 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOFAR: Commonsense and Factual Reasoning in Image Search
Oct 16, 2022

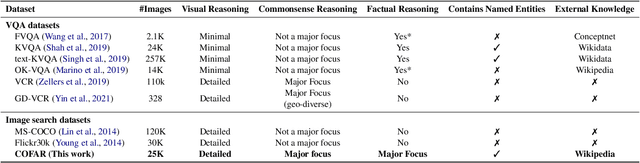
One characteristic that makes humans superior to modern artificially intelligent models is the ability to interpret images beyond what is visually apparent. Consider the following two natural language search queries - (i) "a queue of customers patiently waiting to buy ice cream" and (ii) "a queue of tourists going to see a famous Mughal architecture in India." Interpreting these queries requires one to reason with (i) Commonsense such as interpreting people as customers or tourists, actions as waiting to buy or going to see; and (ii) Fact or world knowledge associated with named visual entities, for example, whether the store in the image sells ice cream or whether the landmark in the image is a Mughal architecture located in India. Such reasoning goes beyond just visual recognition. To enable both commonsense and factual reasoning in the image search, we present a unified framework, namely Knowledge Retrieval-Augmented Multimodal Transformer (KRAMT), that treats the named visual entities in an image as a gateway to encyclopedic knowledge and leverages them along with natural language query to ground relevant knowledge. Further, KRAMT seamlessly integrates visual content and grounded knowledge to learn alignment between images and search queries. This unified framework is then used to perform image search requiring commonsense and factual reasoning. The retrieval performance of KRAMT is evaluated and compared with related approaches on a new dataset we introduce - namely COFAR. We make our code and dataset available at https://vl2g.github.io/projects/cofar
Hollywood Identity Bias Dataset: A Context Oriented Bias Analysis of Movie Dialogues
Jun 01, 2022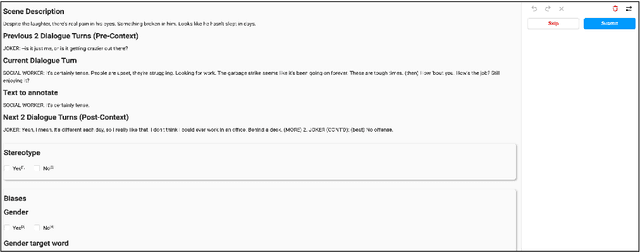



Movies reflect society and also hold power to transform opinions. Social biases and stereotypes present in movies can cause extensive damage due to their reach. These biases are not always found to be the need of storyline but can creep in as the author's bias. Movie production houses would prefer to ascertain that the bias present in a script is the story's demand. Today, when deep learning models can give human-level accuracy in multiple tasks, having an AI solution to identify the biases present in the script at the writing stage can help them avoid the inconvenience of stalled release, lawsuits, etc. Since AI solutions are data intensive and there exists no domain specific data to address the problem of biases in scripts, we introduce a new dataset of movie scripts that are annotated for identity bias. The dataset contains dialogue turns annotated for (i) bias labels for seven categories, viz., gender, race/ethnicity, religion, age, occupation, LGBTQ, and other, which contains biases like body shaming, personality bias, etc. (ii) labels for sensitivity, stereotype, sentiment, emotion, emotion intensity, (iii) all labels annotated with context awareness, (iv) target groups and reason for bias labels and (v) expert-driven group-validation process for high quality annotations. We also report various baseline performances for bias identification and category detection on our dataset.
An Inference Approach To Question Answering Over Knowledge Graphs
Dec 21, 2021
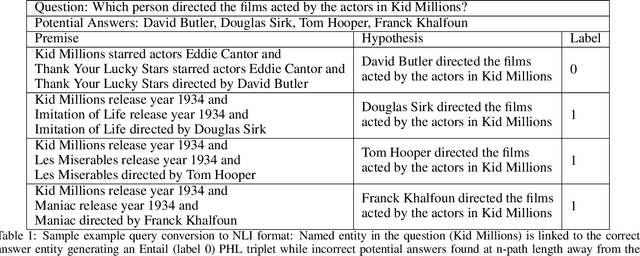
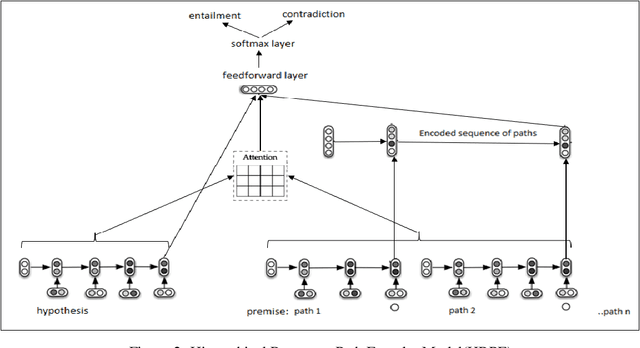
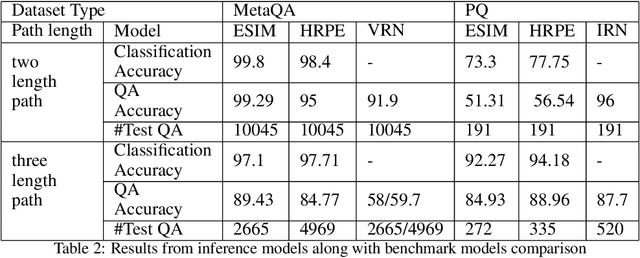
Knowledge Graphs (KG) act as a great tool for holding distilled information from large natural language text corpora. The problem of natural language querying over knowledge graphs is essential for the human consumption of this information. This problem is typically addressed by converting the natural language query to a structured query and then firing the structured query on the KG. Direct answering models over knowledge graphs in literature are very few. The query conversion models and direct models both require specific training data pertaining to the domain of the knowledge graph. In this work, we convert the problem of natural language querying over knowledge graphs to an inference problem over premise-hypothesis pairs. Using trained deep learning models for the converted proxy inferencing problem, we provide the solution for the original natural language querying problem. Our method achieves over 90% accuracy on MetaQA dataset, beating the existing state-of-the-art. We also propose a model for inferencing called Hierarchical Recurrent Path Encoder(HRPE). The inferencing models can be fine-tuned to be used across domains with less training data. Our approach does not require large domain-specific training data for querying on new knowledge graphs from different domains.
DESYR: Definition and Syntactic Representation Based Claim Detection on the Web
Aug 19, 2021
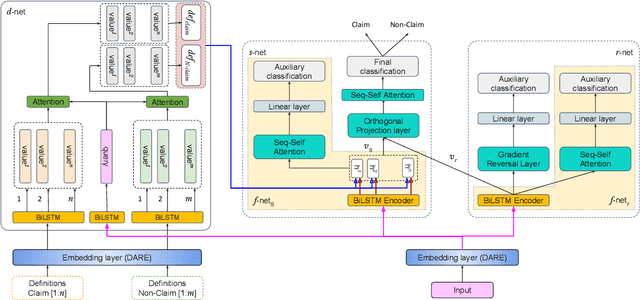
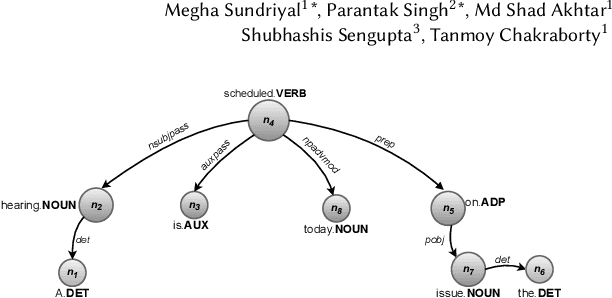

The formulation of a claim rests at the core of argument mining. To demarcate between a claim and a non-claim is arduous for both humans and machines, owing to latent linguistic variance between the two and the inadequacy of extensive definition-based formalization. Furthermore, the increase in the usage of online social media has resulted in an explosion of unsolicited information on the web presented as informal text. To account for the aforementioned, in this paper, we proposed DESYR. It is a framework that intends on annulling the said issues for informal web-based text by leveraging a combination of hierarchical representation learning (dependency-inspired Poincare embedding), definition-based alignment, and feature projection. We do away with fine-tuning computer-heavy language models in favor of fabricating a more domain-centric but lighter approach. Experimental results indicate that DESYR builds upon the state-of-the-art system across four benchmark claim datasets, most of which were constructed with informal texts. We see an increase of 3 claim-F1 points on the LESA-Twitter dataset, an increase of 1 claim-F1 point and 9 macro-F1 points on the Online Comments(OC) dataset, an increase of 24 claim-F1 points and 17 macro-F1 points on the Web Discourse(WD) dataset, and an increase of 8 claim-F1 points and 5 macro-F1 points on the Micro Texts(MT) dataset. We also perform an extensive analysis of the results. We make a 100-D pre-trained version of our Poincare-variant along with the source code.
Knowledge Graph Anchored Information-Extraction for Domain-Specific Insights
Apr 20, 2021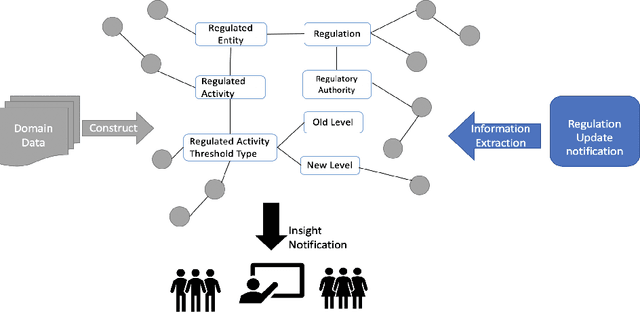
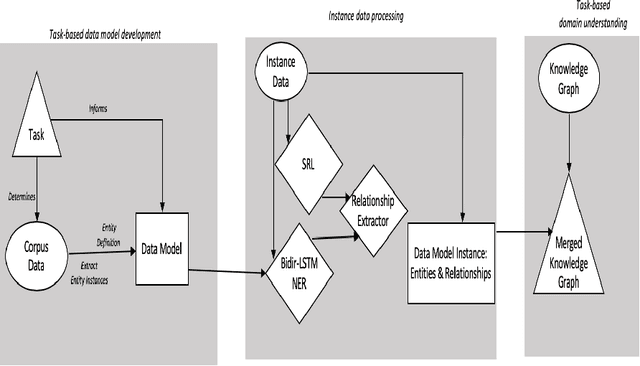
The growing quantity and complexity of data pose challenges for humans to consume information and respond in a timely manner. For businesses in domains with rapidly changing rules and regulations, failure to identify changes can be costly. In contrast to expert analysis or the development of domain-specific ontology and taxonomies, we use a task-based approach for fulfilling specific information needs within a new domain. Specifically, we propose to extract task-based information from incoming instance data. A pipeline constructed of state of the art NLP technologies, including a bi-LSTM-CRF model for entity extraction, attention-based deep Semantic Role Labeling, and an automated verb-based relationship extractor, is used to automatically extract an instance level semantic structure. Each instance is then combined with a larger, domain-specific knowledge graph to produce new and timely insights. Preliminary results, validated manually, show the methodology to be effective for extracting specific information to complete end use-cases.
Combining exogenous and endogenous signals with a semi-supervised co-attention network for early detection of COVID-19 fake tweets
Apr 12, 2021
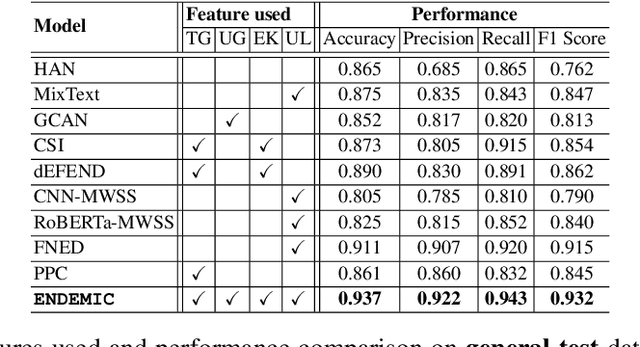

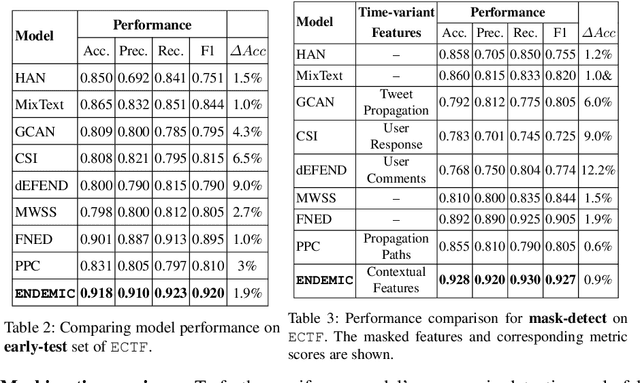
Fake tweets are observed to be ever-increasing, demanding immediate countermeasures to combat their spread. During COVID-19, tweets with misinformation should be flagged and neutralized in their early stages to mitigate the damages. Most of the existing methods for early detection of fake news assume to have enough propagation information for large labeled tweets -- which may not be an ideal setting for cases like COVID-19 where both aspects are largely absent. In this work, we present ENDEMIC, a novel early detection model which leverages exogenous and endogenous signals related to tweets, while learning on limited labeled data. We first develop a novel dataset, called CTF for early COVID-19 Twitter fake news, with additional behavioral test sets to validate early detection. We build a heterogeneous graph with follower-followee, user-tweet, and tweet-retweet connections and train a graph embedding model to aggregate propagation information. Graph embeddings and contextual features constitute endogenous, while time-relative web-scraped information constitutes exogenous signals. ENDEMIC is trained in a semi-supervised fashion, overcoming the challenge of limited labeled data. We propose a co-attention mechanism to fuse signal representations optimally. Experimental results on ECTF, PolitiFact, and GossipCop show that ENDEMIC is highly reliable in detecting early fake tweets, outperforming nine state-of-the-art methods significantly.
Cross-SEAN: A Cross-Stitch Semi-Supervised Neural Attention Model for COVID-19 Fake News Detection
Feb 18, 2021
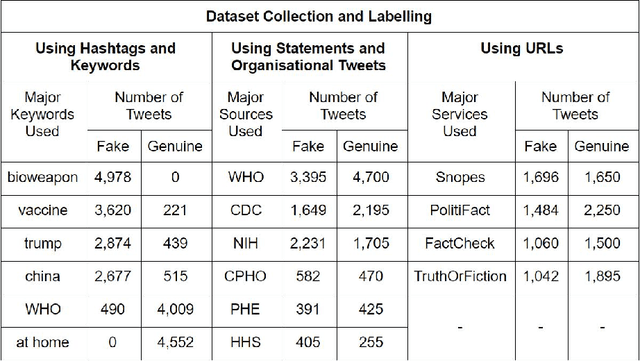
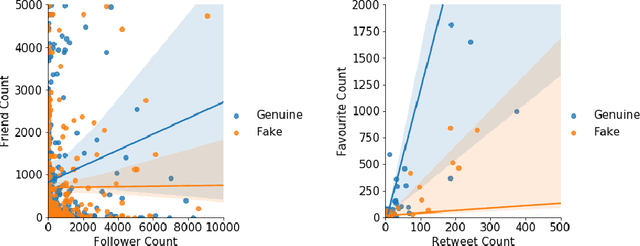
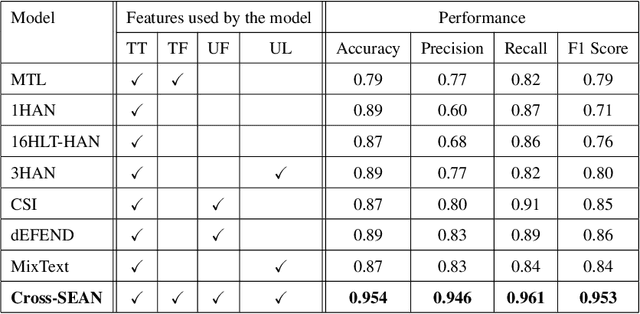
As the COVID-19 pandemic sweeps across the world, it has been accompanied by a tsunami of fake news and misinformation on social media. At the time when reliable information is vital for public health and safety, COVID-19 related fake news has been spreading even faster than the facts. During times such as the COVID-19 pandemic, fake news can not only cause intellectual confusion but can also place lives of people at risk. This calls for an immediate need to contain the spread of such misinformation on social media. We introduce CTF, the first COVID-19 Twitter fake news dataset with labeled genuine and fake tweets. Additionally, we propose Cross-SEAN, a cross-stitch based semi-supervised end-to-end neural attention model, which leverages the large amount of unlabelled data. Cross-SEAN partially generalises to emerging fake news as it learns from relevant external knowledge. We compare Cross-SEAN with seven state-of-the-art fake news detection methods. We observe that it achieves $0.95$ F1 Score on CTF, outperforming the best baseline by $9\%$. We also develop Chrome-SEAN, a Cross-SEAN based chrome extension for real-time detection of fake tweets.
Can Taxonomy Help? Improving Semantic Question Matching using Question Taxonomy
Jan 20, 2021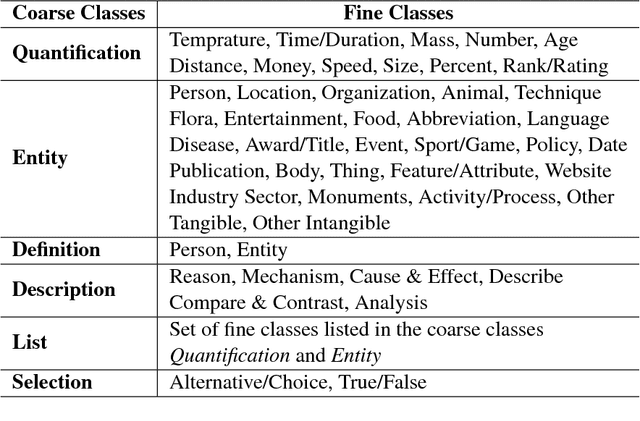
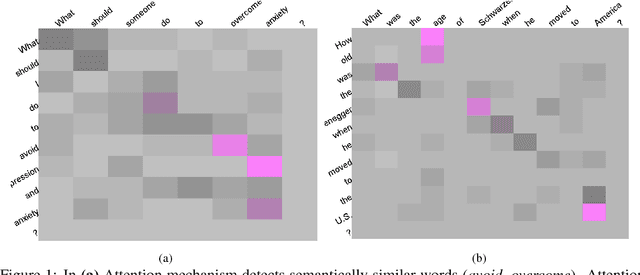
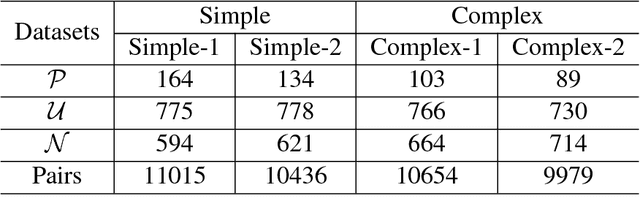
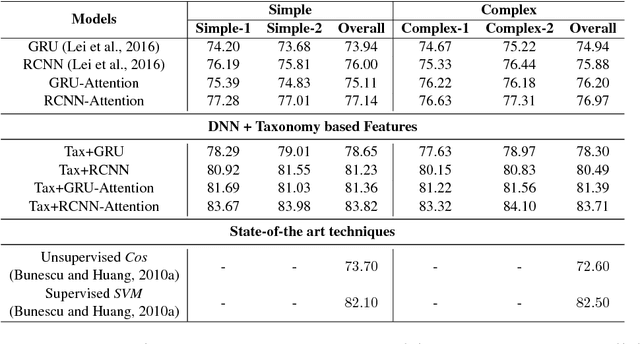
In this paper, we propose a hybrid technique for semantic question matching. It uses our proposed two-layered taxonomy for English questions by augmenting state-of-the-art deep learning models with question classes obtained from a deep learning based question classifier. Experiments performed on three open-domain datasets demonstrate the effectiveness of our proposed approach. We achieve state-of-the-art results on partial ordering question ranking (POQR) benchmark dataset. Our empirical analysis shows that coupling standard distributional features (provided by the question encoder) with knowledge from taxonomy is more effective than either deep learning (DL) or taxonomy-based knowledge alone.
Causal-BERT : Language models for causality detection between events expressed in text
Dec 10, 2020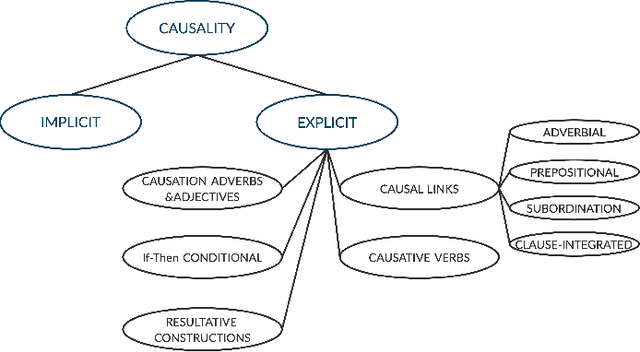



Causality understanding between events is a critical natural language processing task that is helpful in many areas, including health care, business risk management and finance. On close examination, one can find a huge amount of textual content both in the form of formal documents or in content arising from social media like Twitter, dedicated to communicating and exploring various types of causality in the real world. Recognizing these "Cause-Effect" relationships between natural language events continues to remain a challenge simply because it is often expressed implicitly. Implicit causality is hard to detect through most of the techniques employed in literature and can also, at times be perceived as ambiguous or vague. Also, although well-known datasets do exist for this problem, the examples in them are limited in the range and complexity of the causal relationships they depict especially when related to implicit relationships. Most of the contemporary methods are either based on lexico-semantic pattern matching or are feature-driven supervised methods. Therefore, as expected these methods are more geared towards handling explicit causal relationships leading to limited coverage for implicit relationships and are hard to generalize. In this paper, we investigate the language model's capabilities for causal association among events expressed in natural language text using sentence context combined with event information, and by leveraging masked event context with in-domain and out-of-domain data distribution. Our proposed methods achieve the state-of-art performance in three different data distributions and can be leveraged for extraction of a causal diagram and/or building a chain of events from unstructured text.
Intent Mining from past conversations for Conversational Agent
May 22, 2020
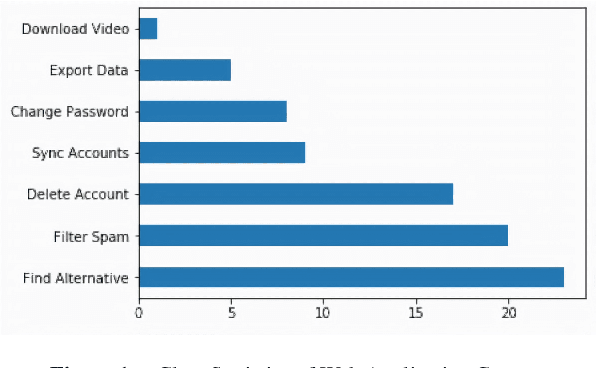
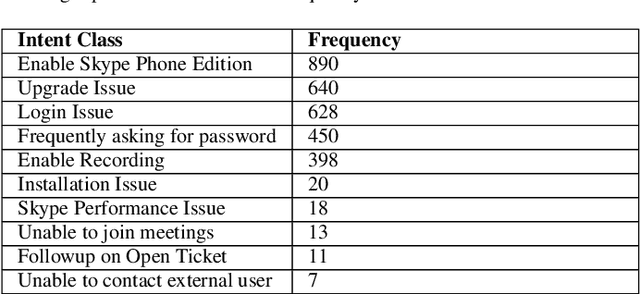
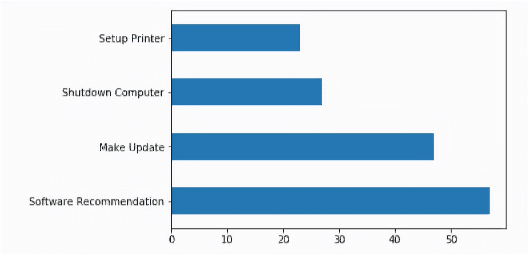
Conversational systems are of primary interest in the AI community. Chatbots are increasingly being deployed to provide round-the-clock support and to increase customer engagement. Many of the commercial bot building frameworks follow a standard approach that requires one to build and train an intent model to recognize a user input. Intent models are trained in a supervised setting with a collection of textual utterance and intent label pairs. Gathering a substantial and wide coverage of training data for different intent is a bottleneck in the bot building process. Moreover, the cost of labeling a hundred to thousands of conversations with intent is a time consuming and laborious job. In this paper, we present an intent discovery framework that involves 4 primary steps: Extraction of textual utterances from a conversation using a pre-trained domain agnostic Dialog Act Classifier (Data Extraction), automatic clustering of similar user utterances (Clustering), manual annotation of clusters with an intent label (Labeling) and propagation of intent labels to the utterances from the previous step, which are not mapped to any cluster (Label Propagation); to generate intent training data from raw conversations. We have introduced a novel density-based clustering algorithm ITER-DBSCAN for unbalanced data clustering. Subject Matter Expert (Annotators with domain expertise) manually looks into the clustered user utterances and provides an intent label for discovery. We conducted user studies to validate the effectiveness of the trained intent model generated in terms of coverage of intents, accuracy and time saving concerning manual annotation. Although the system is developed for building an intent model for the conversational system, this framework can also be used for a short text clustering or as a labeling framework.