 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Learning for Parameter Prediction of Quantum Approximate Optimization Algorithm
Mar 05, 2024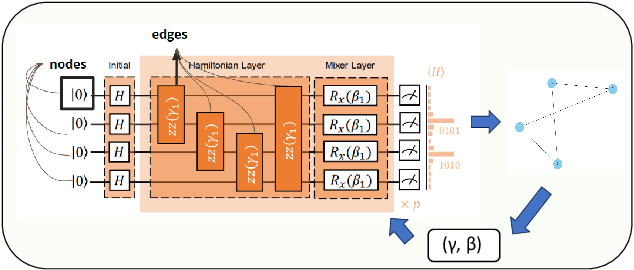

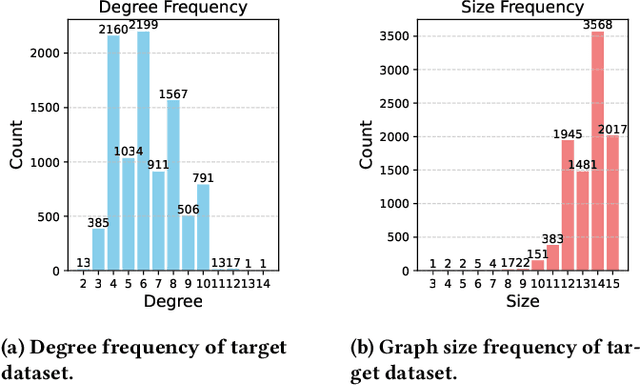
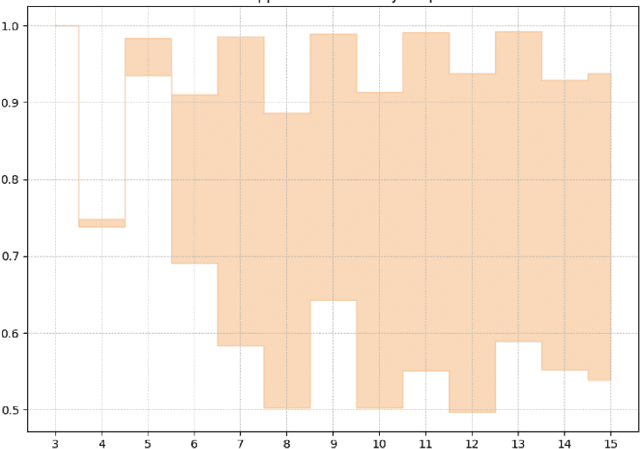
In recent years, quantum computing has emerged as a transformative force in the field of combinatorial optimization, offering novel approaches to tackling complex problems that have long challenged classical computational methods. Among these, the Quantum Approximate Optimization Algorithm (QAOA) stands out for its potential to efficiently solve the Max-Cut problem, a quintessential example of combinatorial optimization. However, practical application faces challenges due to current limitations on quantum computational resource. Our work optimizes QAOA initialization, using Graph Neural Networks (GNN) as a warm-start technique. This sacrifices affordable computational resource on classical computer to reduce quantum computational resource overhead, enhancing QAOA's effectiveness. Experiments with various GNN architectures demonstrate the adaptability and stability of our framework, highlighting the synergy between quantum algorithms and machine learning. Our findings show GNN's potential in improving QAOA performance, opening new avenues for hybrid quantum-classical approaches in quantum computing and contributing to practical applications.
Demonstration of Robust and Efficient Quantum Property Learning with Shallow Shadows
Feb 27, 2024



Extracting information efficiently from quantum systems is a major component of quantum information processing tasks. Randomized measurements, or classical shadows, enable predicting many properties of arbitrary quantum states using few measurements. While random single qubit measurements are experimentally friendly and suitable for learning low-weight Pauli observables, they perform poorly for nonlocal observables. Prepending a shallow random quantum circuit before measurements maintains this experimental friendliness, but also has favorable sample complexities for observables beyond low-weight Paulis, including high-weight Paulis and global low-rank properties such as fidelity. However, in realistic scenarios, quantum noise accumulated with each additional layer of the shallow circuit biases the results. To address these challenges, we propose the robust shallow shadows protocol. Our protocol uses Bayesian inference to learn the experimentally relevant noise model and mitigate it in postprocessing. This mitigation introduces a bias-variance trade-off: correcting for noise-induced bias comes at the cost of a larger estimator variance. Despite this increased variance, as we demonstrate on a superconducting quantum processor, our protocol correctly recovers state properties such as expectation values, fidelity, and entanglement entropy, while maintaining a lower sample complexity compared to the random single qubit measurement scheme. We also theoretically analyze the effects of noise on sample complexity and show how the optimal choice of the shallow shadow depth varies with noise strength. This combined theoretical and experimental analysis positions the robust shallow shadow protocol as a scalable, robust, and sample-efficient protocol for characterizing quantum states on current quantum computing platforms.
PAN: Pulse Ansatz on NISQ Machines
Aug 02, 2022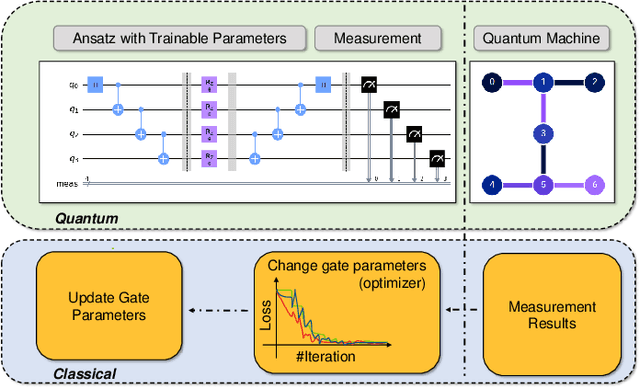
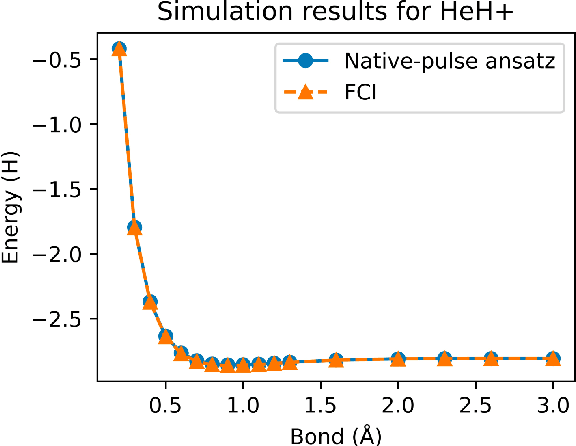
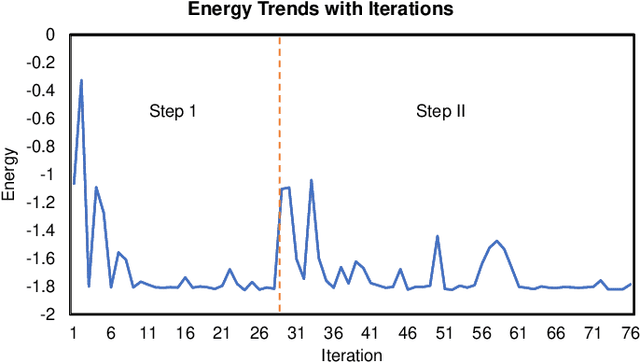

Variational quantum algorithms (VQAs) have demonstrated great potentials in the NISQ era. In the workflow of VQA, the parameters of ansatz are iteratively updated to approximate the desired quantum states. We have seen various efforts to draft better ansatz with less gates. In quantum computers, the gate ansatz will eventually be transformed into control signals such as microwave pulses on transmons. And the control pulses need elaborate calibration to minimize the errors such as over-rotation and under-rotation. In the case of VQAs, this procedure will introduce redundancy, but the variational properties of VQAs can naturally handle problems of over-rotation and under-rotation by updating the amplitude and frequency parameters. Therefore, we propose PAN, a native-pulse ansatz generator framework for VQAs. We generate native-pulse ansatz with trainable parameters for amplitudes and frequencies. In our proposed PAN, we are tuning parametric pulses, which are natively supported on NISQ computers. Considering that parameter-shift rules do not hold for native-pulse ansatz, we need to deploy non-gradient optimizers. To constrain the number of parameters sent to the optimizer, we adopt a progressive way to generate our native-pulse ansatz. Experiments are conducted on both simulators and quantum devices to validate our methods. When adopted on NISQ machines, PAN obtained improved the performance with decreased latency by an average of 86%. PAN is able to achieve 99.336% and 96.482% accuracy for VQE tasks on H2 and HeH+ respectively, even with considerable noises in NISQ machines.
Reinforcement Learning in Presence of Discrete Markovian Context Evolution
Feb 14, 2022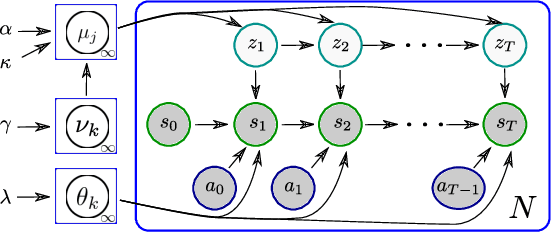
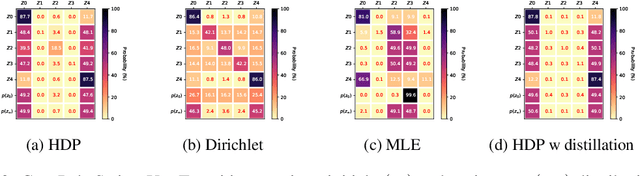
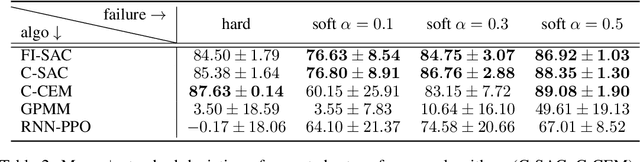
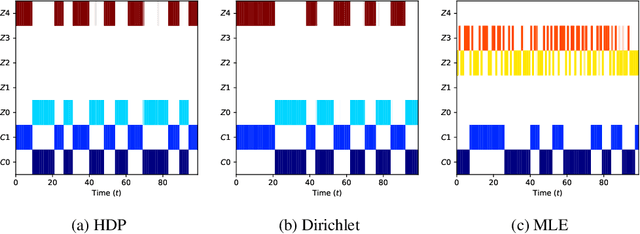
We consider a context-dependent Reinforcement Learning (RL) setting, which is characterized by: a) an unknown finite number of not directly observable contexts; b) abrupt (discontinuous) context changes occurring during an episode; and c) Markovian context evolution. We argue that this challenging case is often met in applications and we tackle it using a Bayesian approach and variational inference. We adapt a sticky Hierarchical Dirichlet Process (HDP) prior for model learning, which is arguably best-suited for Markov process modeling. We then derive a context distillation procedure, which identifies and removes spurious contexts in an unsupervised fashion. We argue that the combination of these two components allows to infer the number of contexts from data thus dealing with the context cardinality assumption. We then find the representation of the optimal policy enabling efficient policy learning using off-the-shelf RL algorithms. Finally, we demonstrate empirically (using gym environments cart-pole swing-up, drone, intersection) that our approach succeeds where state-of-the-art methods of other frameworks fail and elaborate on the reasons for such failures.
Efficient Semi-Implicit Variational Inference
Jan 15, 2021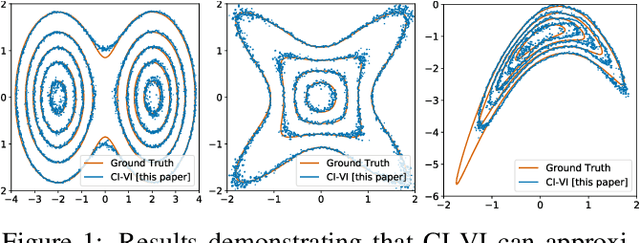

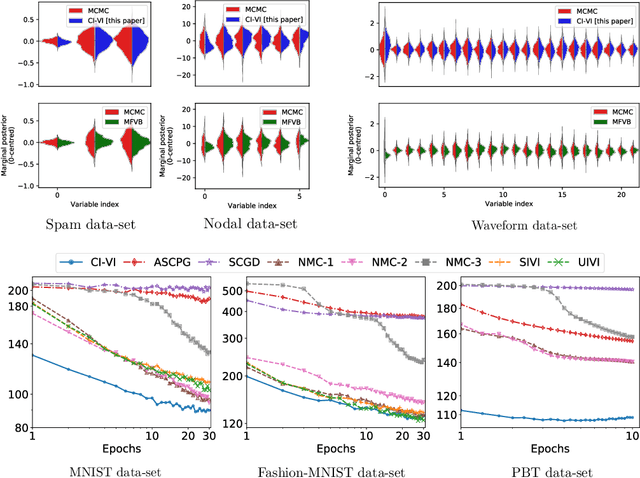
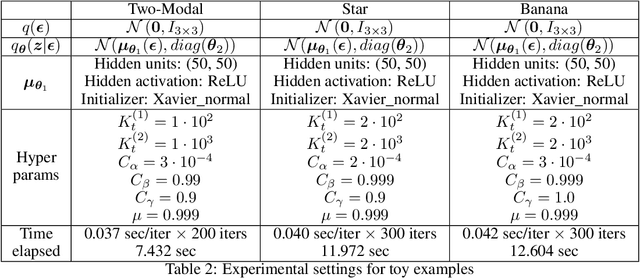
In this paper, we propose CI-VI an efficient and scalable solver for semi-implicit variational inference (SIVI). Our method, first, maps SIVI's evidence lower bound (ELBO) to a form involving a nonlinear functional nesting of expected values and then develops a rigorous optimiser capable of correctly handling bias inherent to nonlinear nested expectations using an extrapolation-smoothing mechanism coupled with gradient sketching. Our theoretical results demonstrate convergence to a stationary point of the ELBO in general non-convex settings typically arising when using deep network models and an order of $O(t^{-\frac{4}{5}})$ gradient-bias-vanishing rate. We believe these results generalise beyond the specific nesting arising from SIVI to other forms. Finally, in a set of experiments, we demonstrate the effectiveness of our algorithm in approximating complex posteriors on various data-sets including those from natural language processing.
System Design and Analysis for Energy-Efficient Passive UAV Radar Imaging System using Illuminators of Opportunity
Oct 01, 2020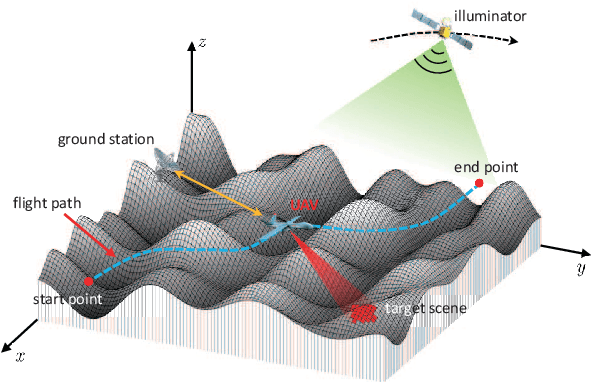
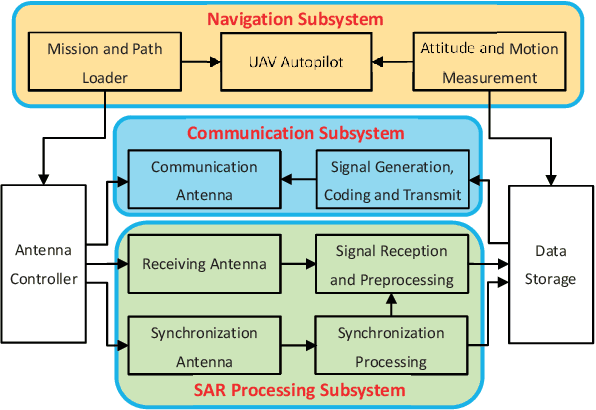
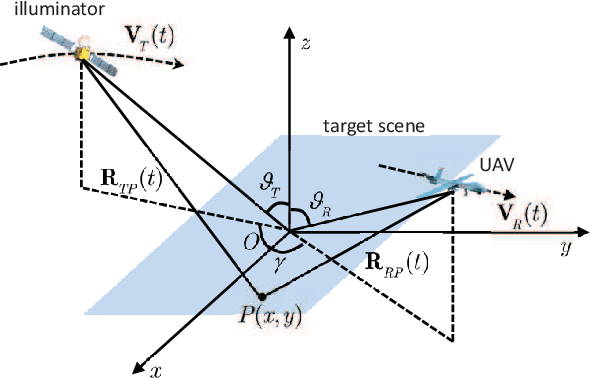
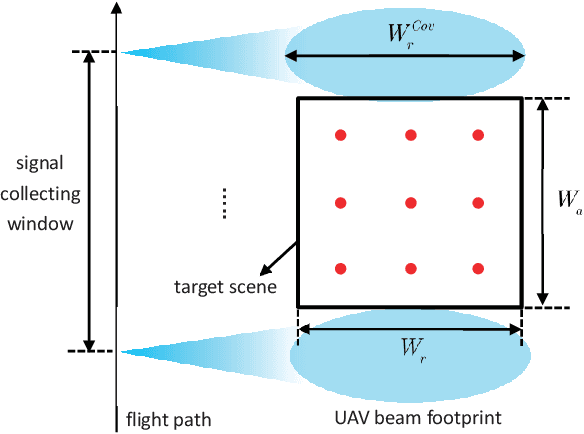
Unmanned ariel vehicle (UAV) can provide superior flexibility and cost-efficiency for modern radar imaging systems, which is an ideal platform for advanced remote sensing applications using synthetic aperture radar (SAR) technology. In this paper, an energy-efficient passive UAV radar imaging system using illuminators of opportunity is first proposed and investigated. Equipped with a SAR receiver, the UAV platform passively reuses the backscattered signal of the target scene from an external illuminator, such as SAR satellite, GNSS or ground-based stationary commercial illuminators, and achieves bi-static SAR imaging and data communication. The system can provide instant accessibility to the radar image of the interested targets with enhanced platform concealment, which is an essential tool for stealth observation and scene monitoring. The mission concept and system block diagram are first presented with justifications on the advantages of the system. Then, the prospective imaging performance and system feasibility are analyzed for the typical illuminators based on signal and spatial resolution model. With different illuminators, the proposed system can achieve distinct imaging performance, which offers more alternatives for various mission requirements. A set of mission performance evaluators is established to quantitatively assess the capability of the system in a comprehensive manner, including UAV navigation, passive SAR imaging and communication. Finally, the validity of the proposed performance evaluators are verified by numerical simulations.
Wasserstein Robust Reinforcement Learning
Sep 16, 2019
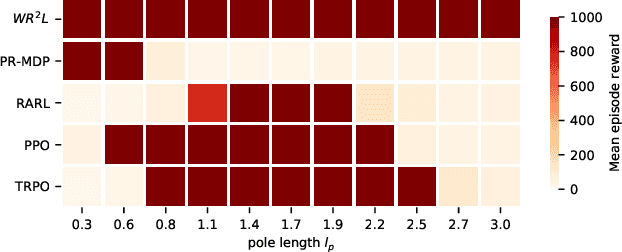

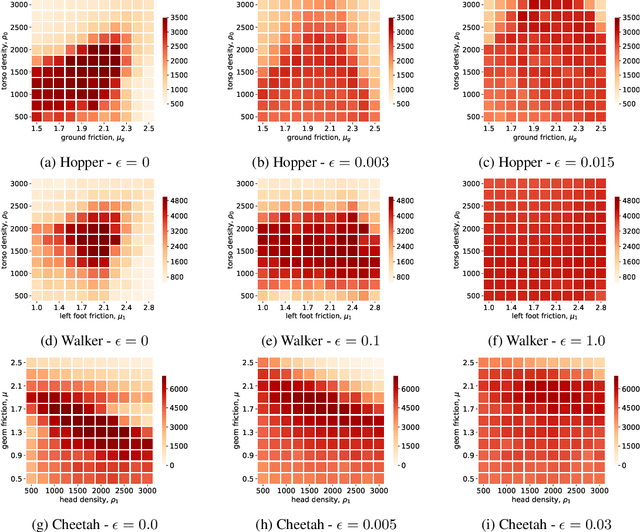
Reinforcement learning algorithms, though successful, tend to over-fit to training environments hampering their application to the real-world. This paper proposes $\text{W}\text{R}^{2}\text{L}$ -- a robust reinforcement learning algorithm with significant robust performance on low and high-dimensional control tasks. Our method formalises robust reinforcement learning as a novel min-max game with a Wasserstein constraint for a correct and convergent solver. Apart from the formulation, we also propose an efficient and scalable solver following a novel zero-order optimisation method that we believe can be useful to numerical optimisation in general. We empirically demonstrate significant gains compared to standard and robust state-of-the-art algorithms on high-dimensional MuJuCo environments.
Optimizing human-interpretable dialog management policy using Genetic Algorithm
May 13, 2016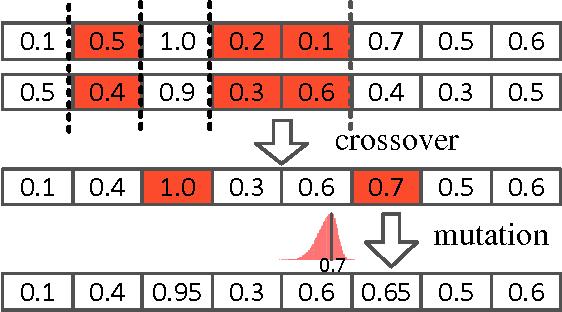
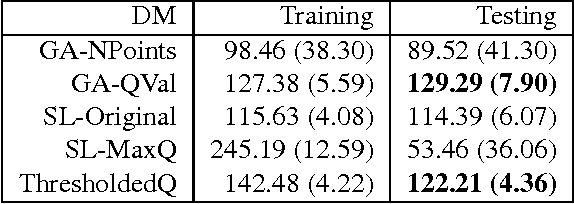
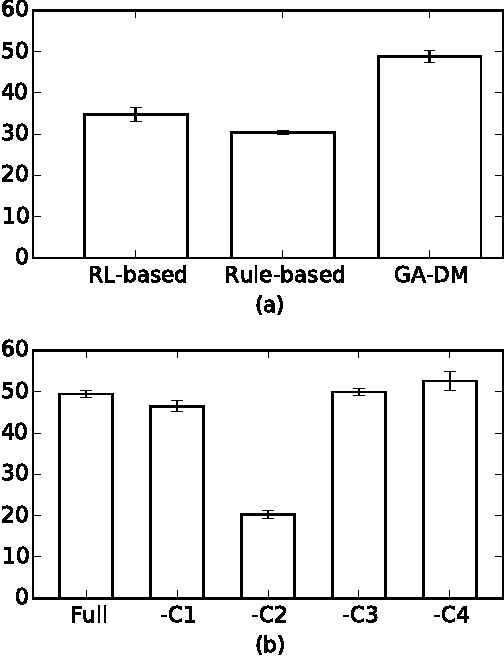
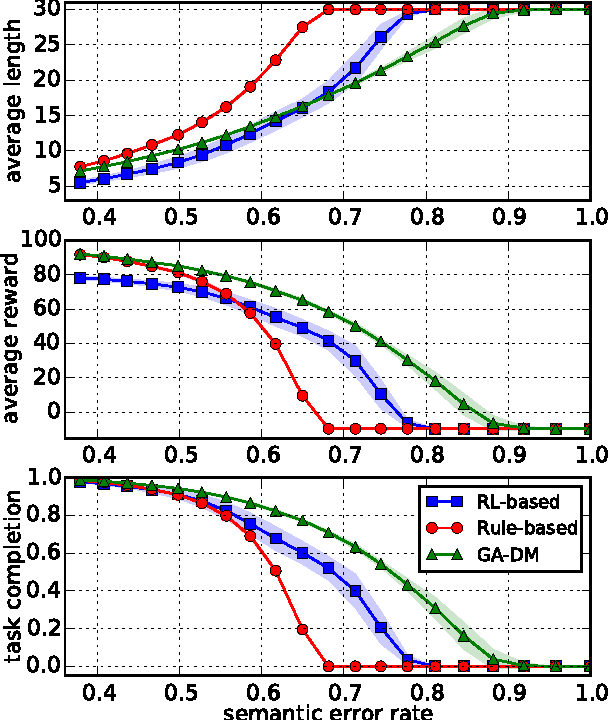
Automatic optimization of spoken dialog management policies that are robust to environmental noise has long been the goal for both academia and industry. Approaches based on reinforcement learning have been proved to be effective. However, the numerical representation of dialog policy is human-incomprehensible and difficult for dialog system designers to verify or modify, which limits its practical application. In this paper we propose a novel framework for optimizing dialog policies specified in domain language using genetic algorithm. The human-interpretable representation of policy makes the method suitable for practical employment. We present learning algorithms using user simulation and real human-machine dialogs respectively.Empirical experimental results are given to show the effectiveness of the proposed approach.