 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Prompting for Conversational Tasks: A Comparative Analysis of Large Language Models Across Diverse Conversational Tasks
Nov 26, 2024



Given the advancements in conversational artificial intelligence, the evaluation and assessment of Large Language Models (LLMs) play a crucial role in ensuring optimal performance across various conversational tasks. In this paper, we present a comprehensive study that thoroughly evaluates the capabilities and limitations of five prevalent LLMs: Llama, OPT, Falcon, Alpaca, and MPT. The study encompasses various conversational tasks, including reservation, empathetic response generation, mental health and legal counseling, persuasion, and negotiation. To conduct the evaluation, an extensive test setup is employed, utilizing multiple evaluation criteria that span from automatic to human evaluation. This includes using generic and task-specific metrics to gauge the LMs' performance accurately. From our evaluation, no single model emerges as universally optimal for all tasks. Instead, their performance varies significantly depending on the specific requirements of each task. While some models excel in certain tasks, they may demonstrate comparatively poorer performance in others. These findings emphasize the importance of considering task-specific requirements and characteristics when selecting the most suitable LM for conversational applications.
INA: An Integrative Approach for Enhancing Negotiation Strategies with Reward-Based Dialogue System
Oct 27, 2023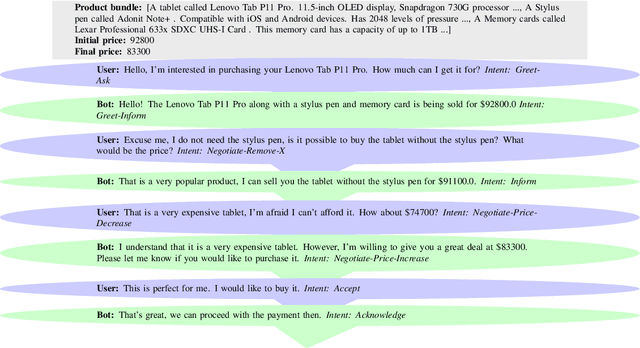


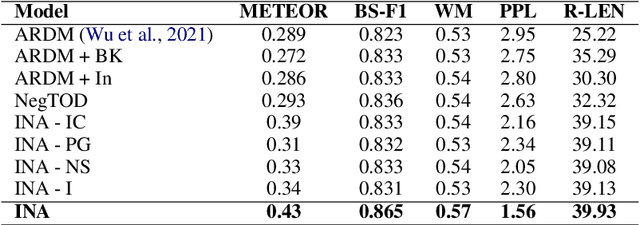
In this paper, we propose a novel negotiation dialogue agent designed for the online marketplace. Our agent is integrative in nature i.e, it possesses the capability to negotiate on price as well as other factors, such as the addition or removal of items from a deal bundle, thereby offering a more flexible and comprehensive negotiation experience. We create a new dataset called Integrative Negotiation Dataset (IND) to enable this functionality. For this dataset creation, we introduce a new semi-automated data creation method, which combines defining negotiation intents, actions, and intent-action simulation between users and the agent to generate potential dialogue flows. Finally, the prompting of GPT-J, a state-of-the-art language model, is done to generate dialogues for a given intent, with a human-in-the-loop process for post-editing and refining minor errors to ensure high data quality. We employ a set of novel rewards, specifically tailored for the negotiation task to train our Negotiation Agent, termed as the Integrative Negotiation Agent (INA). These rewards incentivize the chatbot to learn effective negotiation strategies that can adapt to various contextual requirements and price proposals. By leveraging the IND, we train our model and conduct experiments to evaluate the effectiveness of our reward-based dialogue system for negotiation. Our results demonstrate that the proposed approach and reward system significantly enhance the agent's negotiation capabilities. The INA successfully engages in integrative negotiations, displaying the ability to dynamically adjust prices and negotiate the inclusion or exclusion of items in a bundle deal
COFAR: Commonsense and Factual Reasoning in Image Search
Oct 16, 2022

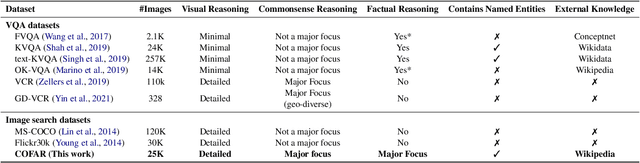
One characteristic that makes humans superior to modern artificially intelligent models is the ability to interpret images beyond what is visually apparent. Consider the following two natural language search queries - (i) "a queue of customers patiently waiting to buy ice cream" and (ii) "a queue of tourists going to see a famous Mughal architecture in India." Interpreting these queries requires one to reason with (i) Commonsense such as interpreting people as customers or tourists, actions as waiting to buy or going to see; and (ii) Fact or world knowledge associated with named visual entities, for example, whether the store in the image sells ice cream or whether the landmark in the image is a Mughal architecture located in India. Such reasoning goes beyond just visual recognition. To enable both commonsense and factual reasoning in the image search, we present a unified framework, namely Knowledge Retrieval-Augmented Multimodal Transformer (KRAMT), that treats the named visual entities in an image as a gateway to encyclopedic knowledge and leverages them along with natural language query to ground relevant knowledge. Further, KRAMT seamlessly integrates visual content and grounded knowledge to learn alignment between images and search queries. This unified framework is then used to perform image search requiring commonsense and factual reasoning. The retrieval performance of KRAMT is evaluated and compared with related approaches on a new dataset we introduce - namely COFAR. We make our code and dataset available at https://vl2g.github.io/projects/cofar
Hollywood Identity Bias Dataset: A Context Oriented Bias Analysis of Movie Dialogues
Jun 01, 2022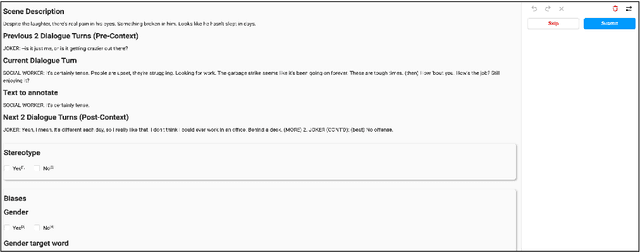



Movies reflect society and also hold power to transform opinions. Social biases and stereotypes present in movies can cause extensive damage due to their reach. These biases are not always found to be the need of storyline but can creep in as the author's bias. Movie production houses would prefer to ascertain that the bias present in a script is the story's demand. Today, when deep learning models can give human-level accuracy in multiple tasks, having an AI solution to identify the biases present in the script at the writing stage can help them avoid the inconvenience of stalled release, lawsuits, etc. Since AI solutions are data intensive and there exists no domain specific data to address the problem of biases in scripts, we introduce a new dataset of movie scripts that are annotated for identity bias. The dataset contains dialogue turns annotated for (i) bias labels for seven categories, viz., gender, race/ethnicity, religion, age, occupation, LGBTQ, and other, which contains biases like body shaming, personality bias, etc. (ii) labels for sensitivity, stereotype, sentiment, emotion, emotion intensity, (iii) all labels annotated with context awareness, (iv) target groups and reason for bias labels and (v) expert-driven group-validation process for high quality annotations. We also report various baseline performances for bias identification and category detection on our dataset.
Causal-BERT : Language models for causality detection between events expressed in text
Dec 10, 2020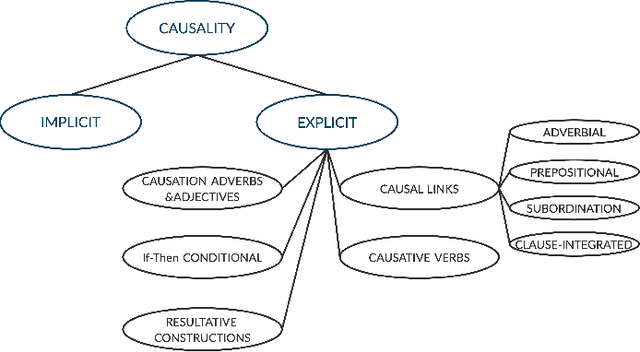



Causality understanding between events is a critical natural language processing task that is helpful in many areas, including health care, business risk management and finance. On close examination, one can find a huge amount of textual content both in the form of formal documents or in content arising from social media like Twitter, dedicated to communicating and exploring various types of causality in the real world. Recognizing these "Cause-Effect" relationships between natural language events continues to remain a challenge simply because it is often expressed implicitly. Implicit causality is hard to detect through most of the techniques employed in literature and can also, at times be perceived as ambiguous or vague. Also, although well-known datasets do exist for this problem, the examples in them are limited in the range and complexity of the causal relationships they depict especially when related to implicit relationships. Most of the contemporary methods are either based on lexico-semantic pattern matching or are feature-driven supervised methods. Therefore, as expected these methods are more geared towards handling explicit causal relationships leading to limited coverage for implicit relationships and are hard to generalize. In this paper, we investigate the language model's capabilities for causal association among events expressed in natural language text using sentence context combined with event information, and by leveraging masked event context with in-domain and out-of-domain data distribution. Our proposed methods achieve the state-of-art performance in three different data distributions and can be leveraged for extraction of a causal diagram and/or building a chain of events from unstructured text.