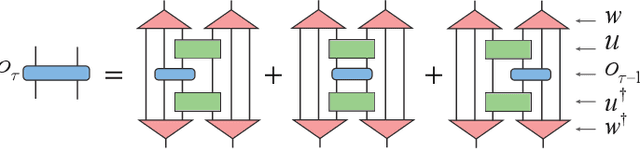
Differentiable programming is a new programming paradigm which enables large scale optimization through automatic calculation of gradients also known as auto-differentiation. This concept emerges from deep learning, and has also been generalized to tensor network optimizations. Here, we extend the differentiable programming to tensor networks with isometric constraints with applications to multiscale entanglement renormalization ansatz (MERA) and tensor network renormalization (TNR). By introducing several gradient-based optimization methods for the isometric tensor network and comparing with Evenbly-Vidal method, we show that auto-differentiation has a better performance for both stability and accuracy. We numerically tested our methods on 1D critical quantum Ising spin chain and 2D classical Ising model. We calculate the ground state energy for the 1D quantum model and internal energy for the classical model, and scaling dimensions of scaling operators and find they all agree with the theory well.
Hamiltonian-Driven Shadow Tomography of Quantum States
Feb 19, 2021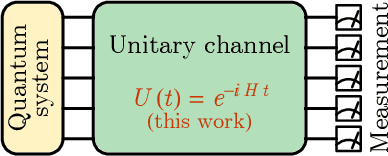
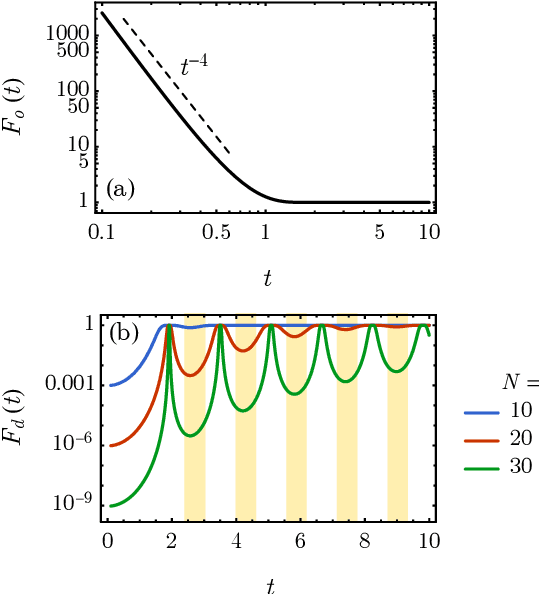
Classical shadow tomography provides an efficient method for predicting functions of an unknown quantum state from a few measurements of the state. It relies on a unitary channel that efficiently scrambles the quantum information of the state to the measurement basis. Facing the challenge of realizing deep unitary circuits on near-term quantum devices, we explore the scenario in which the unitary channel can be shallow and is generated by a quantum chaotic Hamiltonian via time evolution. We provide an unbiased estimator of the density matrix for all ranges of the evolution time. We analyze the sample complexity of the Hamiltonian-driven shadow tomography. We find that it can be more efficient than the unitary-2-design-based shadow tomography in a sequence of intermediate time windows that range from an order-1 scrambling time to a time scale of $D^{1/6}$, given the Hilbert space dimension $D$. In particular, the efficiency of predicting diagonal observables is improved by a factor of $D$ without sacrificing the efficiency of predicting off-diagonal observables.
RG-Flow: A hierarchical and explainable flow model based on renormalization group and sparse prior
Oct 07, 2020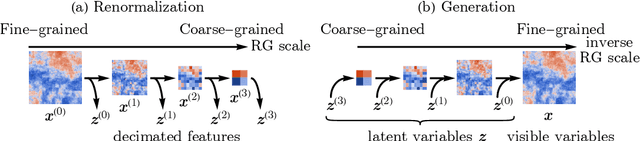
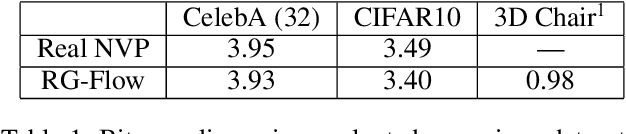
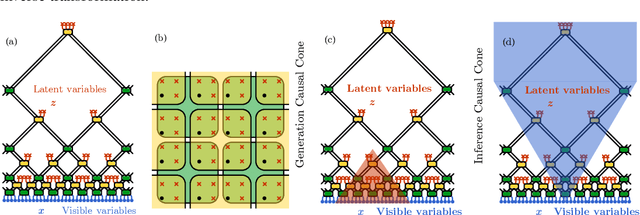

Flow-based generative models have become an important class of unsupervised learning approaches. In this work, we incorporate the key idea of renormalization group (RG) and sparse prior distribution to design a hierarchical flow-based generative model, called RG-Flow, which can separate different scale information of images with disentangle representations at each scale. We demonstrate our method mainly on the CelebA dataset and show that the disentangled representation at different scales enables semantic manipulation and style mixing of the images. To visualize the latent representation, we introduce the receptive fields for flow-based models and find receptive fields learned by RG-Flow are similar to convolutional neural networks. In addition, we replace the widely adopted Gaussian prior distribution by sparse prior distributions to further enhance the disentanglement of representations. From a theoretical perspective, the proposed method has $O(\log L)$ complexity for image inpainting compared to previous flow-based models with $O(L^2)$ complexity.