 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenCo: An Auxiliary Generator from Contrastive Learning for Enhanced Few-Shot Learning in Remote Sensing
Jul 27, 2023Classifying and segmenting patterns from a limited number of examples is a significant challenge in remote sensing and earth observation due to the difficulty in acquiring accurately labeled data in large quantities. Previous studies have shown that meta-learning, which involves episodic training on query and support sets, is a promising approach. However, there has been little attention paid to direct fine-tuning techniques. This paper repurposes contrastive learning as a pre-training method for few-shot learning for classification and semantic segmentation tasks. Specifically, we introduce a generator-based contrastive learning framework (GenCo) that pre-trains backbones and simultaneously explores variants of feature samples. In fine-tuning, the auxiliary generator can be used to enrich limited labeled data samples in feature space. We demonstrate the effectiveness of our method in improving few-shot learning performance on two key remote sensing datasets: Agriculture-Vision and EuroSAT. Empirically, our approach outperforms purely supervised training on the nearly 95,000 images in Agriculture-Vision for both classification and semantic segmentation tasks. Similarly, the proposed few-shot method achieves better results on the land-cover classification task on EuroSAT compared to the results obtained from fully supervised model training on the dataset.
Hallucination Improves the Performance of Unsupervised Visual Representation Learning
Jul 22, 2023


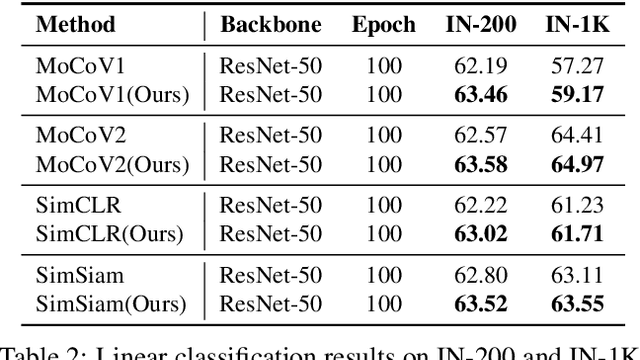
Contrastive learning models based on Siamese structure have demonstrated remarkable performance in self-supervised learning. Such a success of contrastive learning relies on two conditions, a sufficient number of positive pairs and adequate variations between them. If the conditions are not met, these frameworks will lack semantic contrast and be fragile on overfitting. To address these two issues, we propose Hallucinator that could efficiently generate additional positive samples for further contrast. The Hallucinator is differentiable and creates new data in the feature space. Thus, it is optimized directly with the pre-training task and introduces nearly negligible computation. Moreover, we reduce the mutual information of hallucinated pairs and smooth them through non-linear operations. This process helps avoid over-confident contrastive learning models during the training and achieves more transformation-invariant feature embeddings. Remarkably, we empirically prove that the proposed Hallucinator generalizes well to various contrastive learning models, including MoCoV1&V2, SimCLR and SimSiam. Under the linear classification protocol, a stable accuracy gain is achieved, ranging from 0.3% to 3.0% on CIFAR10&100, Tiny ImageNet, STL-10 and ImageNet. The improvement is also observed in transferring pre-train encoders to the downstream tasks, including object detection and segmentation.
Extended Agriculture-Vision: An Extension of a Large Aerial Image Dataset for Agricultural Pattern Analysis
Mar 04, 2023

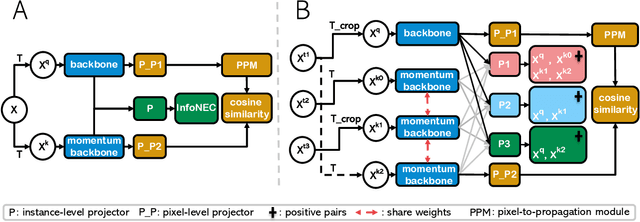
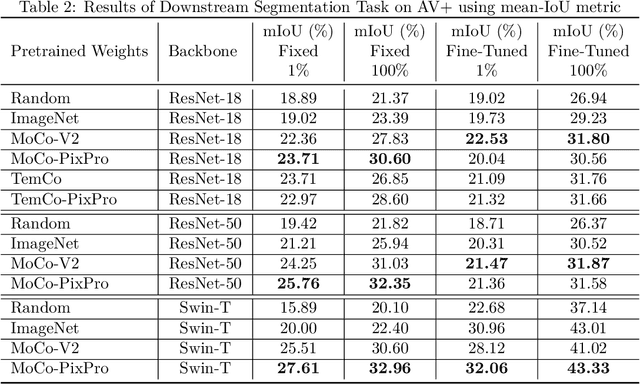
A key challenge for much of the machine learning work on remote sensing and earth observation data is the difficulty in acquiring large amounts of accurately labeled data. This is particularly true for semantic segmentation tasks, which are much less common in the remote sensing domain because of the incredible difficulty in collecting precise, accurate, pixel-level annotations at scale. Recent efforts have addressed these challenges both through the creation of supervised datasets as well as the application of self-supervised methods. We continue these efforts on both fronts. First, we generate and release an improved version of the Agriculture-Vision dataset (Chiu et al., 2020b) to include raw, full-field imagery for greater experimental flexibility. Second, we extend this dataset with the release of 3600 large, high-resolution (10cm/pixel), full-field, red-green-blue and near-infrared images for pre-training. Third, we incorporate the Pixel-to-Propagation Module Xie et al. (2021b) originally built on the SimCLR framework into the framework of MoCo-V2 Chen et al.(2020b). Finally, we demonstrate the usefulness of this data by benchmarking different contrastive learning approaches on both downstream classification and semantic segmentation tasks. We explore both CNN and Swin Transformer Liu et al. (2021a) architectures within different frameworks based on MoCo-V2. Together, these approaches enable us to better detect key agricultural patterns of interest across a field from aerial imagery so that farmers may be alerted to problematic areas in a timely fashion to inform their management decisions. Furthermore, the release of these datasets will support numerous avenues of research for computer vision in remote sensing for agriculture.
* Dataset: https://github.com/jingwu6/Extended-Agriculture-Vision-Dataset Video: https://youtu.be/2xaKxUpY4iQ
Superpixels and Graph Convolutional Neural Networks for Efficient Detection of Nutrient Deficiency Stress from Aerial Imagery
Apr 22, 2021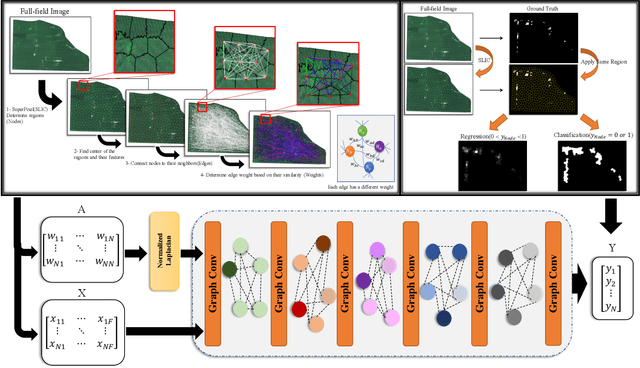



Advances in remote sensing technology have led to the capture of massive amounts of data. Increased image resolution, more frequent revisit times, and additional spectral channels have created an explosion in the amount of data that is available to provide analyses and intelligence across domains, including agriculture. However, the processing of this data comes with a cost in terms of computation time and money, both of which must be considered when the goal of an algorithm is to provide real-time intelligence to improve efficiencies. Specifically, we seek to identify nutrient deficient areas from remotely sensed data to alert farmers to regions that require attention; detection of nutrient deficient areas is a key task in precision agriculture as farmers must quickly respond to struggling areas to protect their harvests. Past methods have focused on pixel-level classification (i.e. semantic segmentation) of the field to achieve these tasks, often using deep learning models with tens-of-millions of parameters. In contrast, we propose a much lighter graph-based method to perform node-based classification. We first use Simple Linear Iterative Cluster (SLIC) to produce superpixels across the field. Then, to perform segmentation across the non-Euclidean domain of superpixels, we leverage a Graph Convolutional Neural Network (GCN). This model has 4-orders-of-magnitude fewer parameters than a CNN model and trains in a matter of minutes.
Residue Density Segmentation for Monitoring and Optimizing Tillage Practices
Feb 09, 2021

"No-till" and cover cropping are often identified as the leading simple, best management practices for carbon sequestration in agriculture. However, the root of the problem is more complex, with the potential benefits of these approaches depending on numerous factors including a field's soil type(s), topography, and management history. Instead of using computer vision approaches to simply classify a field a still vs. no-till, we instead seek to identify the degree of residue coverage across afield through a probabilistic deep learning segmentation approach to enable more accurate analysis of carbon holding potential and realization. This approach will not only provide more precise insights into currently implemented practices, but also enable a more accurate identification process of fields with the greatest potential for adopting new practices to significantly impact carbon sequestration in agriculture.
Detection and Prediction of Nutrient Deficiency Stress using Longitudinal Aerial Imagery
Dec 17, 2020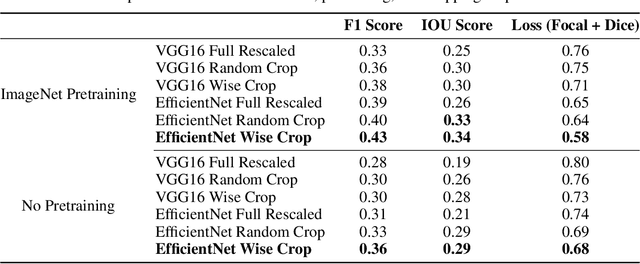
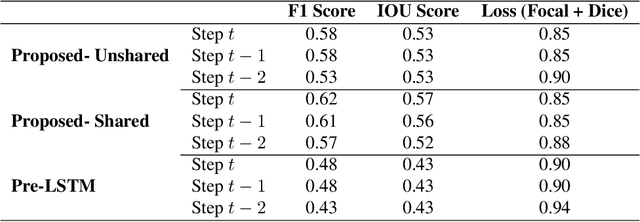
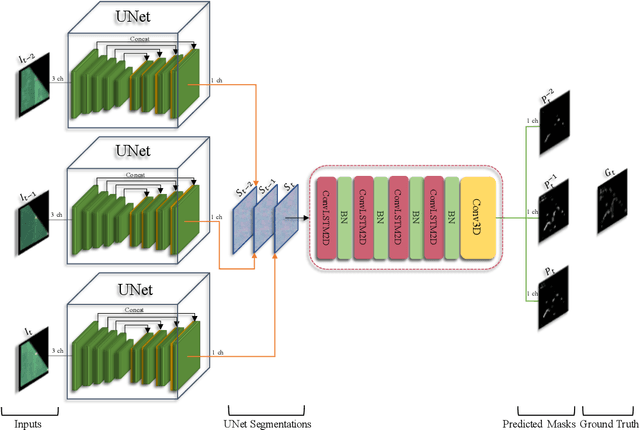
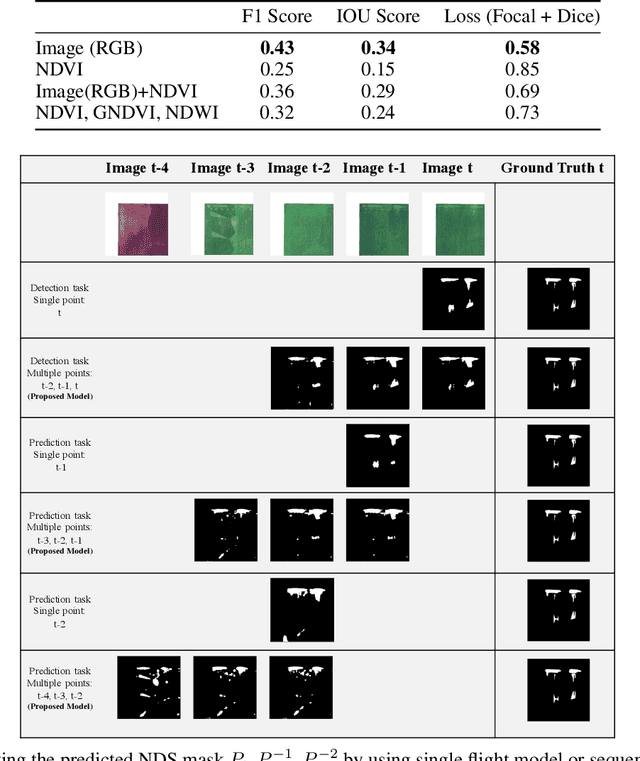
Early, precise detection of nutrient deficiency stress (NDS) has key economic as well as environmental impact; precision application of chemicals in place of blanket application reduces operational costs for the growers while reducing the amount of chemicals which may enter the environment unnecessarily. Furthermore, earlier treatment reduces the amount of loss and therefore boosts crop production during a given season. With this in mind, we collect sequences of high-resolution aerial imagery and construct semantic segmentation models to detect and predict NDS across the field. Our work sits at the intersection of agriculture, remote sensing, and modern computer vision and deep learning. First, we establish a baseline for full-field detection of NDS and quantify the impact of pretraining, backbone architecture, input representation, and sampling strategy. We then quantify the amount of information available at different points in the season by building a single-timestamp model based on a UNet. Next, we construct our proposed spatiotemporal architecture, which combines a UNet with a convolutional LSTM layer, to accurately detect regions of the field showing NDS; this approach has an impressive IOU score of 0.53. Finally, we show that this architecture can be trained to predict regions of the field which are expected to show NDS in a later flight -- potentially more than three weeks in the future -- maintaining an IOU score of 0.47-0.51 depending on how far in advance the prediction is made. We will also release a dataset which we believe will benefit the computer vision, remote sensing, as well as agriculture fields. This work contributes to the recent developments in deep learning for remote sensing and agriculture, while addressing a key social challenge with implications for economics and sustainability.
The 1st Agriculture-Vision Challenge: Methods and Results
Apr 23, 2020
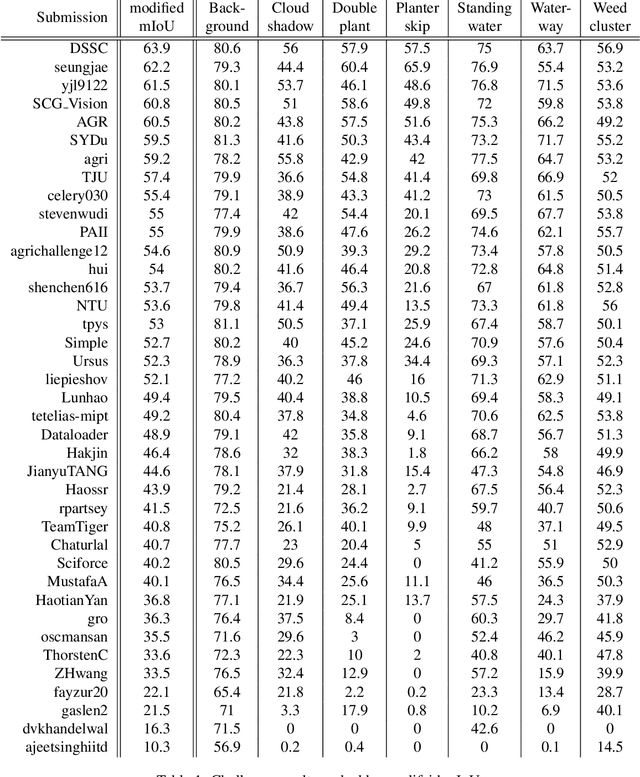
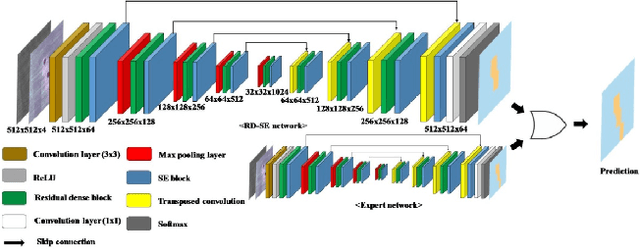
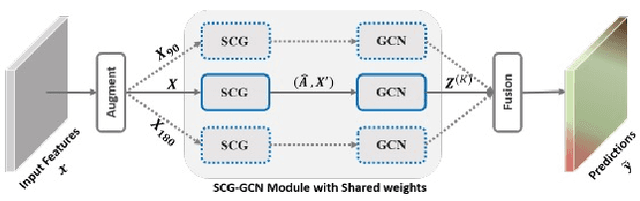
The first Agriculture-Vision Challenge aims to encourage research in developing novel and effective algorithms for agricultural pattern recognition from aerial images, especially for the semantic segmentation task associated with our challenge dataset. Around 57 participating teams from various countries compete to achieve state-of-the-art in aerial agriculture semantic segmentation. The Agriculture-Vision Challenge Dataset was employed, which comprises of 21,061 aerial and multi-spectral farmland images. This paper provides a summary of notable methods and results in the challenge. Our submission server and leaderboard will continue to open for researchers that are interested in this challenge dataset and task; the link can be found here.
Improved Structural Discovery and Representation Learning of Multi-Agent Data
Dec 30, 2019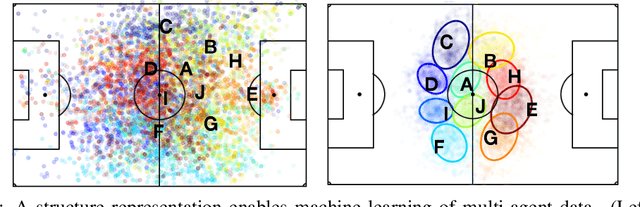
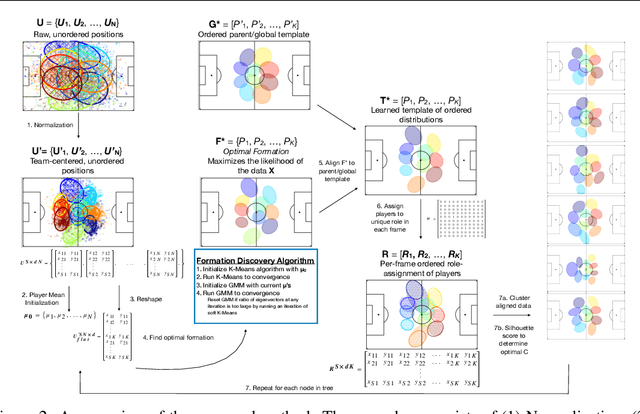
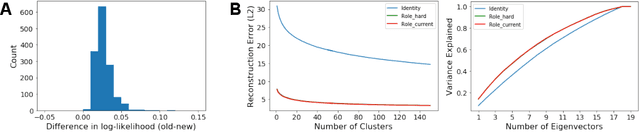
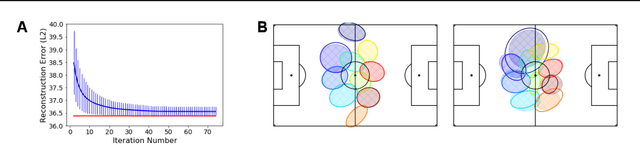
Central to all machine learning algorithms is data representation. For multi-agent systems, selecting a representation which adequately captures the interactions among agents is challenging due to the latent group structure which tends to vary depending on context. However, in multi-agent systems with strong group structure, we can simultaneously learn this structure and map a set of agents to a consistently ordered representation for further learning. In this paper, we present a dynamic alignment method which provides a robust ordering of structured multi-agent data enabling representation learning to occur in a fraction of the time of previous methods. We demonstrate the value of this approach using a large amount of soccer tracking data from a professional league.
Rugby-Bot: Utilizing Multi-Task Learning & Fine-Grained Features for Rugby League Analysis
Oct 16, 2019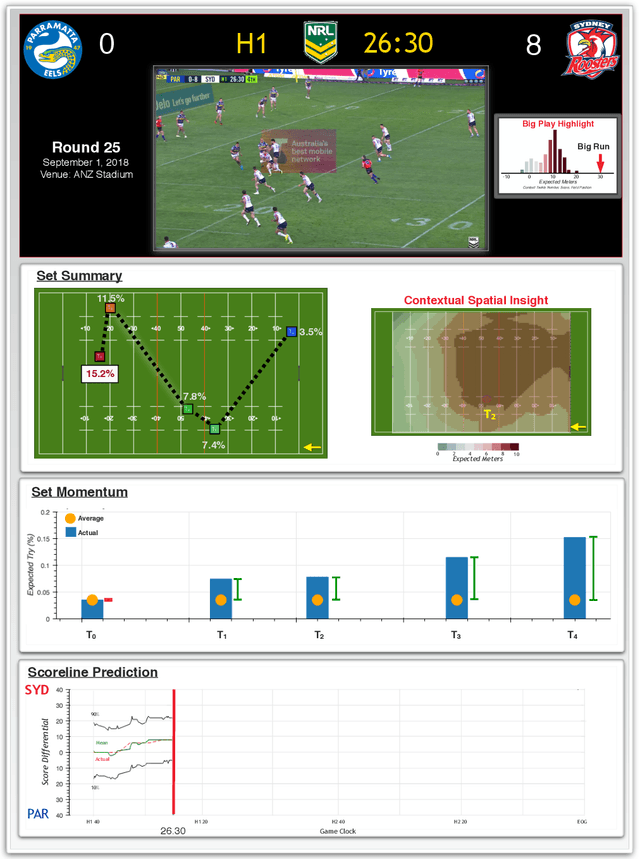
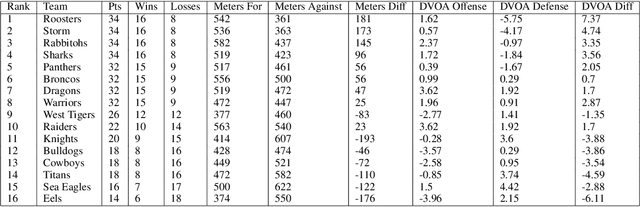
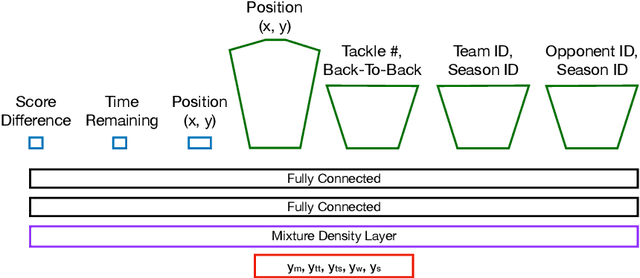

Sporting events are extremely complex and require a multitude of metrics to accurate describe the event. When making multiple predictions, one should make them from a single source to keep consistency across the predictions. We present a multi-task learning method of generating multiple predictions for analysis via a single prediction source. To enable this approach, we utilize a fine-grain representation using fine-grain spatial data using a wide-and-deep learning approach. Additionally, our approach can predict distributions rather than single point values. We highlighted the utility of our approach on the sport of Rugby League and call our prediction engine "Rugby-Bot".