 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Let's (not) just put things in Context: Test-Time Training for Long-Context LLMs
Dec 15, 2025Progress on training and architecture strategies has enabled LLMs with millions of tokens in context length. However, empirical evidence suggests that such long-context LLMs can consume far more text than they can reliably use. On the other hand, it has been shown that inference-time compute can be used to scale performance of LLMs, often by generating thinking tokens, on challenging tasks involving multi-step reasoning. Through controlled experiments on sandbox long-context tasks, we find that such inference-time strategies show rapidly diminishing returns and fail at long context. We attribute these failures to score dilution, a phenomenon inherent to static self-attention. Further, we show that current inference-time strategies cannot retrieve relevant long-context signals under certain conditions. We propose a simple method that, through targeted gradient updates on the given context, provably overcomes limitations of static self-attention. We find that this shift in how inference-time compute is spent leads to consistently large performance improvements across models and long-context benchmarks. Our method leads to large 12.6 and 14.1 percentage point improvements for Qwen3-4B on average across subsets of LongBench-v2 and ZeroScrolls benchmarks. The takeaway is practical: for long context, a small amount of context-specific training is a better use of inference compute than current inference-time scaling strategies like producing more thinking tokens.
Correlating and Predicting Human Evaluations of Language Models from Natural Language Processing Benchmarks
Feb 24, 2025



The explosion of high-performing conversational language models (LMs) has spurred a shift from classic natural language processing (NLP) benchmarks to expensive, time-consuming and noisy human evaluations - yet the relationship between these two evaluation strategies remains hazy. In this paper, we conduct a large-scale study of four Chat Llama 2 models, comparing their performance on 160 standard NLP benchmarks (e.g., MMLU, ARC, BIG-Bench Hard) against extensive human preferences on more than 11k single-turn and 2k multi-turn dialogues from over 2k human annotators. Our findings are striking: most NLP benchmarks strongly correlate with human evaluations, suggesting that cheaper, automated metrics can serve as surprisingly reliable predictors of human preferences. Three human evaluations, such as adversarial dishonesty and safety, are anticorrelated with NLP benchmarks, while two are uncorrelated. Moreover, through overparameterized linear regressions, we show that NLP scores can accurately predict human evaluations across different model scales, offering a path to reduce costly human annotation without sacrificing rigor. Overall, our results affirm the continued value of classic benchmarks and illuminate how to harness them to anticipate real-world user satisfaction - pointing to how NLP benchmarks can be leveraged to meet evaluation needs of our new era of conversational AI.
MLGym: A New Framework and Benchmark for Advancing AI Research Agents
Feb 20, 2025



We introduce Meta MLGym and MLGym-Bench, a new framework and benchmark for evaluating and developing LLM agents on AI research tasks. This is the first Gym environment for machine learning (ML) tasks, enabling research on reinforcement learning (RL) algorithms for training such agents. MLGym-bench consists of 13 diverse and open-ended AI research tasks from diverse domains such as computer vision, natural language processing, reinforcement learning, and game theory. Solving these tasks requires real-world AI research skills such as generating new ideas and hypotheses, creating and processing data, implementing ML methods, training models, running experiments, analyzing the results, and iterating through this process to improve on a given task. We evaluate a number of frontier large language models (LLMs) on our benchmarks such as Claude-3.5-Sonnet, Llama-3.1 405B, GPT-4o, o1-preview, and Gemini-1.5 Pro. Our MLGym framework makes it easy to add new tasks, integrate and evaluate models or agents, generate synthetic data at scale, as well as develop new learning algorithms for training agents on AI research tasks. We find that current frontier models can improve on the given baselines, usually by finding better hyperparameters, but do not generate novel hypotheses, algorithms, architectures, or substantial improvements. We open-source our framework and benchmark to facilitate future research in advancing the AI research capabilities of LLM agents.
HARP: A challenging human-annotated math reasoning benchmark
Dec 11, 2024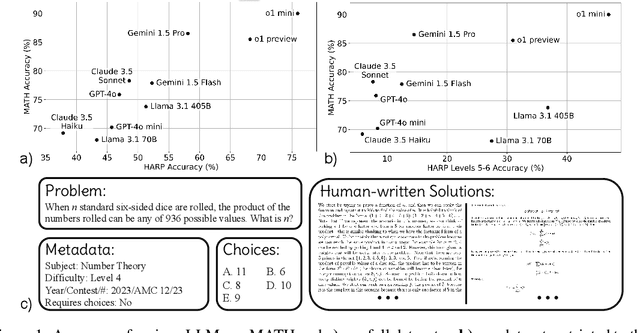

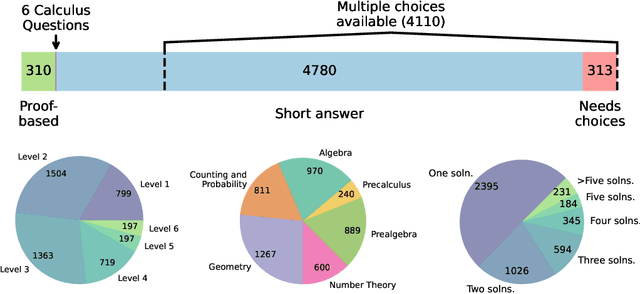

Math reasoning is becoming an ever increasing area of focus as we scale large language models. However, even the previously-toughest evals like MATH are now close to saturated by frontier models (90.0% for o1-mini and 86.5% for Gemini 1.5 Pro). We introduce HARP, Human Annotated Reasoning Problems (for Math), consisting of 5,409 problems from the US national math competitions (A(J)HSME, AMC, AIME, USA(J)MO). Of these, 4,780 have answers that are automatically check-able (with libraries such as SymPy). These problems range six difficulty levels, with frontier models performing relatively poorly on the hardest bracket of 197 problems (average accuracy 41.1% for o1-mini, and 9.6% for Gemini 1.5 Pro). Our dataset also features multiple choices (for 4,110 problems) and an average of two human-written, ground-truth solutions per problem, offering new avenues of research that we explore briefly. We report evaluations for many frontier models and share some interesting analyses, such as demonstrating that frontier models across families intrinsically scale their inference-time compute for more difficult problems. Finally, we open source all code used for dataset construction (including scraping) and all code for evaluation (including answer checking) to enable future research at: https://github.com/aadityasingh/HARP.
Lost in Inference: Rediscovering the Role of Natural Language Inference for Large Language Models
Nov 21, 2024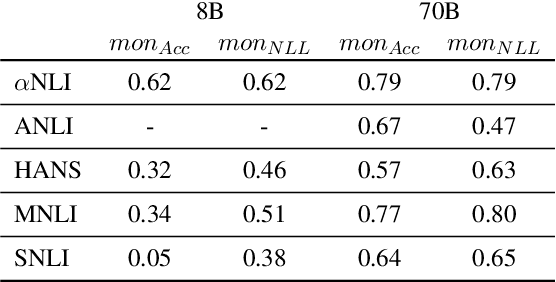
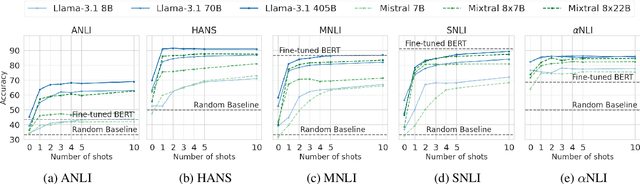
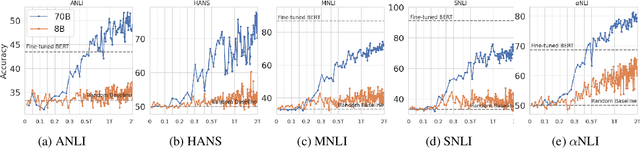

In the recent past, a popular way of evaluating natural language understanding (NLU), was to consider a model's ability to perform natural language inference (NLI) tasks. In this paper, we investigate if NLI tasks, that are rarely used for LLM evaluation, can still be informative for evaluating LLMs. Focusing on five different NLI benchmarks across six models of different scales, we investigate if they are able to discriminate models of different size and quality and how their accuracies develop during training. Furthermore, we investigate the extent to which the softmax distributions of models align with human distributions in cases where statements are ambiguous or vague. Overall, our results paint a positive picture for the NLI tasks: we find that they are able to discriminate well between models at various stages of training, yet are not (all) saturated. Furthermore, we find that while the similarity of model distributions with human label distributions increases with scale, it is still much higher than the similarity between two populations of humans, making it a potentially interesting statistic to consider.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Quantifying Variance in Evaluation Benchmarks
Jun 14, 2024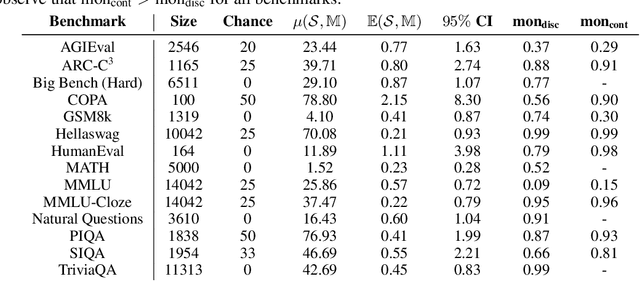
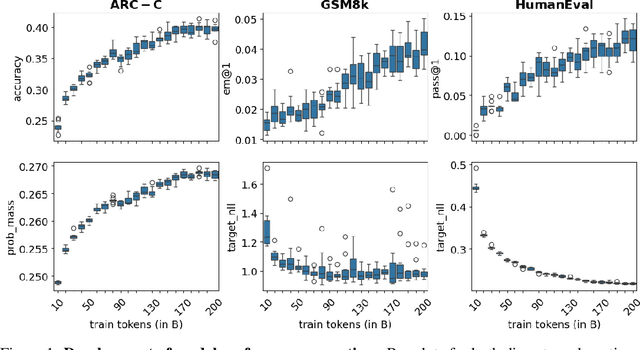
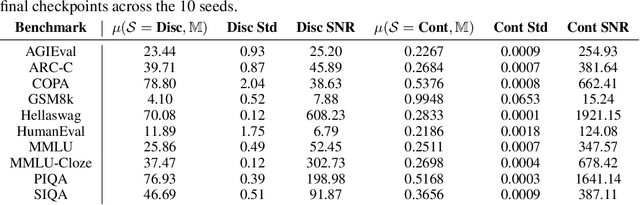
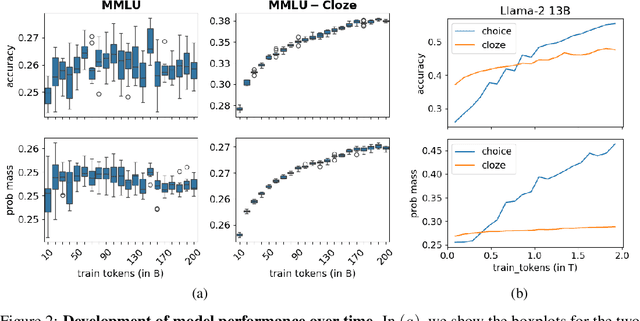
Evaluation benchmarks are the cornerstone of measuring capabilities of large language models (LLMs), as well as driving progress in said capabilities. Originally designed to make claims about capabilities (or lack thereof) in fully pretrained models, evaluation benchmarks are now also extensively used to decide between various training choices. Despite this widespread usage, we rarely quantify the variance in our evaluation benchmarks, which dictates whether differences in performance are meaningful. Here, we define and measure a range of metrics geared towards measuring variance in evaluation benchmarks, including seed variance across initialisations, and monotonicity during training. By studying a large number of models -- both openly available and pretrained from scratch -- we provide empirical estimates for a variety of variance metrics, with considerations and recommendations for practitioners. We also evaluate the utility and tradeoffs of continuous versus discrete performance measures and explore options for better understanding and reducing this variance. We find that simple changes, such as framing choice tasks (like MMLU) as completion tasks, can often reduce variance for smaller scale ($\sim$7B) models, while more involved methods inspired from human testing literature (such as item analysis and item response theory) struggle to meaningfully reduce variance. Overall, our work provides insights into variance in evaluation benchmarks, suggests LM-specific techniques to reduce variance, and more generally encourages practitioners to carefully factor in variance when comparing models.
Treeformer: Dense Gradient Trees for Efficient Attention Computation
Aug 18, 2022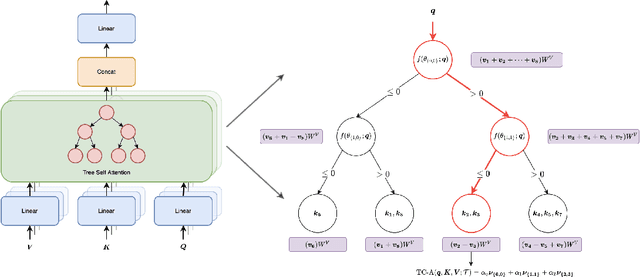
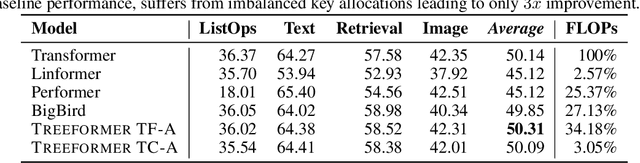
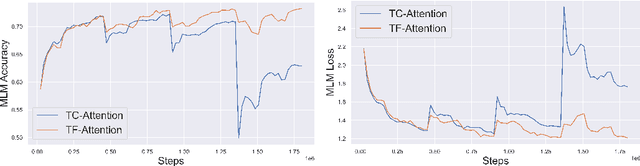
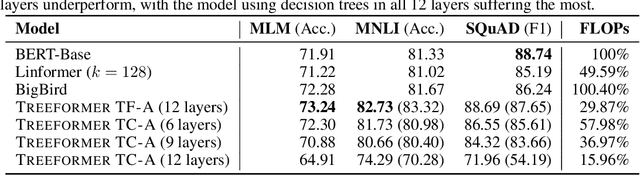
Standard inference and training with transformer based architectures scale quadratically with input sequence length. This is prohibitively large for a variety of applications especially in web-page translation, query-answering etc. Consequently, several approaches have been developed recently to speedup attention computation by enforcing different attention structures such as sparsity, low-rank, approximating attention using kernels. In this work, we view attention computation as that of nearest neighbor retrieval, and use decision tree based hierarchical navigation to reduce the retrieval cost per query token from linear in sequence length to nearly logarithmic. Based on such hierarchical navigation, we design Treeformer which can use one of two efficient attention layers -- TF-Attention and TC-Attention. TF-Attention computes the attention in a fine-grained style, while TC-Attention is a coarse attention layer which also ensures that the gradients are "dense". To optimize such challenging discrete layers, we propose a two-level bootstrapped training method. Using extensive experiments on standard NLP benchmarks, especially for long-sequences, we demonstrate that our Treeformer architecture can be almost as accurate as baseline Transformer while using 30x lesser FLOPs in the attention layer. Compared to Linformer, the accuracy can be as much as 12% higher while using similar FLOPs in the attention layer.
Field Study in Deploying Restless Multi-Armed Bandits: Assisting Non-Profits in Improving Maternal and Child Health
Sep 16, 2021
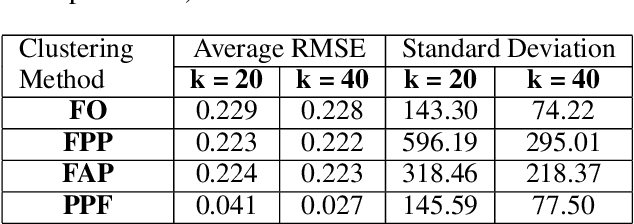
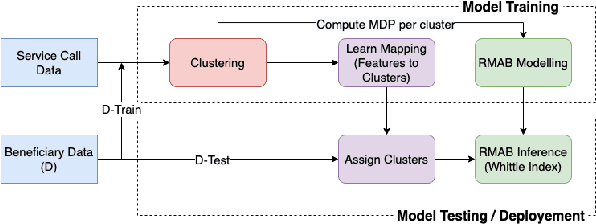
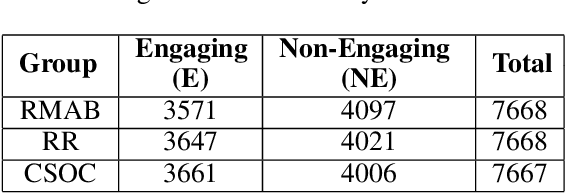
The widespread availability of cell phones has enabled non-profits to deliver critical health information to their beneficiaries in a timely manner. This paper describes our work to assist non-profits that employ automated messaging programs to deliver timely preventive care information to beneficiaries (new and expecting mothers) during pregnancy and after delivery. Unfortunately, a key challenge in such information delivery programs is that a significant fraction of beneficiaries drop out of the program. Yet, non-profits often have limited health-worker resources (time) to place crucial service calls for live interaction with beneficiaries to prevent such engagement drops. To assist non-profits in optimizing this limited resource, we developed a Restless Multi-Armed Bandits (RMABs) system. One key technical contribution in this system is a novel clustering method of offline historical data to infer unknown RMAB parameters. Our second major contribution is evaluation of our RMAB system in collaboration with an NGO, via a real-world service quality improvement study. The study compared strategies for optimizing service calls to 23003 participants over a period of 7 weeks to reduce engagement drops. We show that the RMAB group provides statistically significant improvement over other comparison groups, reducing ~ 30% engagement drops. To the best of our knowledge, this is the first study demonstrating the utility of RMABs in real world public health settings. We are transitioning our RMAB system to the NGO for real-world use.