 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-evaluating ADEM: A Deeper Look at Scoring Dialogue Responses
Paper and Code
Feb 23, 2019
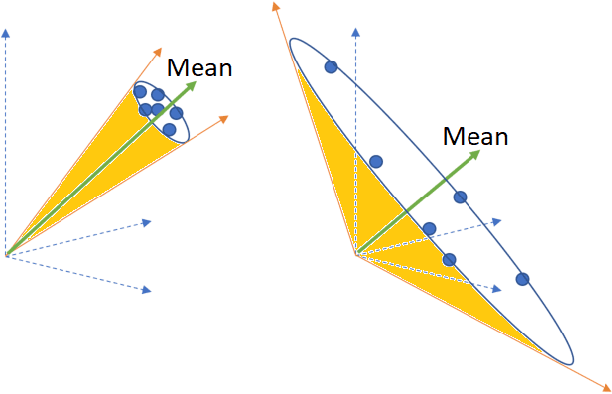

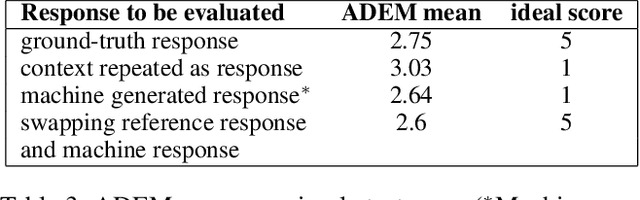
Automatically evaluating the quality of dialogue responses for unstructured domains is a challenging problem. ADEM(Lowe et al. 2017) formulated the automatic evaluation of dialogue systems as a learning problem and showed that such a model was able to predict responses which correlate significantly with human judgements, both at utterance and system level. Their system was shown to have beaten word-overlap metrics such as BLEU with large margins. We start with the question of whether an adversary can game the ADEM model. We design a battery of targeted attacks at the neural network based ADEM evaluation system and show that automatic evaluation of dialogue systems still has a long way to go. ADEM can get confused with a variation as simple as reversing the word order in the text! We report experiments on several such adversarial scenarios that draw out counterintuitive scores on the dialogue responses. We take a systematic look at the scoring function proposed by ADEM and connect it to linear system theory to predict the shortcomings evident in the system. We also devise an attack that can fool such a system to rate a response generation system as favorable. Finally, we allude to future research directions of using the adversarial attacks to design a truly automated dialogue evaluation system.