 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining exogenous and endogenous signals with a semi-supervised co-attention network for early detection of COVID-19 fake tweets
Apr 12, 2021
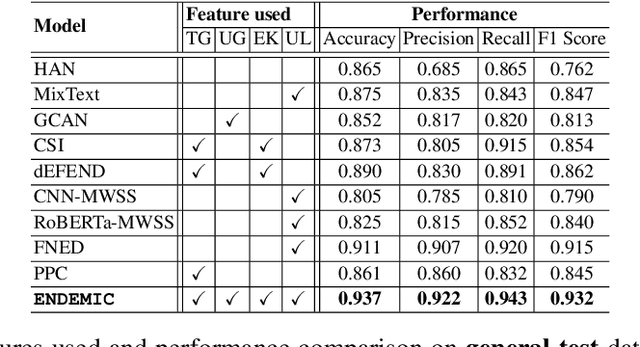

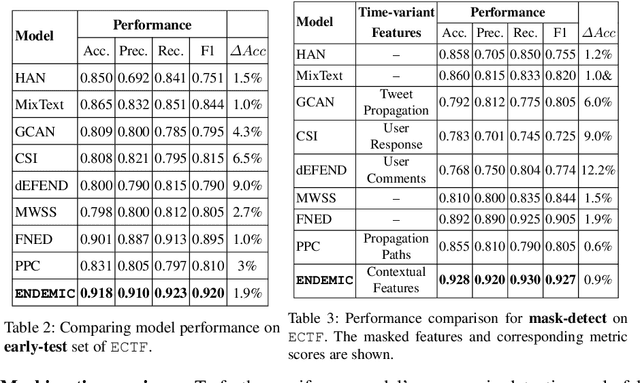
Fake tweets are observed to be ever-increasing, demanding immediate countermeasures to combat their spread. During COVID-19, tweets with misinformation should be flagged and neutralized in their early stages to mitigate the damages. Most of the existing methods for early detection of fake news assume to have enough propagation information for large labeled tweets -- which may not be an ideal setting for cases like COVID-19 where both aspects are largely absent. In this work, we present ENDEMIC, a novel early detection model which leverages exogenous and endogenous signals related to tweets, while learning on limited labeled data. We first develop a novel dataset, called CTF for early COVID-19 Twitter fake news, with additional behavioral test sets to validate early detection. We build a heterogeneous graph with follower-followee, user-tweet, and tweet-retweet connections and train a graph embedding model to aggregate propagation information. Graph embeddings and contextual features constitute endogenous, while time-relative web-scraped information constitutes exogenous signals. ENDEMIC is trained in a semi-supervised fashion, overcoming the challenge of limited labeled data. We propose a co-attention mechanism to fuse signal representations optimally. Experimental results on ECTF, PolitiFact, and GossipCop show that ENDEMIC is highly reliable in detecting early fake tweets, outperforming nine state-of-the-art methods significantly.
An Embedding-based Joint Sentiment-Topic Model for Short Texts
Mar 26, 2021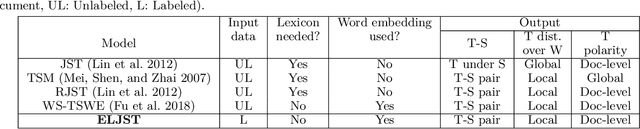
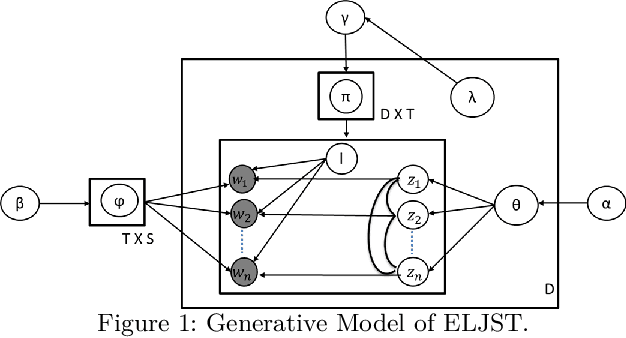

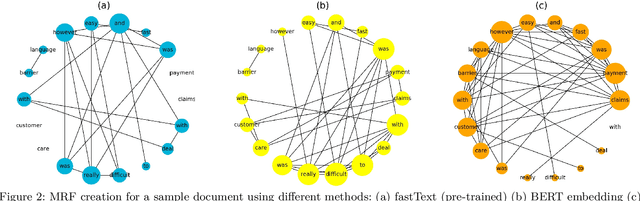
Short text is a popular avenue of sharing feedback, opinions and reviews on social media, e-commerce platforms, etc. Many companies need to extract meaningful information (which may include thematic content as well as semantic polarity) out of such short texts to understand users' behaviour. However, obtaining high quality sentiment-associated and human interpretable themes still remains a challenge for short texts. In this paper we develop ELJST, an embedding enhanced generative joint sentiment-topic model that can discover more coherent and diverse topics from short texts. It uses Markov Random Field Regularizer that can be seen as a generalisation of skip-gram based models. Further, it can leverage higher-order semantic information appearing in word embedding, such as self-attention weights in graphical models. Our results show an average improvement of 10% in topic coherence and 5% in topic diversification over baselines. Finally, ELJST helps understand users' behaviour at more granular levels which can be explained. All these can bring significant values to the service and healthcare industries often dealing with customers.
Cross-SEAN: A Cross-Stitch Semi-Supervised Neural Attention Model for COVID-19 Fake News Detection
Feb 18, 2021
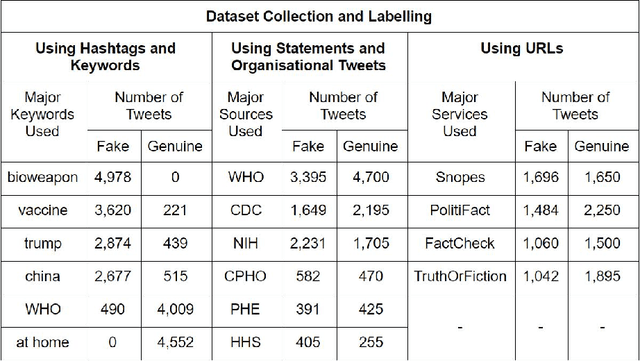
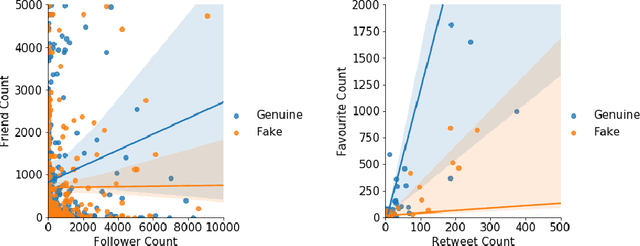
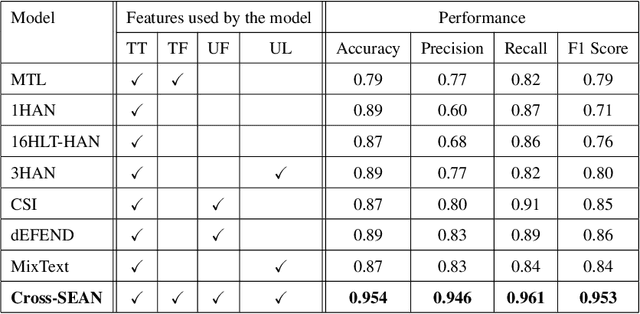
As the COVID-19 pandemic sweeps across the world, it has been accompanied by a tsunami of fake news and misinformation on social media. At the time when reliable information is vital for public health and safety, COVID-19 related fake news has been spreading even faster than the facts. During times such as the COVID-19 pandemic, fake news can not only cause intellectual confusion but can also place lives of people at risk. This calls for an immediate need to contain the spread of such misinformation on social media. We introduce CTF, the first COVID-19 Twitter fake news dataset with labeled genuine and fake tweets. Additionally, we propose Cross-SEAN, a cross-stitch based semi-supervised end-to-end neural attention model, which leverages the large amount of unlabelled data. Cross-SEAN partially generalises to emerging fake news as it learns from relevant external knowledge. We compare Cross-SEAN with seven state-of-the-art fake news detection methods. We observe that it achieves $0.95$ F1 Score on CTF, outperforming the best baseline by $9\%$. We also develop Chrome-SEAN, a Cross-SEAN based chrome extension for real-time detection of fake tweets.
Multitask Learning for Blackmarket Tweet Detection
Jul 09, 2019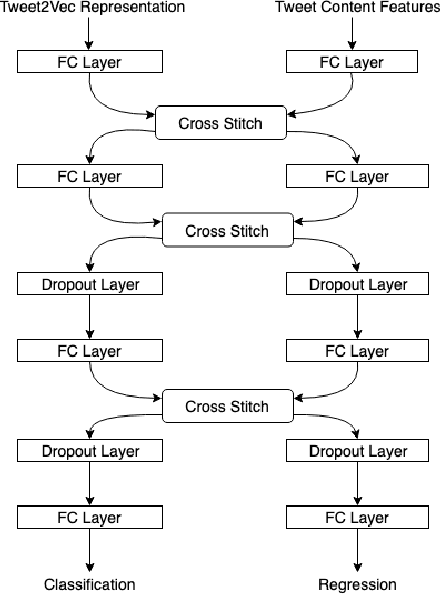
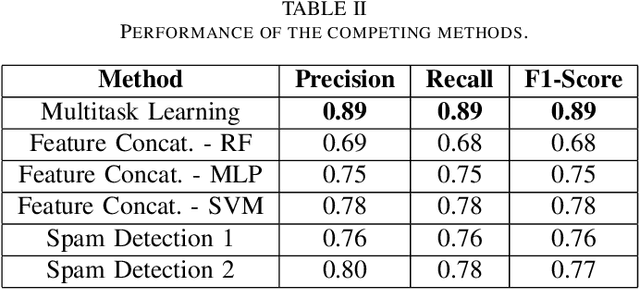
Online social media platforms have made the world more connected than ever before, thereby making it easier for everyone to spread their content across a wide variety of audiences. Twitter is one such popular platform where people publish tweets to spread their messages to everyone. Twitter allows users to Retweet other users' tweets in order to broadcast it to their network. The more retweets a particular tweet gets, the faster it spreads. This creates incentives for people to obtain artificial growth in the reach of their tweets by using certain blackmarket services to gain inorganic appraisals for their content. In this paper, we attempt to detect such tweets that have been posted on these blackmarket services in order to gain artificially boosted retweets. We use a multitask learning framework to leverage soft parameter sharing between a classification and a regression based task on separate inputs. This allows us to effectively detect tweets that have been posted to these blackmarket services, achieving an F1-score of 0.89 when classifying tweets as blackmarket or genuine.