 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstration of Robust and Efficient Quantum Property Learning with Shallow Shadows
Feb 27, 2024



Extracting information efficiently from quantum systems is a major component of quantum information processing tasks. Randomized measurements, or classical shadows, enable predicting many properties of arbitrary quantum states using few measurements. While random single qubit measurements are experimentally friendly and suitable for learning low-weight Pauli observables, they perform poorly for nonlocal observables. Prepending a shallow random quantum circuit before measurements maintains this experimental friendliness, but also has favorable sample complexities for observables beyond low-weight Paulis, including high-weight Paulis and global low-rank properties such as fidelity. However, in realistic scenarios, quantum noise accumulated with each additional layer of the shallow circuit biases the results. To address these challenges, we propose the robust shallow shadows protocol. Our protocol uses Bayesian inference to learn the experimentally relevant noise model and mitigate it in postprocessing. This mitigation introduces a bias-variance trade-off: correcting for noise-induced bias comes at the cost of a larger estimator variance. Despite this increased variance, as we demonstrate on a superconducting quantum processor, our protocol correctly recovers state properties such as expectation values, fidelity, and entanglement entropy, while maintaining a lower sample complexity compared to the random single qubit measurement scheme. We also theoretically analyze the effects of noise on sample complexity and show how the optimal choice of the shallow shadow depth varies with noise strength. This combined theoretical and experimental analysis positions the robust shallow shadow protocol as a scalable, robust, and sample-efficient protocol for characterizing quantum states on current quantum computing platforms.
OMNIINPUT: A Model-centric Evaluation Framework through Output Distribution
Dec 06, 2023



We propose a novel model-centric evaluation framework, OmniInput, to evaluate the quality of an AI/ML model's predictions on all possible inputs (including human-unrecognizable ones), which is crucial for AI safety and reliability. Unlike traditional data-centric evaluation based on pre-defined test sets, the test set in OmniInput is self-constructed by the model itself and the model quality is evaluated by investigating its output distribution. We employ an efficient sampler to obtain representative inputs and the output distribution of the trained model, which, after selective annotation, can be used to estimate the model's precision and recall at different output values and a comprehensive precision-recall curve. Our experiments demonstrate that OmniInput enables a more fine-grained comparison between models, especially when their performance is almost the same on pre-defined datasets, leading to new findings and insights for how to train more robust, generalizable models.
Quantum Generative Modeling of Sequential Data with Trainable Token Embedding
Nov 08, 2023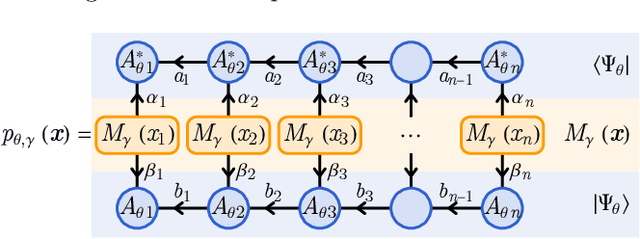
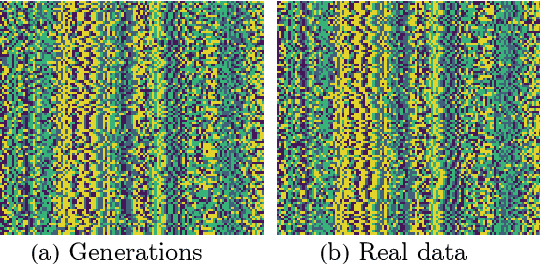
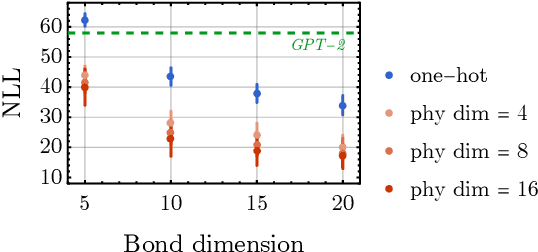
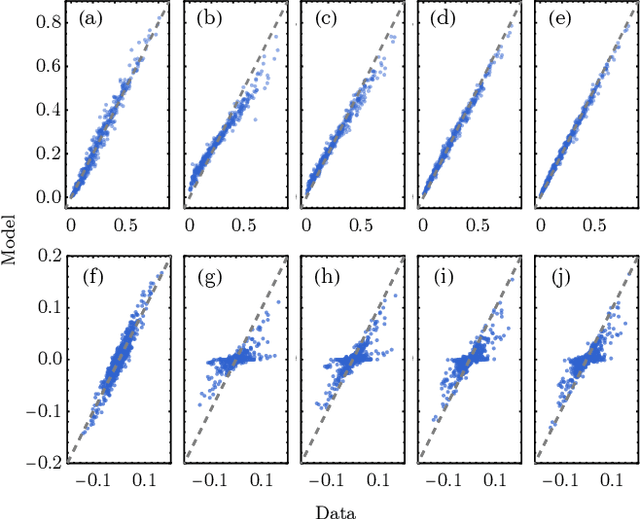
Generative models are a class of machine learning models that aim to learn the underlying probability distribution of data. Unlike discriminative models, generative models focus on capturing the data's inherent structure, allowing them to generate new samples that resemble the original data. To fully exploit the potential of modeling probability distributions using quantum physics, a quantum-inspired generative model known as the Born machines have shown great advancements in learning classical and quantum data over matrix product state(MPS) framework. The Born machines support tractable log-likelihood, autoregressive and mask sampling, and have shown outstanding performance in various unsupervised learning tasks. However, much of the current research has been centered on improving the expressive power of MPS, predominantly embedding each token directly by a corresponding tensor index. In this study, we generalize the embedding method into trainable quantum measurement operators that can be simultaneously honed with MPS. Our study indicated that combined with trainable embedding, Born machines can exhibit better performance and learn deeper correlations from the dataset.
Gradient-based Wang-Landau Algorithm: A Novel Sampler for Output Distribution of Neural Networks over the Input Space
Feb 21, 2023



The output distribution of a neural network (NN) over the entire input space captures the complete input-output mapping relationship, offering insights toward a more comprehensive NN understanding. Exhaustive enumeration or traditional Monte Carlo methods for the entire input space can exhibit impractical sampling time, especially for high-dimensional inputs. To make such difficult sampling computationally feasible, in this paper, we propose a novel Gradient-based Wang-Landau (GWL) sampler. We first draw the connection between the output distribution of a NN and the density of states (DOS) of a physical system. Then, we renovate the classic sampler for the DOS problem, the Wang-Landau algorithm, by replacing its random proposals with gradient-based Monte Carlo proposals. This way, our GWL sampler investigates the under-explored subsets of the input space much more efficiently. Extensive experiments have verified the accuracy of the output distribution generated by GWL and also showcased several interesting findings - for example, in a binary image classification task, both CNN and ResNet mapped the majority of human unrecognizable images to very negative logit values.
Hamiltonian-Driven Shadow Tomography of Quantum States
Feb 19, 2021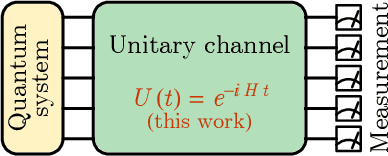
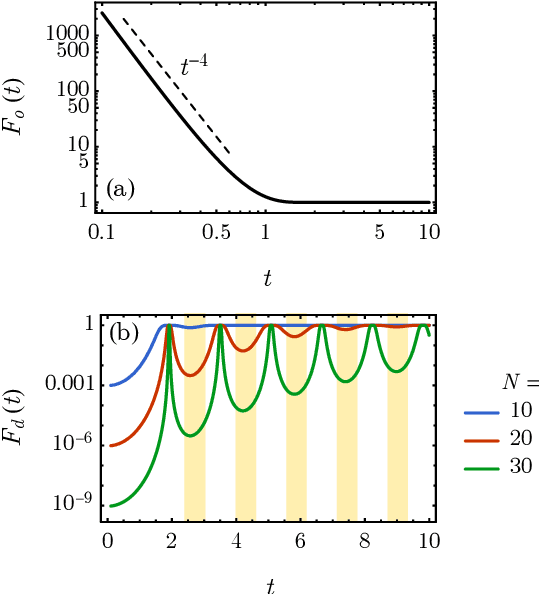
Classical shadow tomography provides an efficient method for predicting functions of an unknown quantum state from a few measurements of the state. It relies on a unitary channel that efficiently scrambles the quantum information of the state to the measurement basis. Facing the challenge of realizing deep unitary circuits on near-term quantum devices, we explore the scenario in which the unitary channel can be shallow and is generated by a quantum chaotic Hamiltonian via time evolution. We provide an unbiased estimator of the density matrix for all ranges of the evolution time. We analyze the sample complexity of the Hamiltonian-driven shadow tomography. We find that it can be more efficient than the unitary-2-design-based shadow tomography in a sequence of intermediate time windows that range from an order-1 scrambling time to a time scale of $D^{1/6}$, given the Hilbert space dimension $D$. In particular, the efficiency of predicting diagonal observables is improved by a factor of $D$ without sacrificing the efficiency of predicting off-diagonal observables.
RG-Flow: A hierarchical and explainable flow model based on renormalization group and sparse prior
Oct 07, 2020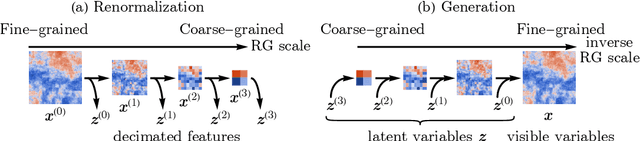
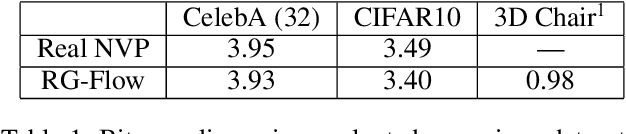

Flow-based generative models have become an important class of unsupervised learning approaches. In this work, we incorporate the key idea of renormalization group (RG) and sparse prior distribution to design a hierarchical flow-based generative model, called RG-Flow, which can separate different scale information of images with disentangle representations at each scale. We demonstrate our method mainly on the CelebA dataset and show that the disentangled representation at different scales enables semantic manipulation and style mixing of the images. To visualize the latent representation, we introduce the receptive fields for flow-based models and find receptive fields learned by RG-Flow are similar to convolutional neural networks. In addition, we replace the widely adopted Gaussian prior distribution by sparse prior distributions to further enhance the disentanglement of representations. From a theoretical perspective, the proposed method has $O(\log L)$ complexity for image inpainting compared to previous flow-based models with $O(L^2)$ complexity.
Information Scrambling in Quantum Neural Networks
Sep 26, 2019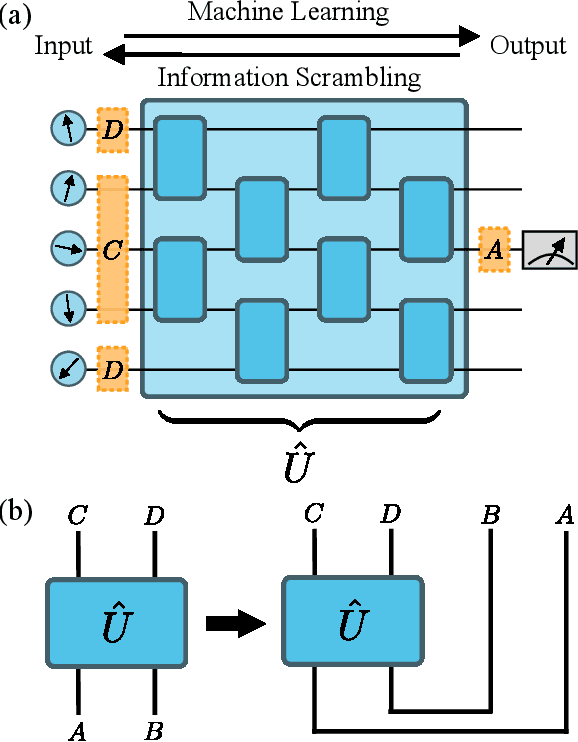
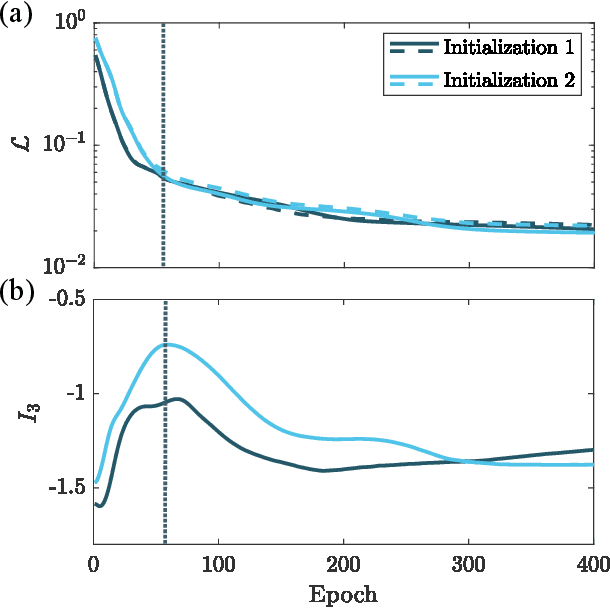
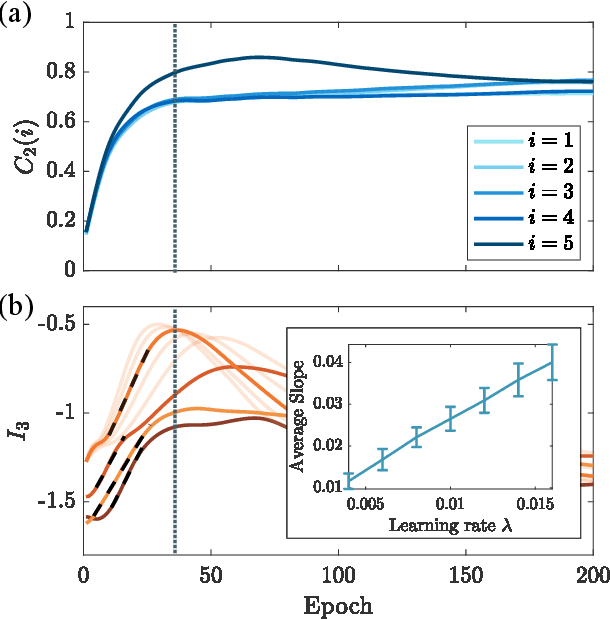
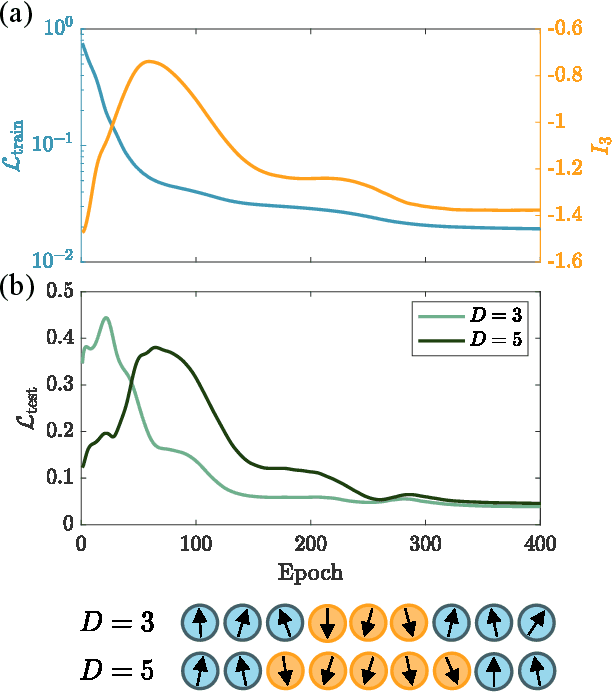
Quantum neural networks are one of the promising applications for near-term noisy intermediate-scale quantum computers. A quantum neural network distills the information from the input wavefunction into the output qubits. In this Letter, we show that this process can also be viewed from the opposite direction: the quantum information in the output qubits is scrambled into the input. This observation motivates us to use the tripartite information, a quantity recently developed to characterize information scrambling, to diagnose the training dynamics of quantum neural networks. We empirically find strong correlation between the dynamical behavior of the tripartite information and the loss function in the training process, from which we identify that the training process has two stages for randomly initialized networks. In the early stage, the network performance improves rapidly and the tripartite information increases linearly with a universal slope, meaning that the neural network becomes less scrambled than the random unitary. In the latter stage, the network performance improves slowly while the tripartite information decreases. We present evidences that the network constructs local correlations in the early stage and learns large-scale structures in the latter stage. We believe this two-stage training dynamics is universal and is applicable to a wide range of problems. Our work builds bridges between two research subjects of quantum neural networks and information scrambling, which opens up a new perspective to understand quantum neural networks.