 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLGym: A New Framework and Benchmark for Advancing AI Research Agents
Feb 20, 2025



We introduce Meta MLGym and MLGym-Bench, a new framework and benchmark for evaluating and developing LLM agents on AI research tasks. This is the first Gym environment for machine learning (ML) tasks, enabling research on reinforcement learning (RL) algorithms for training such agents. MLGym-bench consists of 13 diverse and open-ended AI research tasks from diverse domains such as computer vision, natural language processing, reinforcement learning, and game theory. Solving these tasks requires real-world AI research skills such as generating new ideas and hypotheses, creating and processing data, implementing ML methods, training models, running experiments, analyzing the results, and iterating through this process to improve on a given task. We evaluate a number of frontier large language models (LLMs) on our benchmarks such as Claude-3.5-Sonnet, Llama-3.1 405B, GPT-4o, o1-preview, and Gemini-1.5 Pro. Our MLGym framework makes it easy to add new tasks, integrate and evaluate models or agents, generate synthetic data at scale, as well as develop new learning algorithms for training agents on AI research tasks. We find that current frontier models can improve on the given baselines, usually by finding better hyperparameters, but do not generate novel hypotheses, algorithms, architectures, or substantial improvements. We open-source our framework and benchmark to facilitate future research in advancing the AI research capabilities of LLM agents.
BricksRL: A Platform for Democratizing Robotics and Reinforcement Learning Research and Education with LEGO
Jun 25, 2024



We present BricksRL, a platform designed to democratize access to robotics for reinforcement learning research and education. BricksRL facilitates the creation, design, and training of custom LEGO robots in the real world by interfacing them with the TorchRL library for reinforcement learning agents. The integration of TorchRL with the LEGO hubs, via Bluetooth bidirectional communication, enables state-of-the-art reinforcement learning training on GPUs for a wide variety of LEGO builds. This offers a flexible and cost-efficient approach for scaling and also provides a robust infrastructure for robot-environment-algorithm communication. We present various experiments across tasks and robot configurations, providing built plans and training results. Furthermore, we demonstrate that inexpensive LEGO robots can be trained end-to-end in the real world to achieve simple tasks, with training times typically under 120 minutes on a normal laptop. Moreover, we show how users can extend the capabilities, exemplified by the successful integration of non-LEGO sensors. By enhancing accessibility to both robotics and reinforcement learning, BricksRL establishes a strong foundation for democratized robotic learning in research and educational settings.
ACEGEN: Reinforcement learning of generative chemical agents for drug discovery
May 07, 2024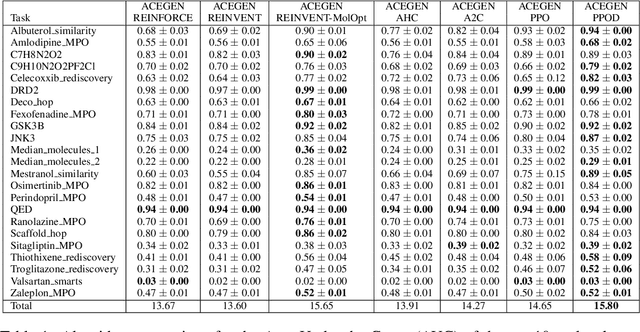


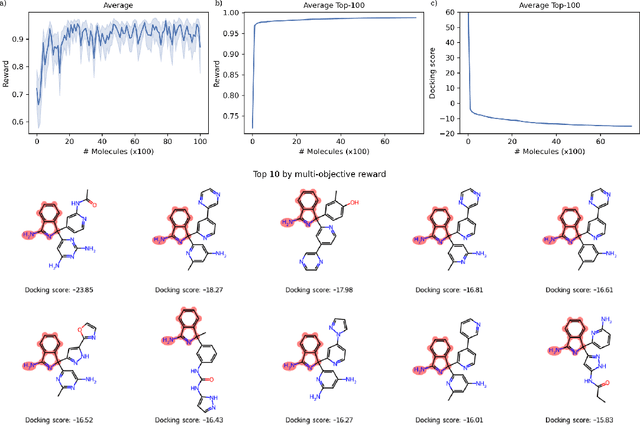
In recent years, reinforcement learning (RL) has emerged as a valuable tool in drug design, offering the potential to propose and optimize molecules with desired properties. However, striking a balance between capability, flexibility, and reliability remains challenging due to the complexity of advanced RL algorithms and the significant reliance on specialized code. In this work, we introduce ACEGEN, a comprehensive and streamlined toolkit tailored for generative drug design, built using TorchRL, a modern decision-making library that offers efficient and thoroughly tested reusable components. ACEGEN provides a robust, flexible, and efficient platform for molecular design. We validate its effectiveness by benchmarking it across various algorithms and conducting multiple drug discovery case studies. ACEGEN is accessible at https://github.com/acellera/acegen-open.
BenchMARL: Benchmarking Multi-Agent Reinforcement Learning
Dec 03, 2023The field of Multi-Agent Reinforcement Learning (MARL) is currently facing a reproducibility crisis. While solutions for standardized reporting have been proposed to address the issue, we still lack a benchmarking tool that enables standardization and reproducibility, while leveraging cutting-edge Reinforcement Learning (RL) implementations. In this paper, we introduce BenchMARL, the first MARL training library created to enable standardized benchmarking across different algorithms, models, and environments. BenchMARL uses TorchRL as its backend, granting it high performance and maintained state-of-the-art implementations while addressing the broad community of MARL PyTorch users. Its design enables systematic configuration and reporting, thus allowing users to create and run complex benchmarks from simple one-line inputs. BenchMARL is open-sourced on GitHub: https://github.com/facebookresearch/BenchMARL
RoboHive: A Unified Framework for Robot Learning
Oct 10, 2023



We present RoboHive, a comprehensive software platform and ecosystem for research in the field of Robot Learning and Embodied Artificial Intelligence. Our platform encompasses a diverse range of pre-existing and novel environments, including dexterous manipulation with the Shadow Hand, whole-arm manipulation tasks with Franka and Fetch robots, quadruped locomotion, among others. Included environments are organized within and cover multiple domains such as hand manipulation, locomotion, multi-task, multi-agent, muscles, etc. In comparison to prior works, RoboHive offers a streamlined and unified task interface taking dependency on only a minimal set of well-maintained packages, features tasks with high physics fidelity and rich visual diversity, and supports common hardware drivers for real-world deployment. The unified interface of RoboHive offers a convenient and accessible abstraction for algorithmic research in imitation, reinforcement, multi-task, and hierarchical learning. Furthermore, RoboHive includes expert demonstrations and baseline results for most environments, providing a standard for benchmarking and comparisons. Details: https://sites.google.com/view/robohive
TorchRL: A data-driven decision-making library for PyTorch
Jun 01, 2023Striking a balance between integration and modularity is crucial for a machine learning library to be versatile and user-friendly, especially in handling decision and control tasks that involve large development teams and complex, real-world data, and environments. To address this issue, we propose TorchRL, a generalistic control library for PyTorch that provides well-integrated, yet standalone components. With a versatile and robust primitive design, TorchRL facilitates streamlined algorithm development across the many branches of Reinforcement Learning (RL) and control. We introduce a new PyTorch primitive, TensorDict, as a flexible data carrier that empowers the integration of the library's components while preserving their modularity. Hence replay buffers, datasets, distributed data collectors, environments, transforms and objectives can be effortlessly used in isolation or combined. We provide a detailed description of the building blocks, supporting code examples and an extensive overview of the library across domains and tasks. Finally, we show comparative benchmarks to demonstrate its computational efficiency. TorchRL fosters long-term support and is publicly available on GitHub for greater reproducibility and collaboration within the research community. The code is opensourced on https://github.com/pytorch/rl.
CACTI: A Framework for Scalable Multi-Task Multi-Scene Visual Imitation Learning
Dec 12, 2022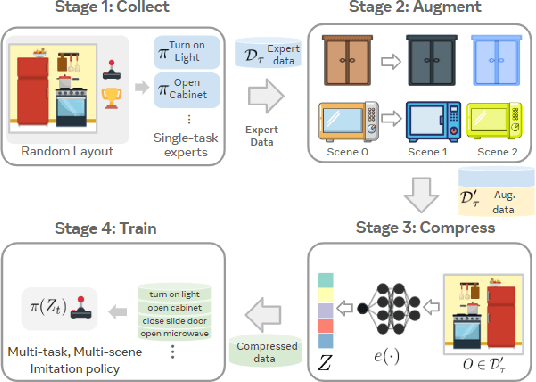

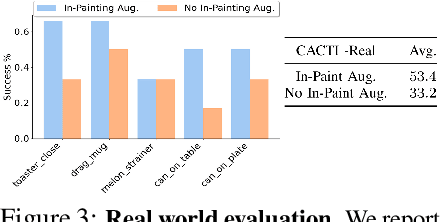
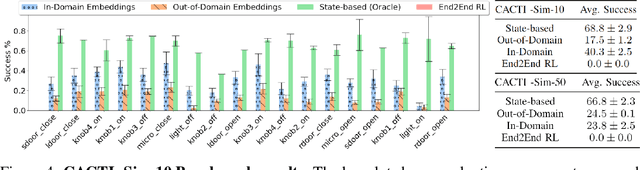
Developing robots that are capable of many skills and generalization to unseen scenarios requires progress on two fronts: efficient collection of large and diverse datasets, and training of high-capacity policies on the collected data. While large datasets have propelled progress in other fields like computer vision and natural language processing, collecting data of comparable scale is particularly challenging for physical systems like robotics. In this work, we propose a framework to bridge this gap and better scale up robot learning, under the lens of multi-task, multi-scene robot manipulation in kitchen environments. Our framework, named CACTI, has four stages that separately handle data collection, data augmentation, visual representation learning, and imitation policy training. In the CACTI framework, we highlight the benefit of adapting state-of-the-art models for image generation as part of the augmentation stage, and the significant improvement of training efficiency by using pretrained out-of-domain visual representations at the compression stage. Experimentally, we demonstrate that 1) on a real robot setup, CACTI enables efficient training of a single policy capable of 10 manipulation tasks involving kitchen objects, and robust to varying layouts of distractor objects; 2) in a simulated kitchen environment, CACTI trains a single policy on 18 semantic tasks across up to 50 layout variations per task. The simulation task benchmark and augmented datasets in both real and simulated environments will be released to facilitate future research.
Implicit Variational Conditional Sampling with Normalizing Flows
Jul 06, 2021
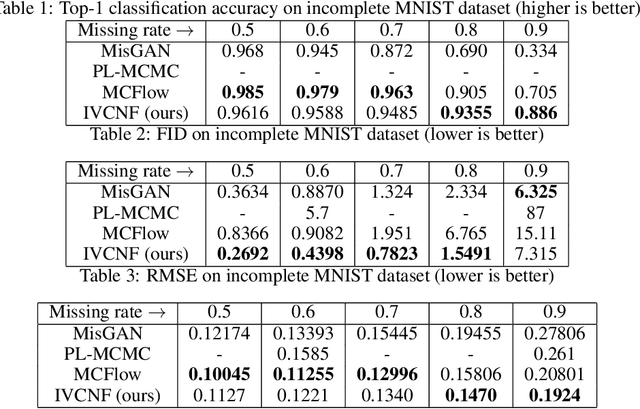
We present a method for conditional sampling with normalizing flows when only part of an observation is available. We rely on the following fact: if the flow's domain can be partitioned in such a way that the flow restrictions to subdomains keep the bijectivity property, a lower bound to the conditioning variable log-probability can be derived. Simulation from the variational conditional flow then amends to solving an equality constraint. Our contribution is three-fold: a) we provide detailed insights on the choice of variational distributions; b) we propose how to partition the input space of the flow to preserve bijectivity property; c) we propose a set of methods to optimise the variational distribution in specific cases. Through extensive experiments, we show that our sampling method can be applied with success to invertible residual networks for inference and classification.
Efficient Semi-Implicit Variational Inference
Jan 15, 2021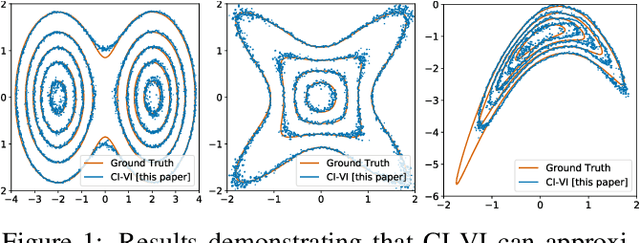

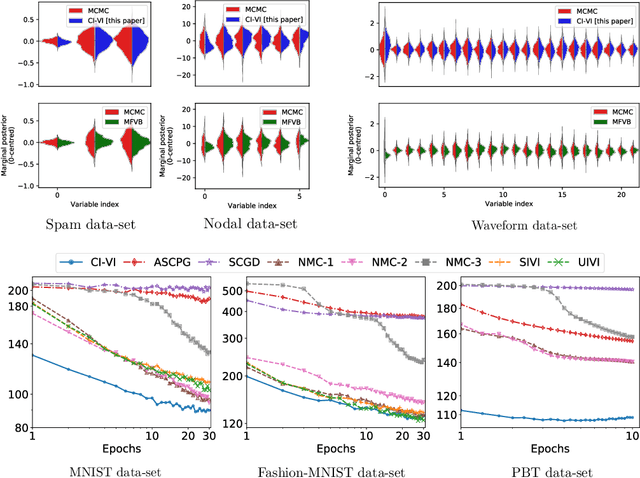
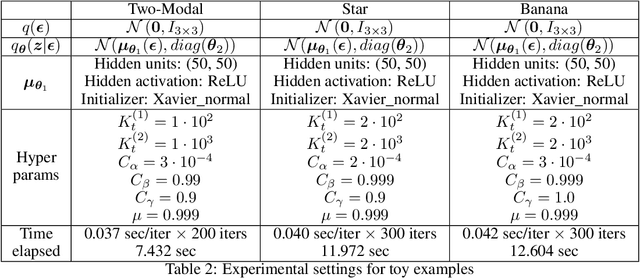
In this paper, we propose CI-VI an efficient and scalable solver for semi-implicit variational inference (SIVI). Our method, first, maps SIVI's evidence lower bound (ELBO) to a form involving a nonlinear functional nesting of expected values and then develops a rigorous optimiser capable of correctly handling bias inherent to nonlinear nested expectations using an extrapolation-smoothing mechanism coupled with gradient sketching. Our theoretical results demonstrate convergence to a stationary point of the ELBO in general non-convex settings typically arising when using deep network models and an order of $O(t^{-\frac{4}{5}})$ gradient-bias-vanishing rate. We believe these results generalise beyond the specific nesting arising from SIVI to other forms. Finally, in a set of experiments, we demonstrate the effectiveness of our algorithm in approximating complex posteriors on various data-sets including those from natural language processing.
SAMBA: Safe Model-Based & Active Reinforcement Learning
Jun 12, 2020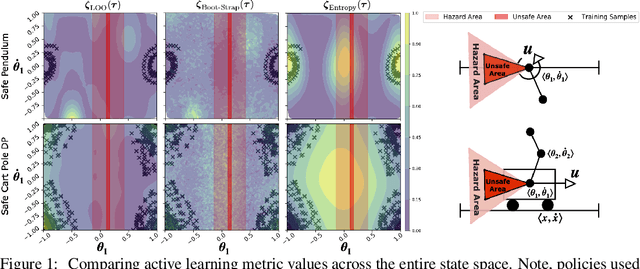
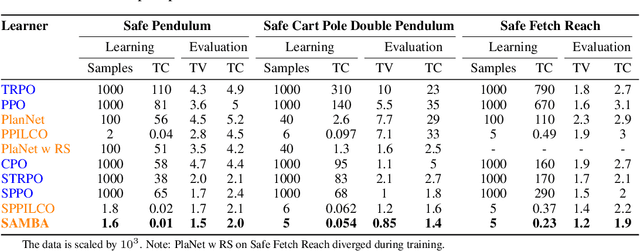
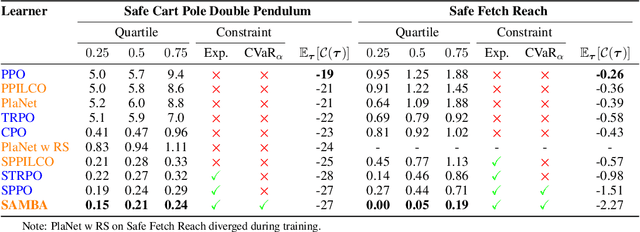
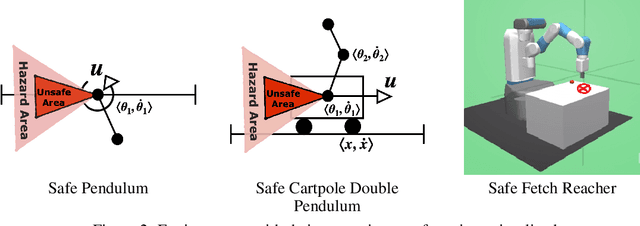
In this paper, we propose SAMBA, a novel framework for safe reinforcement learning that combines aspects from probabilistic modelling, information theory, and statistics. Our method builds upon PILCO to enable active exploration using novel(semi-)metrics for out-of-sample Gaussian process evaluation optimised through a multi-objective problem that supports conditional-value-at-risk constraints. We evaluate our algorithm on a variety of safe dynamical system benchmarks involving both low and high-dimensional state representations. Our results show orders of magnitude reductions in samples and violations compared to state-of-the-art methods. Lastly, we provide intuition as to the effectiveness of the framework by a detailed analysis of our active metrics and safety constraints.