 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatientVLM Meets DocVLM: Pre-Consultation Dialogue Between Vision-Language Models for Efficient Diagnosis
Jan 16, 2026Traditionally, AI research in medical diagnosis has largely centered on image analysis. While this has led to notable advancements, the absence of patient-reported symptoms continues to hinder diagnostic accuracy. To address this, we propose a Pre-Consultation Dialogue Framework (PCDF) that mimics real-world diagnostic procedures, where doctors iteratively query patients before reaching a conclusion. Specifically, we simulate diagnostic dialogues between two vision-language models (VLMs): a DocVLM, which generates follow-up questions based on the image and dialogue history, and a PatientVLM, which responds using a symptom profile derived from the ground-truth diagnosis. We additionally conducted a small-scale clinical validation of the synthetic symptoms generated by our framework, with licensed clinicians confirming their clinical relevance, symptom coverage, and overall realism. These findings indicate that the resulting DocVLM-PatientVLM interactions form coherent, multi-turn consultations paired with images and diagnoses, which we then use to fine-tune the DocVLM. This dialogue-based supervision leads to substantial gains over image-only training, highlighting the value of realistic symptom elicitation for diagnosis.
Mind the (Language) Gap: Towards Probing Numerical and Cross-Lingual Limits of LVLMs
Aug 24, 2025



We introduce MMCRICBENCH-3K, a benchmark for Visual Question Answering (VQA) on cricket scorecards, designed to evaluate large vision-language models (LVLMs) on complex numerical and cross-lingual reasoning over semi-structured tabular images. MMCRICBENCH-3K comprises 1,463 synthetically generated scorecard images from ODI, T20, and Test formats, accompanied by 1,500 English QA pairs. It includes two subsets: MMCRICBENCH-E-1.5K, featuring English scorecards, and MMCRICBENCH-H-1.5K, containing visually similar Hindi scorecards, with all questions and answers kept in English to enable controlled cross-script evaluation. The task demands reasoning over structured numerical data, multi-image context, and implicit domain knowledge. Empirical results show that even state-of-the-art LVLMs, such as GPT-4o and Qwen2.5VL, struggle on the English subset despite it being their primary training language and exhibit a further drop in performance on the Hindi subset. This reveals key limitations in structure-aware visual text understanding, numerical reasoning, and cross-lingual generalization. The dataset is publicly available via Hugging Face at https://huggingface.co/datasets/DIALab/MMCricBench, to promote LVLM research in this direction.
Audiopedia: Audio QA with Knowledge
Dec 29, 2024In this paper, we introduce Audiopedia, a novel task called Audio Question Answering with Knowledge, which requires both audio comprehension and external knowledge reasoning. Unlike traditional Audio Question Answering (AQA) benchmarks that focus on simple queries answerable from audio alone, Audiopedia targets knowledge-intensive questions. We define three sub-tasks: (i) Single Audio Question Answering (s-AQA), where questions are answered based on a single audio sample, (ii) Multi-Audio Question Answering (m-AQA), which requires reasoning over multiple audio samples, and (iii) Retrieval-Augmented Audio Question Answering (r-AQA), which involves retrieving relevant audio to answer the question. We benchmark large audio language models (LALMs) on these sub-tasks and observe suboptimal performance. To address this, we propose a generic framework that can be adapted to any LALM, equipping them with knowledge reasoning capabilities. Our framework has two components: (i) Audio Entity Linking (AEL) and (ii) Knowledge-Augmented Audio Large Multimodal Model (KA2LM), which together improve performance on knowledge-intensive AQA tasks. To our knowledge, this is the first work to address advanced audio understanding via knowledge-intensive tasks like Audiopedia.
Visual Text Matters: Improving Text-KVQA with Visual Text Entity Knowledge-aware Large Multimodal Assistant
Oct 24, 2024We revisit knowledge-aware text-based visual question answering, also known as Text-KVQA, in the light of modern advancements in large multimodal models (LMMs), and make the following contributions: (i) We propose VisTEL - a principled approach to perform visual text entity linking. The proposed VisTEL module harnesses a state-of-the-art visual text recognition engine and the power of a large multimodal model to jointly reason using textual and visual context obtained using surrounding cues in the image to link the visual text entity to the correct knowledge base entity. (ii) We present KaLMA - a knowledge-aware large multimodal assistant that augments an LMM with knowledge associated with visual text entity in the image to arrive at an accurate answer. Further, we provide a comprehensive experimental analysis and comparison of our approach with traditional visual question answering, pre-large multimodal models, and large multimodal models, as well as prior top-performing approaches. Averaging over three splits of Text-KVQA, our proposed approach surpasses the previous best approach by a substantial 23.3% on an absolute scale and establishes a new state of the art. We make our implementation publicly available.
Answer Mining from a Pool of Images: Towards Retrieval-Based Visual Question Answering
Jun 29, 2023We study visual question answering in a setting where the answer has to be mined from a pool of relevant and irrelevant images given as a context. For such a setting, a model must first retrieve relevant images from the pool and answer the question from these retrieved images. We refer to this problem as retrieval-based visual question answering (or RETVQA in short). The RETVQA is distinctively different and more challenging than the traditionally-studied Visual Question Answering (VQA), where a given question has to be answered with a single relevant image in context. Towards solving the RETVQA task, we propose a unified Multi Image BART (MI-BART) that takes a question and retrieved images using our relevance encoder for free-form fluent answer generation. Further, we introduce the largest dataset in this space, namely RETVQA, which has the following salient features: multi-image and retrieval requirement for VQA, metadata-independent questions over a pool of heterogeneous images, expecting a mix of classification-oriented and open-ended generative answers. Our proposed framework achieves an accuracy of 76.5% and a fluency of 79.3% on the proposed dataset, namely RETVQA and also outperforms state-of-the-art methods by 4.9% and 11.8% on the image segment of the publicly available WebQA dataset on the accuracy and fluency metrics, respectively.
COFAR: Commonsense and Factual Reasoning in Image Search
Oct 16, 2022

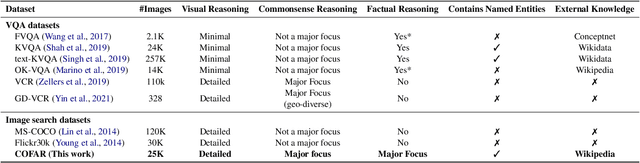
One characteristic that makes humans superior to modern artificially intelligent models is the ability to interpret images beyond what is visually apparent. Consider the following two natural language search queries - (i) "a queue of customers patiently waiting to buy ice cream" and (ii) "a queue of tourists going to see a famous Mughal architecture in India." Interpreting these queries requires one to reason with (i) Commonsense such as interpreting people as customers or tourists, actions as waiting to buy or going to see; and (ii) Fact or world knowledge associated with named visual entities, for example, whether the store in the image sells ice cream or whether the landmark in the image is a Mughal architecture located in India. Such reasoning goes beyond just visual recognition. To enable both commonsense and factual reasoning in the image search, we present a unified framework, namely Knowledge Retrieval-Augmented Multimodal Transformer (KRAMT), that treats the named visual entities in an image as a gateway to encyclopedic knowledge and leverages them along with natural language query to ground relevant knowledge. Further, KRAMT seamlessly integrates visual content and grounded knowledge to learn alignment between images and search queries. This unified framework is then used to perform image search requiring commonsense and factual reasoning. The retrieval performance of KRAMT is evaluated and compared with related approaches on a new dataset we introduce - namely COFAR. We make our code and dataset available at https://vl2g.github.io/projects/cofar