 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-IoU: Improving Label Assignment in Anchor-Free Object Detection
Apr 29, 2021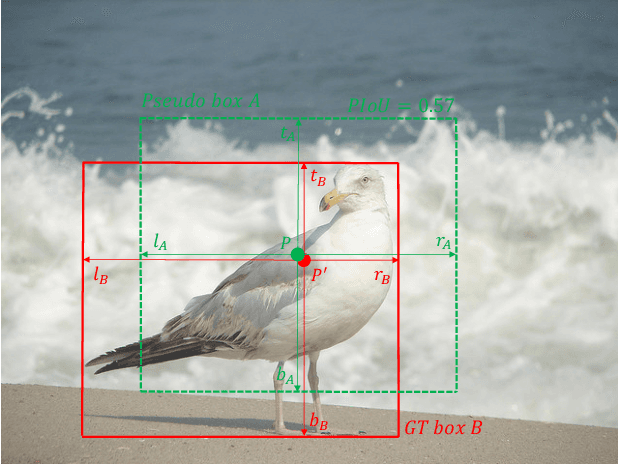
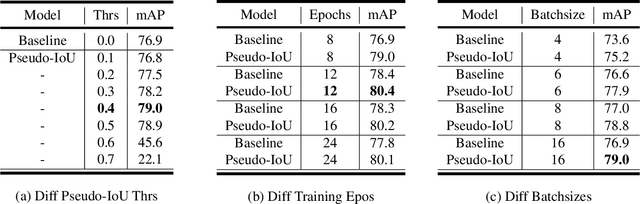
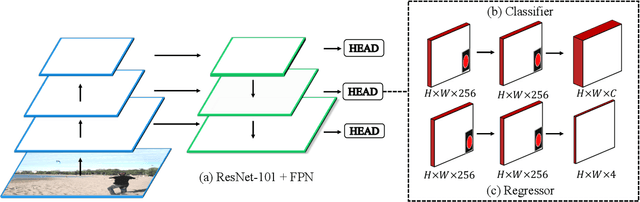
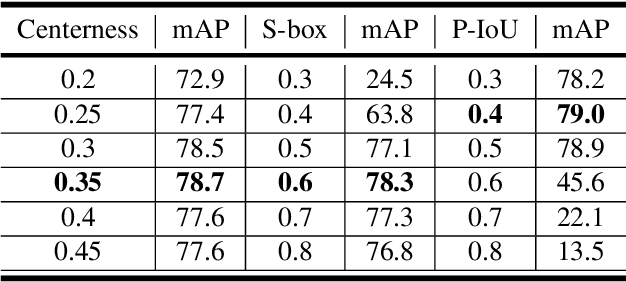
Current anchor-free object detectors are quite simple and effective yet lack accurate label assignment methods, which limits their potential in competing with classic anchor-based models that are supported by well-designed assignment methods based on the Intersection-over-Union~(IoU) metric. In this paper, we present \textbf{Pseudo-Intersection-over-Union~(Pseudo-IoU)}: a simple metric that brings more standardized and accurate assignment rule into anchor-free object detection frameworks without any additional computational cost or extra parameters for training and testing, making it possible to further improve anchor-free object detection by utilizing training samples of good quality under effective assignment rules that have been previously applied in anchor-based methods. By incorporating Pseudo-IoU metric into an end-to-end single-stage anchor-free object detection framework, we observe consistent improvements in their performance on general object detection benchmarks such as PASCAL VOC and MSCOCO. Our method (single-model and single-scale) also achieves comparable performance to other recent state-of-the-art anchor-free methods without bells and whistles. Our code is based on mmdetection toolbox and will be made publicly available at https://github.com/SHI-Labs/Pseudo-IoU-for-Anchor-Free-Object-Detection.
CompFeat: Comprehensive Feature Aggregation for Video Instance Segmentation
Dec 07, 2020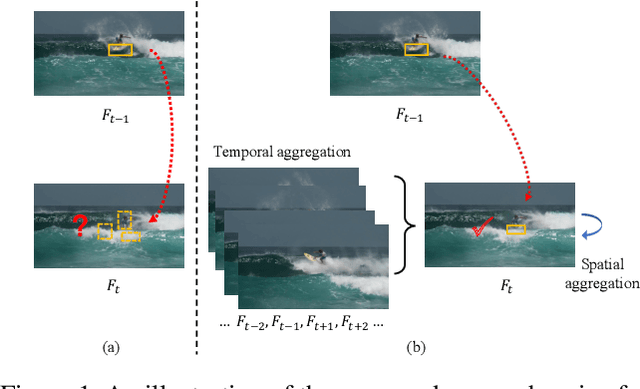

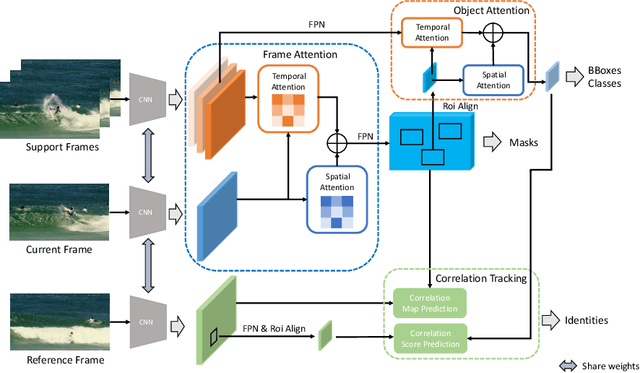
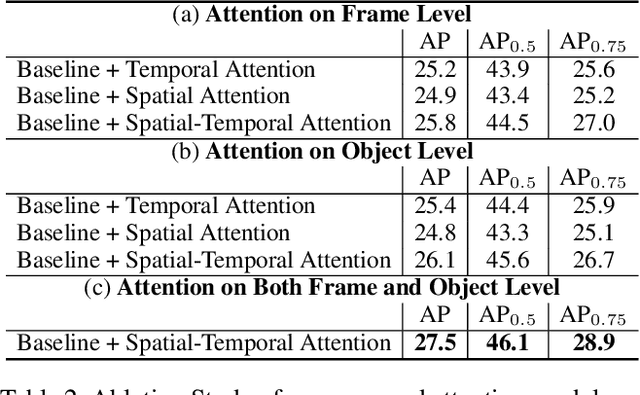
Video instance segmentation is a complex task in which we need to detect, segment, and track each object for any given video. Previous approaches only utilize single-frame features for the detection, segmentation, and tracking of objects and they suffer in the video scenario due to several distinct challenges such as motion blur and drastic appearance change. To eliminate ambiguities introduced by only using single-frame features, we propose a novel comprehensive feature aggregation approach (CompFeat) to refine features at both frame-level and object-level with temporal and spatial context information. The aggregation process is carefully designed with a new attention mechanism which significantly increases the discriminative power of the learned features. We further improve the tracking capability of our model through a siamese design by incorporating both feature similarities and spatial similarities. Experiments conducted on the YouTube-VIS dataset validate the effectiveness of proposed CompFeat. Our code will be available at https://github.com/SHI-Labs/CompFeat-for-Video-Instance-Segmentation.
Motion Pyramid Networks for Accurate and Efficient Cardiac Motion Estimation
Jun 28, 2020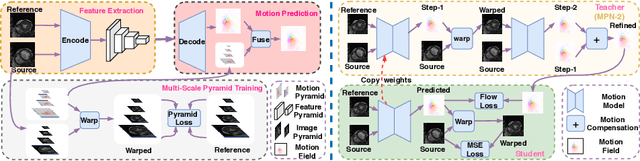

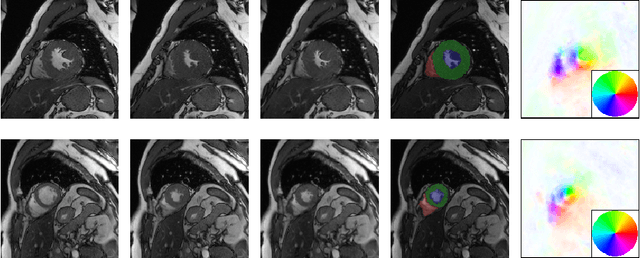
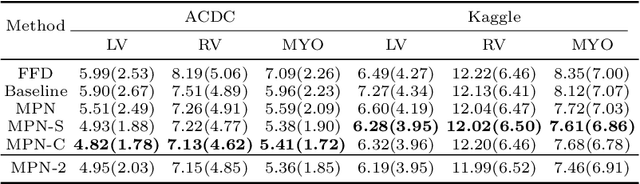
Cardiac motion estimation plays a key role in MRI cardiac feature tracking and function assessment such as myocardium strain. In this paper, we propose Motion Pyramid Networks, a novel deep learning-based approach for accurate and efficient cardiac motion estimation. We predict and fuse a pyramid of motion fields from multiple scales of feature representations to generate a more refined motion field. We then use a novel cyclic teacher-student training strategy to make the inference end-to-end and further improve the tracking performance. Our teacher model provides more accurate motion estimation as supervision through progressive motion compensations. Our student model learns from the teacher model to estimate motion in a single step while maintaining accuracy. The teacher-student knowledge distillation is performed in a cyclic way for a further performance boost. Our proposed method outperforms a strong baseline model on two public available clinical datasets significantly, evaluated by a variety of metrics and the inference time. New evaluation metrics are also proposed to represent errors in a clinically meaningful manner.
Neural Sparse Representation for Image Restoration
Jun 08, 2020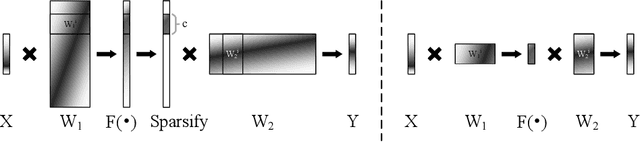
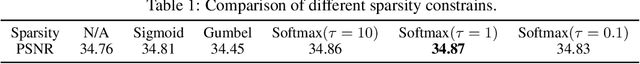

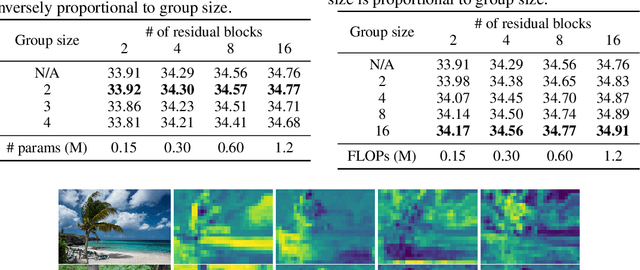
Inspired by the robustness and efficiency of sparse representation in sparse coding based image restoration models, we investigate the sparsity of neurons in deep networks. Our method structurally enforces sparsity constraints upon hidden neurons. The sparsity constraints are favorable for gradient-based learning algorithms and attachable to convolution layers in various networks. Sparsity in neurons enables computation saving by only operating on non-zero components without hurting accuracy. Meanwhile, our method can magnify representation dimensionality and model capacity with negligible additional computation cost. Experiments show that sparse representation is crucial in deep neural networks for multiple image restoration tasks, including image super-resolution, image denoising, and image compression artifacts removal. Code is available at https://github.com/ychfan/nsr
Pyramid Attention Networks for Image Restoration
Jun 03, 2020
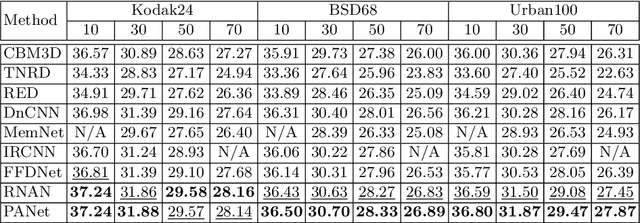


Self-similarity refers to the image prior widely used in image restoration algorithms that small but similar patterns tend to occur at different locations and scales. However, recent advanced deep convolutional neural network based methods for image restoration do not take full advantage of self-similarities by relying on self-attention neural modules that only process information at the same scale. To solve this problem, we present a novel Pyramid Attention module for image restoration, which captures long-range feature correspondences from a multi-scale feature pyramid. Inspired by the fact that corruptions, such as noise or compression artifacts, drop drastically at coarser image scales, our attention module is designed to be able to borrow clean signals from their "clean" correspondences at the coarser levels. The proposed pyramid attention module is a generic building block that can be flexibly integrated into various neural architectures. Its effectiveness is validated through extensive experiments on multiple image restoration tasks: image denoising, demosaicing, compression artifact reduction, and super resolution. Without any bells and whistles, our PANet (pyramid attention module with simple network backbones) can produce state-of-the-art results with superior accuracy and visual quality. Our code will be available at https://github.com/SHI-Labs/Pyramid-Attention-Networks
Image Super-Resolution with Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining
Jun 02, 2020
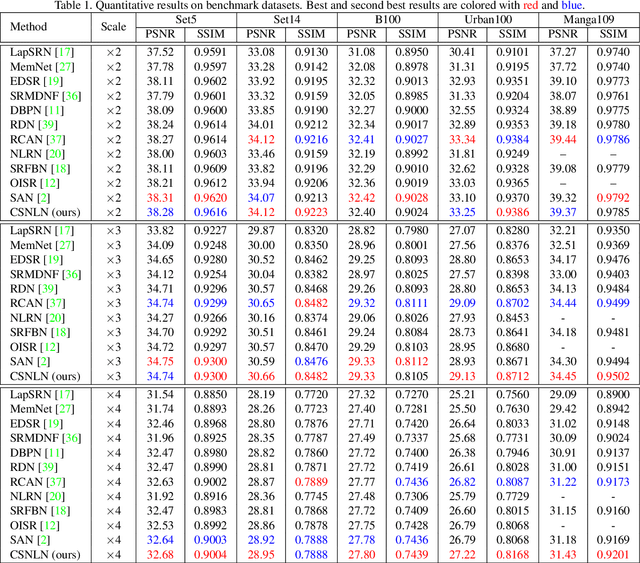

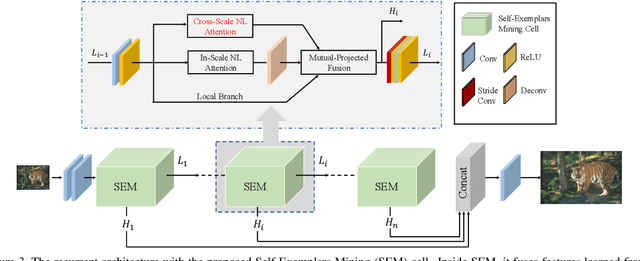
Deep convolution-based single image super-resolution (SISR) networks embrace the benefits of learning from large-scale external image resources for local recovery, yet most existing works have ignored the long-range feature-wise similarities in natural images. Some recent works have successfully leveraged this intrinsic feature correlation by exploring non-local attention modules. However, none of the current deep models have studied another inherent property of images: cross-scale feature correlation. In this paper, we propose the first Cross-Scale Non-Local (CS-NL) attention module with integration into a recurrent neural network. By combining the new CS-NL prior with local and in-scale non-local priors in a powerful recurrent fusion cell, we can find more cross-scale feature correlations within a single low-resolution (LR) image. The performance of SISR is significantly improved by exhaustively integrating all possible priors. Extensive experiments demonstrate the effectiveness of the proposed CS-NL module by setting new state-of-the-arts on multiple SISR benchmarks.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
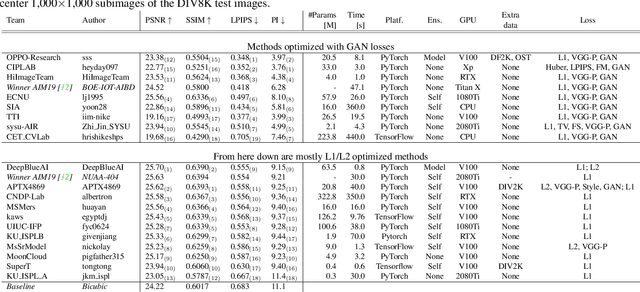

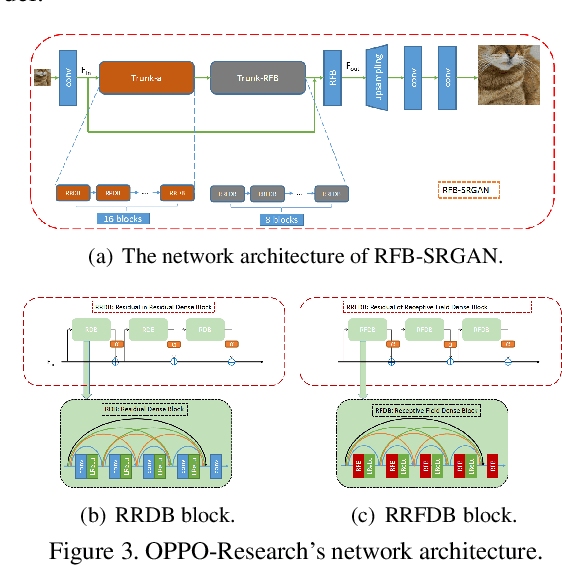
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
The 1st Agriculture-Vision Challenge: Methods and Results
Apr 23, 2020
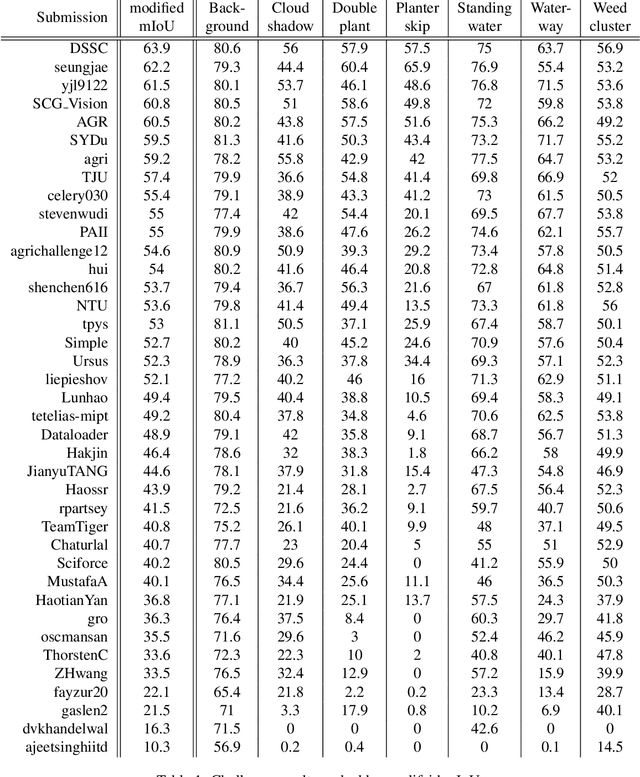
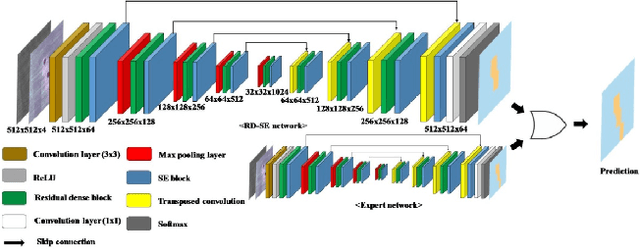
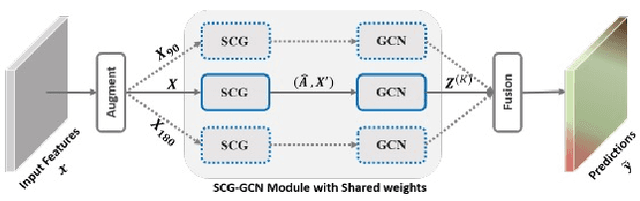
The first Agriculture-Vision Challenge aims to encourage research in developing novel and effective algorithms for agricultural pattern recognition from aerial images, especially for the semantic segmentation task associated with our challenge dataset. Around 57 participating teams from various countries compete to achieve state-of-the-art in aerial agriculture semantic segmentation. The Agriculture-Vision Challenge Dataset was employed, which comprises of 21,061 aerial and multi-spectral farmland images. This paper provides a summary of notable methods and results in the challenge. Our submission server and leaderboard will continue to open for researchers that are interested in this challenge dataset and task; the link can be found here.
Differential Treatment for Stuff and Things: A Simple Unsupervised Domain Adaptation Method for Semantic Segmentation
Apr 22, 2020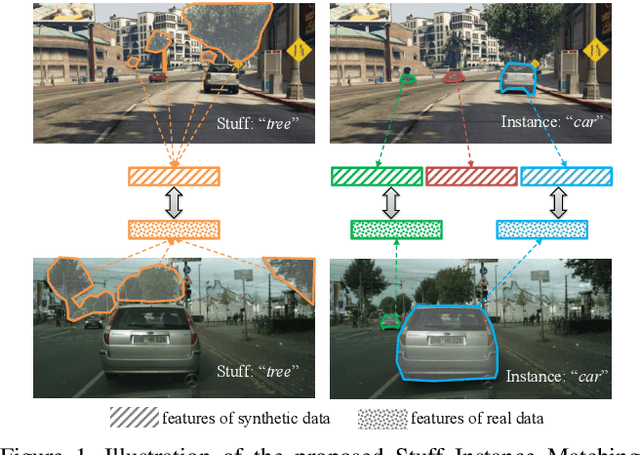

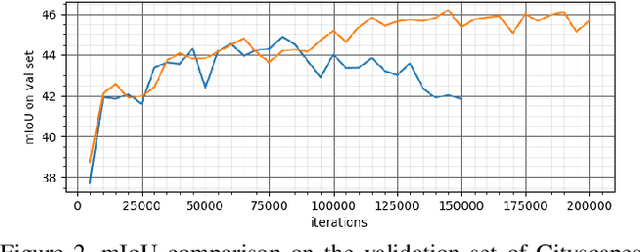
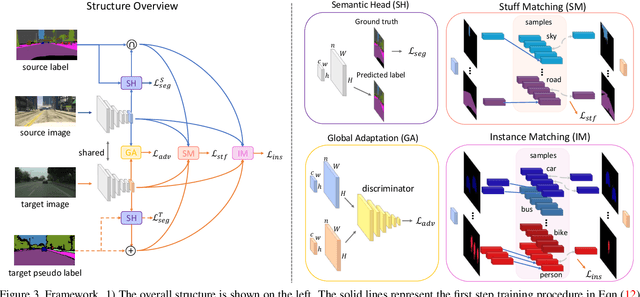
We consider the problem of unsupervised domain adaptation for semantic segmentation by easing the domain shift between the source domain (synthetic data) and the target domain (real data) in this work. State-of-the-art approaches prove that performing semantic-level alignment is helpful in tackling the domain shift issue. Based on the observation that stuff categories usually share similar appearances across images of different domains while things (i.e. object instances) have much larger differences, we propose to improve the semantic-level alignment with different strategies for stuff regions and for things: 1) for the stuff categories, we generate feature representation for each class and conduct the alignment operation from the target domain to the source domain; 2) for the thing categories, we generate feature representation for each individual instance and encourage the instance in the target domain to align with the most similar one in the source domain. In this way, the individual differences within thing categories will also be considered to alleviate over-alignment. In addition to our proposed method, we further reveal the reason why the current adversarial loss is often unstable in minimizing the distribution discrepancy and show that our method can help ease this issue by minimizing the most similar stuff and instance features between the source and the target domains. We conduct extensive experiments in two unsupervised domain adaptation tasks, i.e. GTA5 to Cityscapes and SYNTHIA to Cityscapes, and achieve the new state-of-the-art segmentation accuracy.
Alleviating Semantic-level Shift: A Semi-supervised Domain Adaptation Method for Semantic Segmentation
Apr 02, 2020
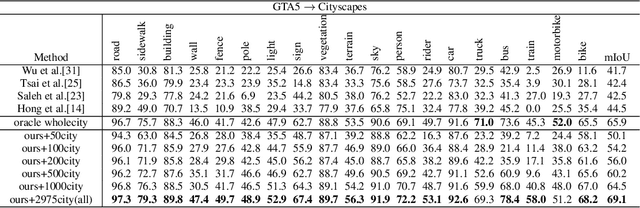
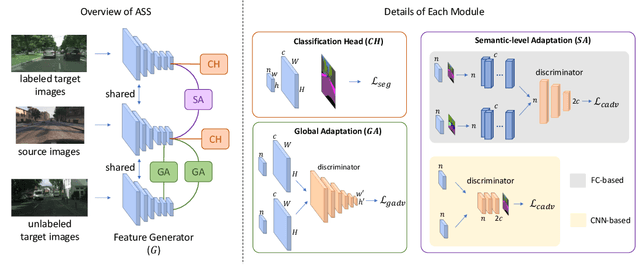
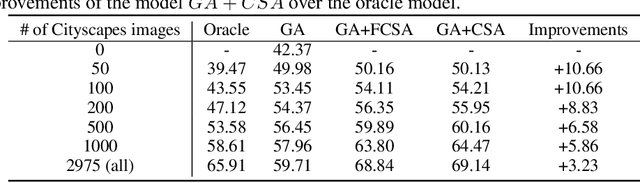
Learning segmentation from synthetic data and adapting to real data can significantly relieve human efforts in labelling pixel-level masks. A key challenge of this task is how to alleviate the data distribution discrepancy between the source and target domains, i.e. reducing domain shift. The common approach to this problem is to minimize the discrepancy between feature distributions from different domains through adversarial training. However, directly aligning the feature distribution globally cannot guarantee consistency from a local view (i.e. semantic-level), which prevents certain semantic knowledge learned on the source domain from being applied to the target domain. To tackle this issue, we propose a semi-supervised approach named Alleviating Semantic-level Shift (ASS), which can successfully promote the distribution consistency from both global and local views. Specifically, leveraging a small number of labeled data from the target domain, we directly extract semantic-level feature representations from both the source and the target domains by averaging the features corresponding to same categories advised by pixel-level masks. We then feed the produced features to the discriminator to conduct semantic-level adversarial learning, which collaborates with the adversarial learning from the global view to better alleviate the domain shift. We apply our ASS to two domain adaptation tasks, from GTA5 to Cityscapes and from Synthia to Cityscapes. Extensive experiments demonstrate that: (1) ASS can significantly outperform the current unsupervised state-of-the-arts by employing a small number of annotated samples from the target domain; (2) ASS can beat the oracle model trained on the whole target dataset by over 3 points by augmenting the synthetic source data with annotated samples from the target domain without suffering from the prevalent problem of overfitting to the source domain.