 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's (not) just put things in Context: Test-Time Training for Long-Context LLMs
Dec 15, 2025Progress on training and architecture strategies has enabled LLMs with millions of tokens in context length. However, empirical evidence suggests that such long-context LLMs can consume far more text than they can reliably use. On the other hand, it has been shown that inference-time compute can be used to scale performance of LLMs, often by generating thinking tokens, on challenging tasks involving multi-step reasoning. Through controlled experiments on sandbox long-context tasks, we find that such inference-time strategies show rapidly diminishing returns and fail at long context. We attribute these failures to score dilution, a phenomenon inherent to static self-attention. Further, we show that current inference-time strategies cannot retrieve relevant long-context signals under certain conditions. We propose a simple method that, through targeted gradient updates on the given context, provably overcomes limitations of static self-attention. We find that this shift in how inference-time compute is spent leads to consistently large performance improvements across models and long-context benchmarks. Our method leads to large 12.6 and 14.1 percentage point improvements for Qwen3-4B on average across subsets of LongBench-v2 and ZeroScrolls benchmarks. The takeaway is practical: for long context, a small amount of context-specific training is a better use of inference compute than current inference-time scaling strategies like producing more thinking tokens.
LLM Augmented LLMs: Expanding Capabilities through Composition
Jan 04, 2024



Foundational models with billions of parameters which have been trained on large corpora of data have demonstrated non-trivial skills in a variety of domains. However, due to their monolithic structure, it is challenging and expensive to augment them or impart new skills. On the other hand, due to their adaptation abilities, several new instances of these models are being trained towards new domains and tasks. In this work, we study the problem of efficient and practical composition of existing foundation models with more specific models to enable newer capabilities. To this end, we propose CALM -- Composition to Augment Language Models -- which introduces cross-attention between models to compose their representations and enable new capabilities. Salient features of CALM are: (i) Scales up LLMs on new tasks by 're-using' existing LLMs along with a few additional parameters and data, (ii) Existing model weights are kept intact, and hence preserves existing capabilities, and (iii) Applies to diverse domains and settings. We illustrate that augmenting PaLM2-S with a smaller model trained on low-resource languages results in an absolute improvement of up to 13\% on tasks like translation into English and arithmetic reasoning for low-resource languages. Similarly, when PaLM2-S is augmented with a code-specific model, we see a relative improvement of 40\% over the base model for code generation and explanation tasks -- on-par with fully fine-tuned counterparts.
Measures of Information Reflect Memorization Patterns
Oct 19, 2022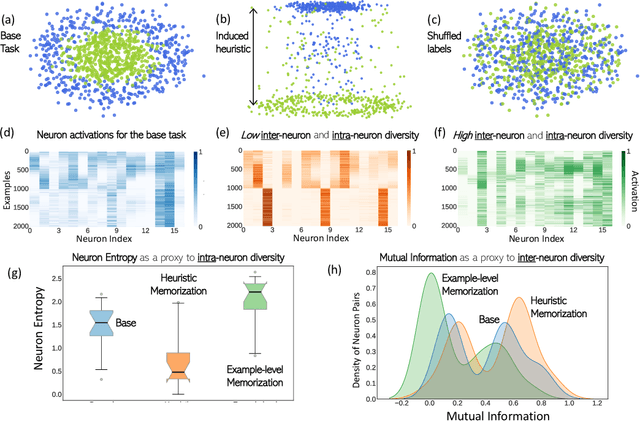


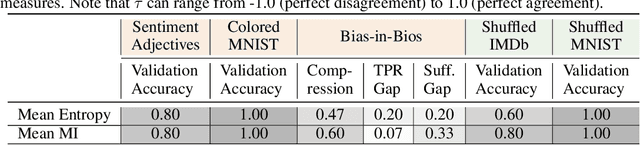
Neural networks are known to exploit spurious artifacts (or shortcuts) that co-occur with a target label, exhibiting heuristic memorization. On the other hand, networks have been shown to memorize training examples, resulting in example-level memorization. These kinds of memorization impede generalization of networks beyond their training distributions. Detecting such memorization could be challenging, often requiring researchers to curate tailored test sets. In this work, we hypothesize -- and subsequently show -- that the diversity in the activation patterns of different neurons is reflective of model generalization and memorization. We quantify the diversity in the neural activations through information-theoretic measures and find support for our hypothesis on experiments spanning several natural language and vision tasks. Importantly, we discover that information organization points to the two forms of memorization, even for neural activations computed on unlabeled in-distribution examples. Lastly, we demonstrate the utility of our findings for the problem of model selection. The associated code and other resources for this work are available at https://linktr.ee/InformationMeasures .
LM-CORE: Language Models with Contextually Relevant External Knowledge
Aug 12, 2022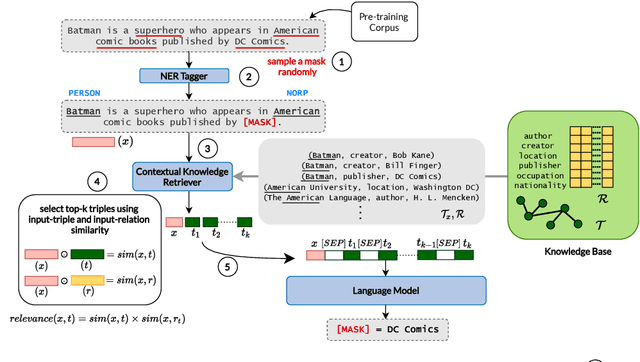
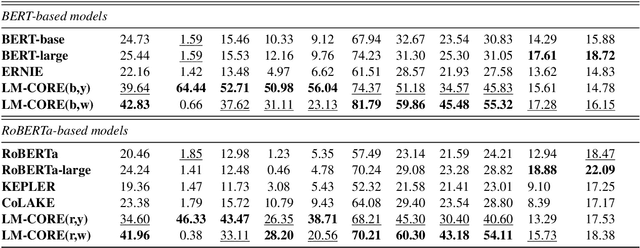

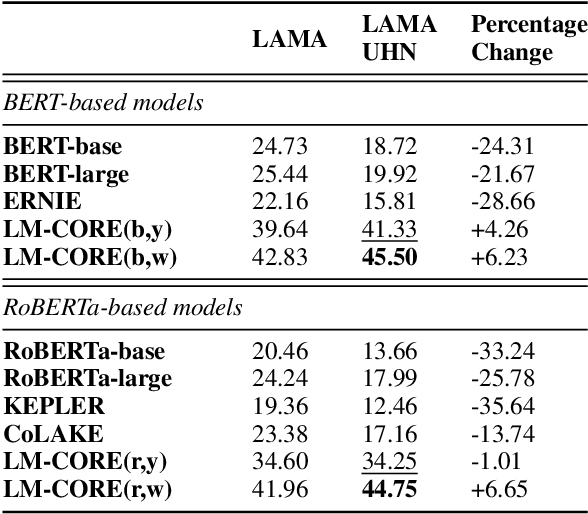
Large transformer-based pre-trained language models have achieved impressive performance on a variety of knowledge-intensive tasks and can capture factual knowledge in their parameters. We argue that storing large amounts of knowledge in the model parameters is sub-optimal given the ever-growing amounts of knowledge and resource requirements. We posit that a more efficient alternative is to provide explicit access to contextually relevant structured knowledge to the model and train it to use that knowledge. We present LM-CORE -- a general framework to achieve this -- that allows \textit{decoupling} of the language model training from the external knowledge source and allows the latter to be updated without affecting the already trained model. Experimental results show that LM-CORE, having access to external knowledge, achieves significant and robust outperformance over state-of-the-art knowledge-enhanced language models on knowledge probing tasks; can effectively handle knowledge updates; and performs well on two downstream tasks. We also present a thorough error analysis highlighting the successes and failures of LM-CORE.
CoSe-Co: Text Conditioned Generative CommonSense Contextualizer
Jun 17, 2022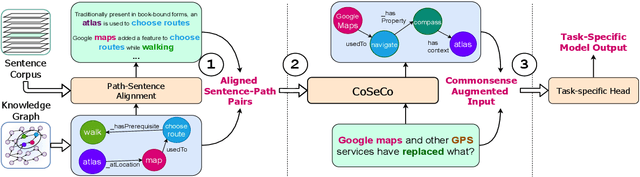

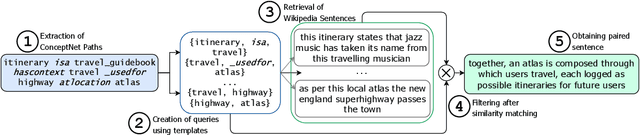
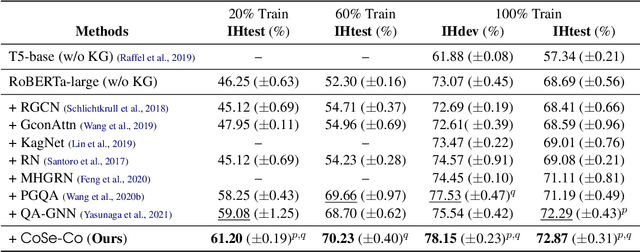
Pre-trained Language Models (PTLMs) have been shown to perform well on natural language tasks. Many prior works have leveraged structured commonsense present in the form of entities linked through labeled relations in Knowledge Graphs (KGs) to assist PTLMs. Retrieval approaches use KG as a separate static module which limits coverage since KGs contain finite knowledge. Generative methods train PTLMs on KG triples to improve the scale at which knowledge can be obtained. However, training on symbolic KG entities limits their applicability in tasks involving natural language text where they ignore overall context. To mitigate this, we propose a CommonSense Contextualizer (CoSe-Co) conditioned on sentences as input to make it generically usable in tasks for generating knowledge relevant to the overall context of input text. To train CoSe-Co, we propose a novel dataset comprising of sentence and commonsense knowledge pairs. The knowledge inferred by CoSe-Co is diverse and contain novel entities not present in the underlying KG. We augment generated knowledge in Multi-Choice QA and Open-ended CommonSense Reasoning tasks leading to improvements over current best methods on CSQA, ARC, QASC and OBQA datasets. We also demonstrate its applicability in improving performance of a baseline model for paraphrase generation task.
Linear Connectivity Reveals Generalization Strategies
May 24, 2022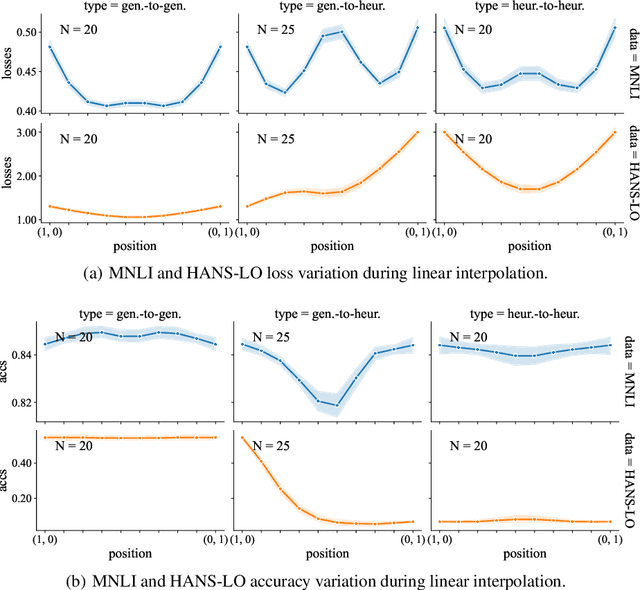
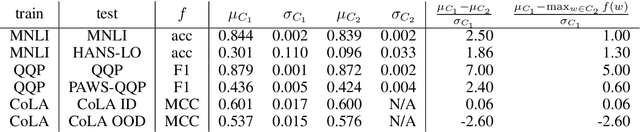
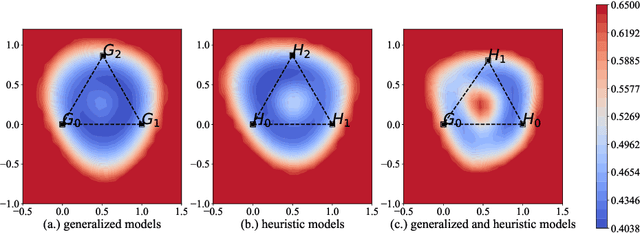
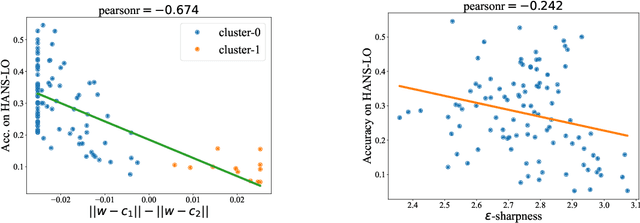
It is widely accepted in the mode connectivity literature that when two neural networks are trained similarly on the same data, they are connected by a path through parameter space over which test set accuracy is maintained. Under some circumstances, including transfer learning from pretrained models, these paths are presumed to be linear. In contrast to existing results, we find that among text classifiers (trained on MNLI, QQP, and CoLA), some pairs of finetuned models have large barriers of increasing loss on the linear paths between them. On each task, we find distinct clusters of models which are linearly connected on the test loss surface, but are disconnected from models outside the cluster -- models that occupy separate basins on the surface. By measuring performance on specially-crafted diagnostic datasets, we find that these clusters correspond to different generalization strategies: one cluster behaves like a bag of words model under domain shift, while another cluster uses syntactic heuristics. Our work demonstrates how the geometry of the loss surface can guide models towards different heuristic functions.
How Low is Too Low? A Computational Perspective on Extremely Low-Resource Languages
May 30, 2021
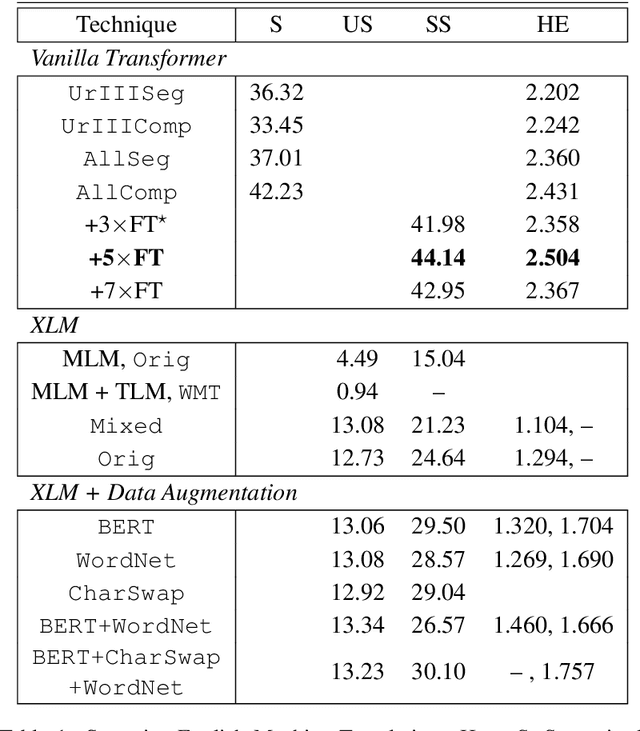
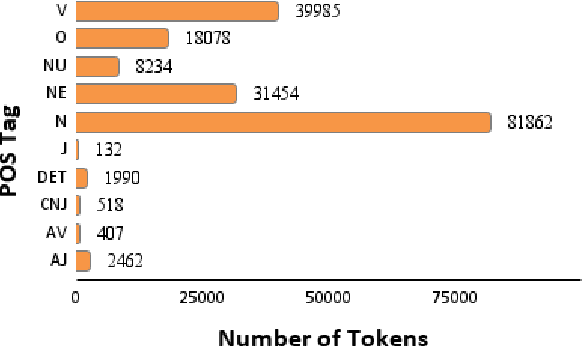
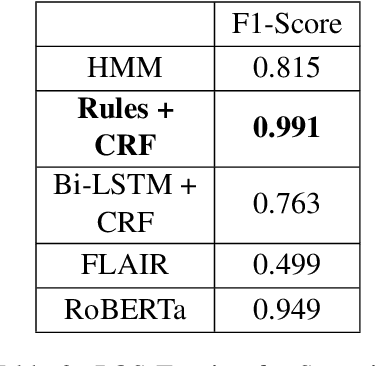
Despite the recent advancements of attention-based deep learning architectures across a majority of Natural Language Processing tasks, their application remains limited in a low-resource setting because of a lack of pre-trained models for such languages. In this study, we make the first attempt to investigate the challenges of adapting these techniques for an extremely low-resource language -- Sumerian cuneiform -- one of the world's oldest written languages attested from at least the beginning of the 3rd millennium BC. Specifically, we introduce the first cross-lingual information extraction pipeline for Sumerian, which includes part-of-speech tagging, named entity recognition, and machine translation. We further curate InterpretLR, an interpretability toolkit for low-resource NLP, and use it alongside human attributions to make sense of the models. We emphasize on human evaluations to gauge all our techniques. Notably, most components of our pipeline can be generalised to any other language to obtain an interpretable execution of the techniques, especially in a low-resource setting. We publicly release all software, model checkpoints, and a novel dataset with domain-specific pre-processing to promote further research.
Combining exogenous and endogenous signals with a semi-supervised co-attention network for early detection of COVID-19 fake tweets
Apr 12, 2021
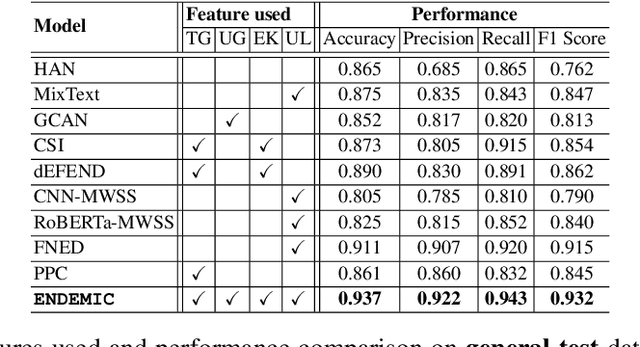

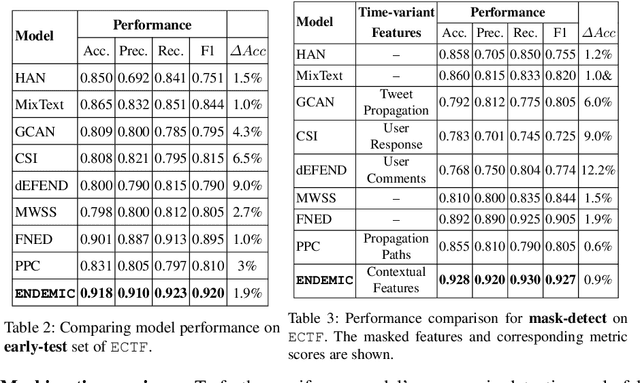
Fake tweets are observed to be ever-increasing, demanding immediate countermeasures to combat their spread. During COVID-19, tweets with misinformation should be flagged and neutralized in their early stages to mitigate the damages. Most of the existing methods for early detection of fake news assume to have enough propagation information for large labeled tweets -- which may not be an ideal setting for cases like COVID-19 where both aspects are largely absent. In this work, we present ENDEMIC, a novel early detection model which leverages exogenous and endogenous signals related to tweets, while learning on limited labeled data. We first develop a novel dataset, called CTF for early COVID-19 Twitter fake news, with additional behavioral test sets to validate early detection. We build a heterogeneous graph with follower-followee, user-tweet, and tweet-retweet connections and train a graph embedding model to aggregate propagation information. Graph embeddings and contextual features constitute endogenous, while time-relative web-scraped information constitutes exogenous signals. ENDEMIC is trained in a semi-supervised fashion, overcoming the challenge of limited labeled data. We propose a co-attention mechanism to fuse signal representations optimally. Experimental results on ECTF, PolitiFact, and GossipCop show that ENDEMIC is highly reliable in detecting early fake tweets, outperforming nine state-of-the-art methods significantly.
Cross-SEAN: A Cross-Stitch Semi-Supervised Neural Attention Model for COVID-19 Fake News Detection
Feb 18, 2021
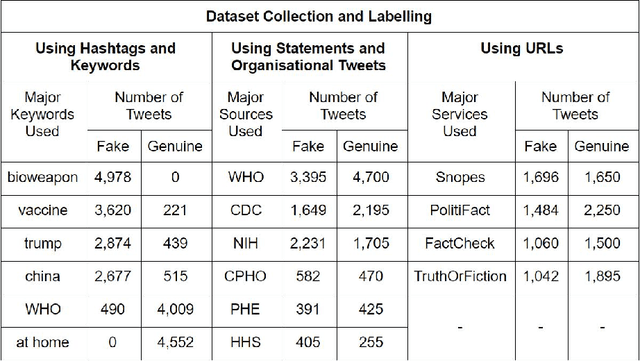
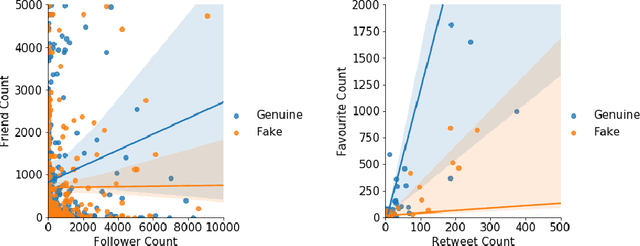
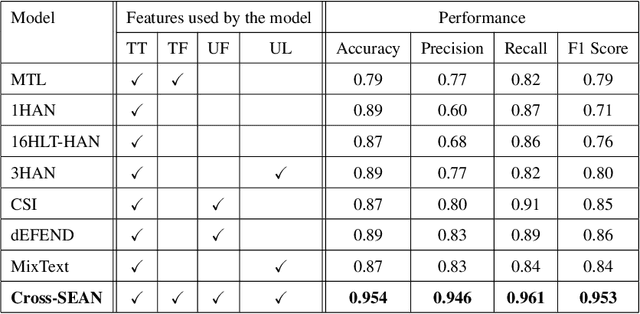
As the COVID-19 pandemic sweeps across the world, it has been accompanied by a tsunami of fake news and misinformation on social media. At the time when reliable information is vital for public health and safety, COVID-19 related fake news has been spreading even faster than the facts. During times such as the COVID-19 pandemic, fake news can not only cause intellectual confusion but can also place lives of people at risk. This calls for an immediate need to contain the spread of such misinformation on social media. We introduce CTF, the first COVID-19 Twitter fake news dataset with labeled genuine and fake tweets. Additionally, we propose Cross-SEAN, a cross-stitch based semi-supervised end-to-end neural attention model, which leverages the large amount of unlabelled data. Cross-SEAN partially generalises to emerging fake news as it learns from relevant external knowledge. We compare Cross-SEAN with seven state-of-the-art fake news detection methods. We observe that it achieves $0.95$ F1 Score on CTF, outperforming the best baseline by $9\%$. We also develop Chrome-SEAN, a Cross-SEAN based chrome extension for real-time detection of fake tweets.