 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Object Advertisement Creative Generation
Mar 14, 2026Lifestyle images are photographs that capture environments and objects in everyday settings. In furniture product marketing, advertisers often create lifestyle images containing products to resonate with potential buyers, allowing buyers to visualize how the products fit into their daily lives. While recent advances in Generative Artificial Intelligence (GenAI) have given rise to realistic image content creation, their application in e-commerce advertising is challenging because high-quality ads must authentically representing the products in realistic scearios. Therefore, manual intervention is usually required for individual generations, making it difficult to scale to larger product catalogs. To understand the challenges faced by advertisers using GenAI to create lifestyle images at scale, we conducted evaluations on ad images generated using state-of-the-art image generation models and identified the major challenges. Based on our findings, we present CreativeAds, a multi-product ad creation system that supports scalable automated generation with customized parameter adjustment for individual generation. To ensure automated high-quality ad generation, CreativeAds innovates a pipeline that consists of three modules to address challenges in product pairing, layout generation, and background generation separately. Furthermore, CreativeAds contains an intuitive user interface to allow users to oversee generation at scale, and it also supports detailed controls on individual generation for user customized adjustments. We performed a user study on CreativeAds and extensive evaluations of the generated images, demonstrating CreativeAds's ability to create large number of high-quality images at scale for advertisers without requiring expertise in GenAI tools.
Answer Mining from a Pool of Images: Towards Retrieval-Based Visual Question Answering
Jun 29, 2023We study visual question answering in a setting where the answer has to be mined from a pool of relevant and irrelevant images given as a context. For such a setting, a model must first retrieve relevant images from the pool and answer the question from these retrieved images. We refer to this problem as retrieval-based visual question answering (or RETVQA in short). The RETVQA is distinctively different and more challenging than the traditionally-studied Visual Question Answering (VQA), where a given question has to be answered with a single relevant image in context. Towards solving the RETVQA task, we propose a unified Multi Image BART (MI-BART) that takes a question and retrieved images using our relevance encoder for free-form fluent answer generation. Further, we introduce the largest dataset in this space, namely RETVQA, which has the following salient features: multi-image and retrieval requirement for VQA, metadata-independent questions over a pool of heterogeneous images, expecting a mix of classification-oriented and open-ended generative answers. Our proposed framework achieves an accuracy of 76.5% and a fluency of 79.3% on the proposed dataset, namely RETVQA and also outperforms state-of-the-art methods by 4.9% and 11.8% on the image segment of the publicly available WebQA dataset on the accuracy and fluency metrics, respectively.
Determinantal Point Process as an alternative to NMS
Aug 26, 2020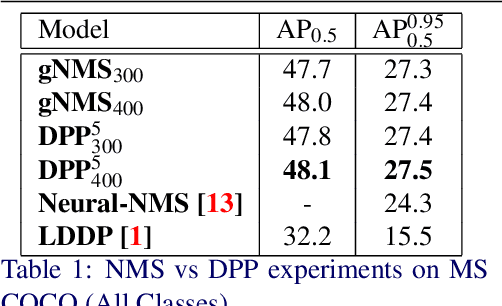
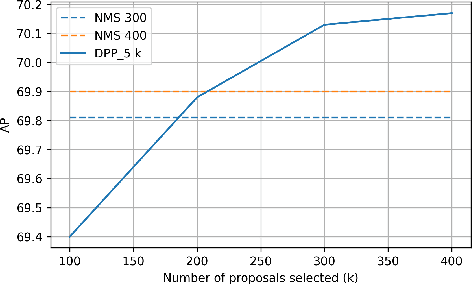
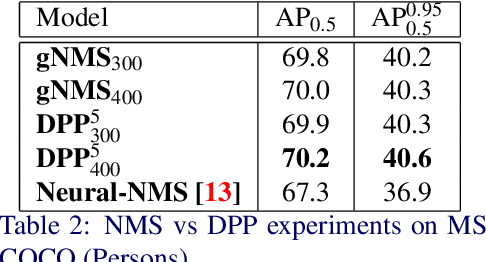
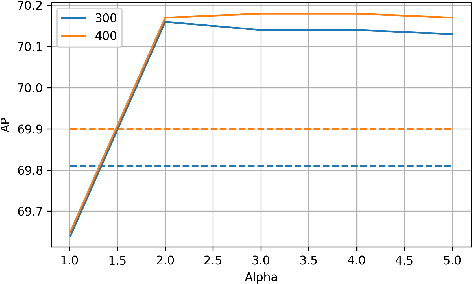
We present a determinantal point process (DPP) inspired alternative to non-maximum suppression (NMS) which has become an integral step in all state-of-the-art object detection frameworks. DPPs have been shown to encourage diversity in subset selection problems. We pose NMS as a subset selection problem and posit that directly incorporating DPP like framework can improve the overall performance of the object detection system. We propose an optimization problem which takes the same inputs as NMS, but introduces a novel sub-modularity based diverse subset selection functional. Our results strongly indicate that the modifications proposed in this paper can provide consistent improvements to state-of-the-art object detection pipelines.
Agriculture Commodity Arrival Prediction using Remote Sensing Data: Insights and Beyond
Jun 14, 2019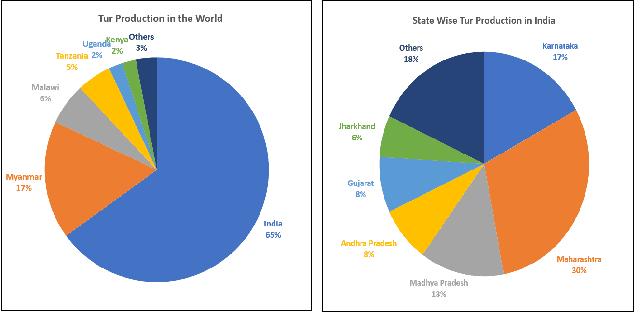
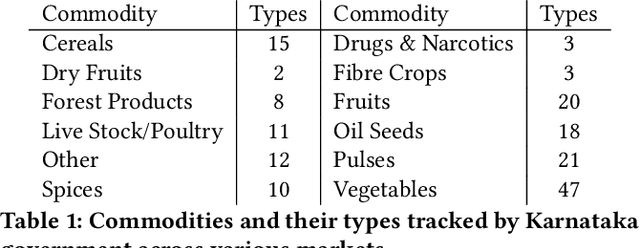
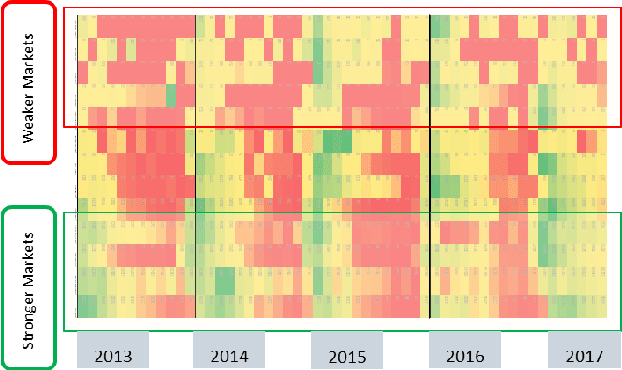
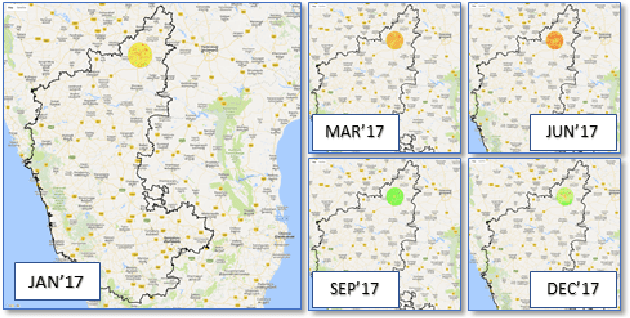
In developing countries like India agriculture plays an extremely important role in the lives of the population. In India, around 80\% of the population depend on agriculture or its by-products as the primary means for employment. Given large population dependency on agriculture, it becomes extremely important for the government to estimate market factors in advance and prepare for any deviation from those estimates. Commodity arrivals to market is an extremely important factor which is captured at district level throughout the country. Historical data and short-term prediction of important variables such as arrivals, prices, crop quality etc. for commodities are used by the government to take proactive steps and decide various policy measures. In this paper, we present a framework to work with short timeseries in conjunction with remote sensing data to predict future commodity arrivals. We deal with extremely high dimensional data which exceed the observation sizes by multiple orders of magnitude. We use cascaded layers of dimensionality reduction techniques combined with regularized regression models for prediction. We present results to predict arrivals to major markets and state wide prices for `Tur' (red gram) crop in Karnataka, India. Our model consistently beats popular ML techniques on many instances. Our model is scalable, time efficient and can be generalized to many other crops and regions. We draw multiple insights from the regression parameters, some of which are important aspects to consider when predicting more complex quantities such as prices in the future. We also combine the insights to generate important recommendations for different government organizations.
$c^+$GAN: Complementary Fashion Item Recommendation
Jun 13, 2019
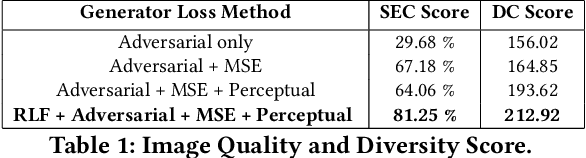

We present a conditional generative adversarial model to draw realistic samples from paired fashion clothing distribution and provide real samples to pair with arbitrary fashion units. More concretely, given an image of a shirt, obtained from a fashion magazine, a brochure or even any random click on ones phone, we draw realistic samples from a parameterized conditional distribution learned as a conditional generative adversarial network ($c^+$GAN) to generate the possible pants which can go with the shirt. We start with a classical cGAN model as proposed by Mirza and Osindero \cite{MirzaO14} and modify both the generator and discriminator to work on captured-in-the-wild data with no human alignment. We gather a dataset from web crawled data, systematically develop a method which counters the problems inherent to such data, and finally present plausible results based on our technique. We propose simple ideas to evaluate how these techniques can conquer the cognitive gap that exists when arbitrary clothing articles need to be paired with another relevant article, based on similarity of search results.
Re-evaluating ADEM: A Deeper Look at Scoring Dialogue Responses
Feb 23, 2019
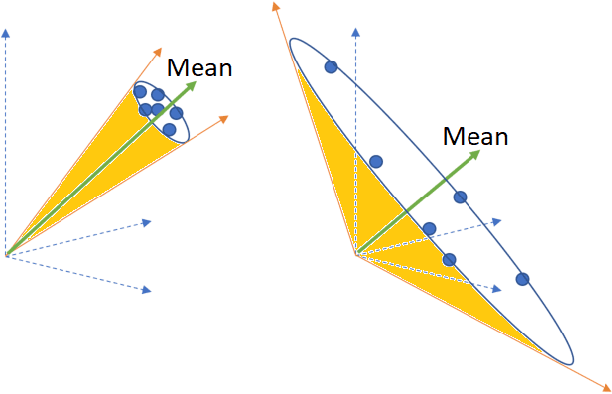

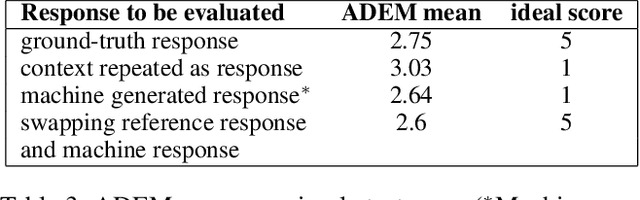
Automatically evaluating the quality of dialogue responses for unstructured domains is a challenging problem. ADEM(Lowe et al. 2017) formulated the automatic evaluation of dialogue systems as a learning problem and showed that such a model was able to predict responses which correlate significantly with human judgements, both at utterance and system level. Their system was shown to have beaten word-overlap metrics such as BLEU with large margins. We start with the question of whether an adversary can game the ADEM model. We design a battery of targeted attacks at the neural network based ADEM evaluation system and show that automatic evaluation of dialogue systems still has a long way to go. ADEM can get confused with a variation as simple as reversing the word order in the text! We report experiments on several such adversarial scenarios that draw out counterintuitive scores on the dialogue responses. We take a systematic look at the scoring function proposed by ADEM and connect it to linear system theory to predict the shortcomings evident in the system. We also devise an attack that can fool such a system to rate a response generation system as favorable. Finally, we allude to future research directions of using the adversarial attacks to design a truly automated dialogue evaluation system.
Doc2Im: document to image conversion through self-attentive embedding
Nov 08, 2018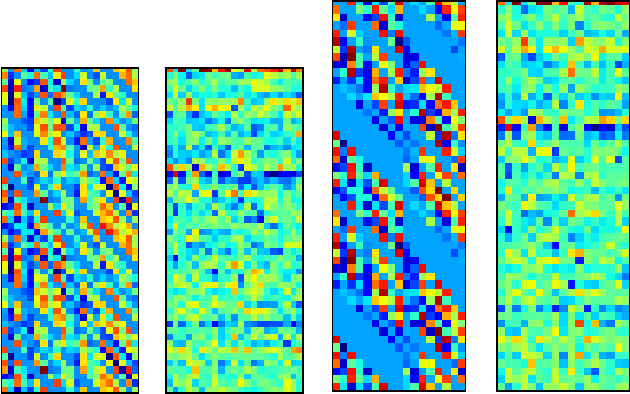
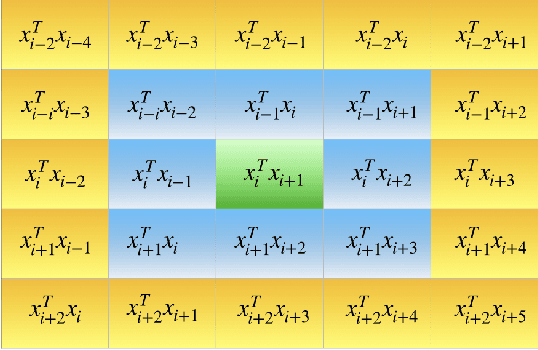
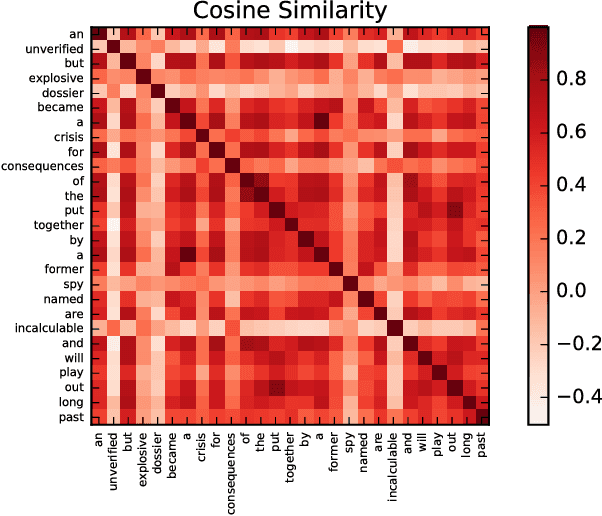
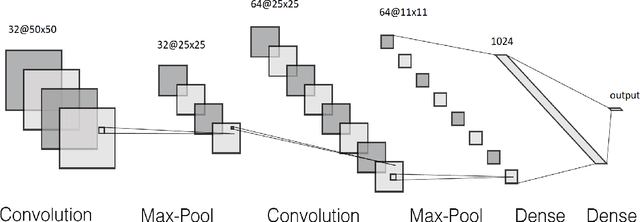
Text classification is a fundamental task in NLP applications. Latest research in this field has largely been divided into two major sub-fields. Learning representations is one sub-field and learning deeper models, both sequential and convolutional, which again connects back to the representation is the other side. We posit the idea that the stronger the representation is, the simpler classifier models are needed to achieve higher performance. In this paper we propose a completely novel direction to text classification research, wherein we convert text to a representation very similar to images, such that any deep network able to handle images is equally able to handle text. We take a deeper look at the representation of documents as an image and subsequently utilize very simple convolution based models taken as is from computer vision domain. This image can be cropped, re-scaled, re-sampled and augmented just like any other image to work with most of the state-of-the-art large convolution based models which have been designed to handle large image datasets. We show impressive results with some of the latest benchmarks in the related fields. We perform transfer learning experiments, both from text to text domain and also from image to text domain. We believe this is a paradigm shift from the way document understanding and text classification has been traditionally done, and will drive numerous novel research ideas in the community.
Solve-Select-Scale: A Three Step Process For Sparse Signal Estimation
May 16, 2016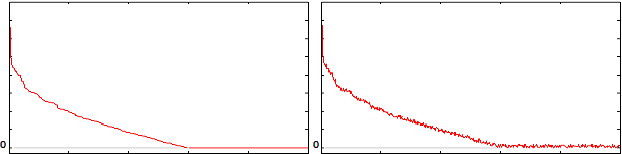
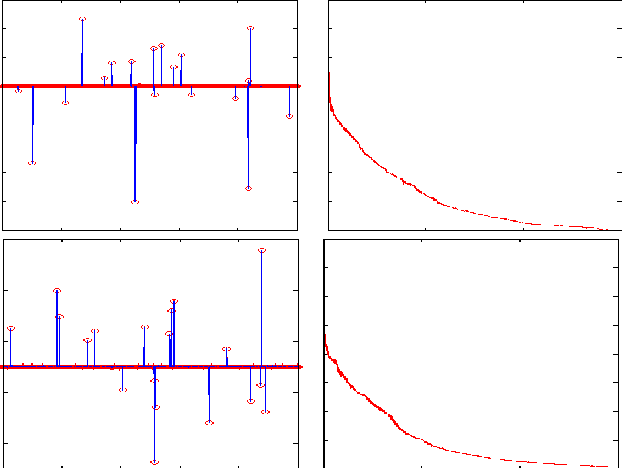
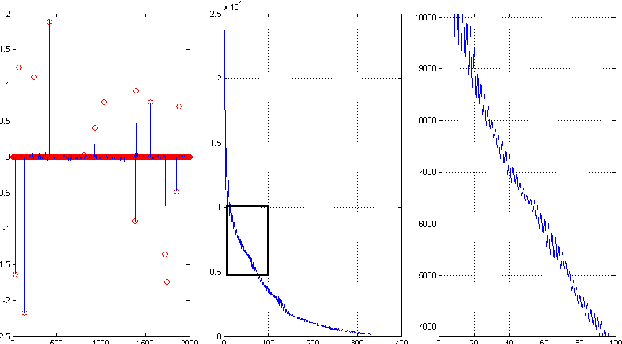
In the theory of compressed sensing (CS), the sparsity $\|x\|_0$ of the unknown signal $\mathbf{x} \in \mathcal{R}^n$ is of prime importance and the focus of reconstruction algorithms has mainly been either $\|x\|_0$ or its convex relaxation (via $\|x\|_1$). However, it is typically unknown in practice and has remained a challenge when nothing about the size of the support is known. As pointed recently, $\|x\|_0$ might not be the best metric to minimize directly, both due to its inherent complexity as well as its noise performance. Recently a novel stable measure of sparsity $s(\mathbf{x}) := \|\mathbf{x}\|_1^2/\|\mathbf{x}\|_2^2$ has been investigated by Lopes \cite{Lopes2012}, which is a sharp lower bound on $\|\mathbf{x}\|_0$. The estimation procedure for this measure uses only a small number of linear measurements, does not rely on any sparsity assumptions, and requires very little computation. The usage of the quantity $s(\mathbf{x})$ in sparse signal estimation problems has not received much importance yet. We develop the idea of incorporating $s(\mathbf{x})$ into the signal estimation framework. We also provide a three step algorithm to solve problems of the form $\mathbf{Ax=b}$ with no additional assumptions on the original signal $\mathbf{x}$.
Regularized Maximum Likelihood for Intrinsic Dimension Estimation
Mar 15, 2012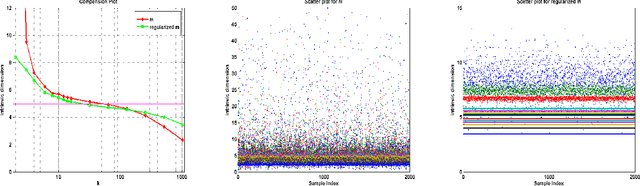
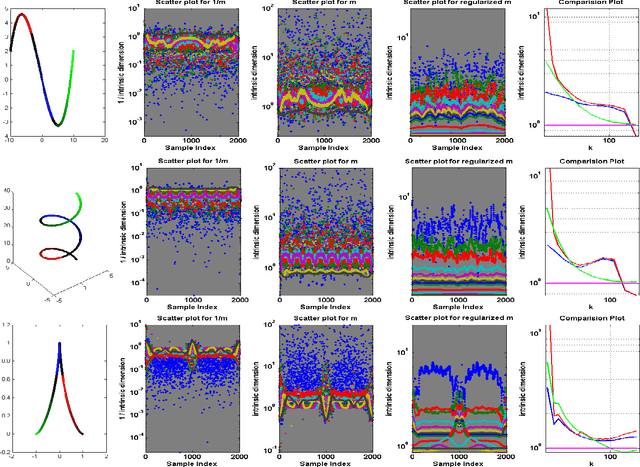
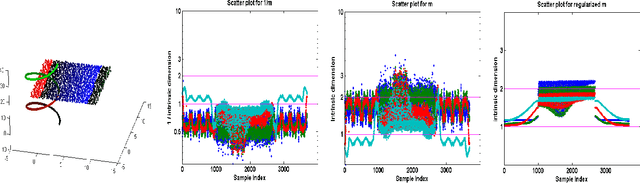
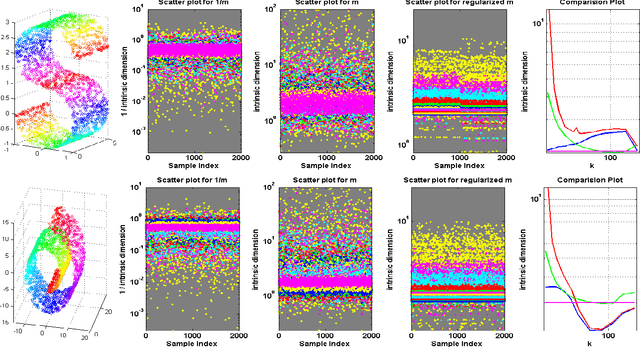
We propose a new method for estimating the intrinsic dimension of a dataset by applying the principle of regularized maximum likelihood to the distances between close neighbors. We propose a regularization scheme which is motivated by divergence minimization principles. We derive the estimator by a Poisson process approximation, argue about its convergence properties and apply it to a number of simulated and real datasets. We also show it has the best overall performance compared with two other intrinsic dimension estimators.
Additive Non-negative Matrix Factorization for Missing Data
Jul 01, 2010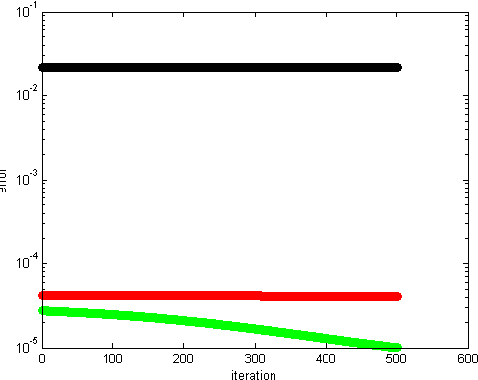
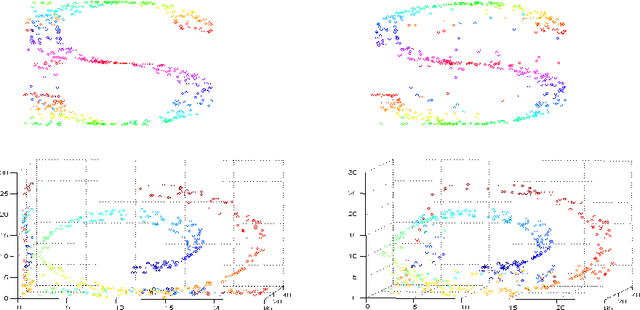
Non-negative matrix factorization (NMF) has previously been shown to be a useful decomposition for multivariate data. We interpret the factorization in a new way and use it to generate missing attributes from test data. We provide a joint optimization scheme for the missing attributes as well as the NMF factors. We prove the monotonic convergence of our algorithms. We present classification results for cases with missing attributes.