 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledgebra: An Algebraic Learning Framework for Knowledge Graph
Apr 15, 2022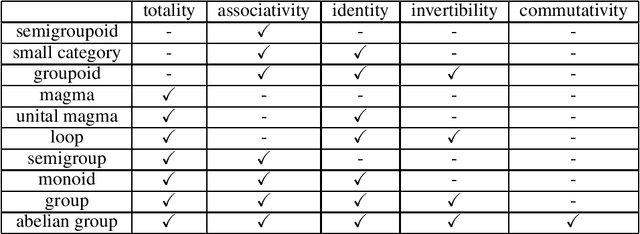


Knowledge graph (KG) representation learning aims to encode entities and relations into dense continuous vector spaces such that knowledge contained in a dataset could be consistently represented. Dense embeddings trained from KG datasets benefit a variety of downstream tasks such as KG completion and link prediction. However, existing KG embedding methods fell short to provide a systematic solution for the global consistency of knowledge representation. We developed a mathematical language for KG based on an observation of their inherent algebraic structure, which we termed as Knowledgebra. By analyzing five distinct algebraic properties, we proved that the semigroup is the most reasonable algebraic structure for the relation embedding of a general knowledge graph. We implemented an instantiation model, SemE, using simple matrix semigroups, which exhibits state-of-the-art performance on standard datasets. Moreover, we proposed a regularization-based method to integrate chain-like logic rules derived from human knowledge into embedding training, which further demonstrates the power of the developed language. As far as we know, by applying abstract algebra in statistical learning, this work develops the first formal language for general knowledge graphs, and also sheds light on the problem of neural-symbolic integration from an algebraic perspective.
Semi-supervised Dense Keypointsusing Unlabeled Multiview Images
Sep 20, 2021
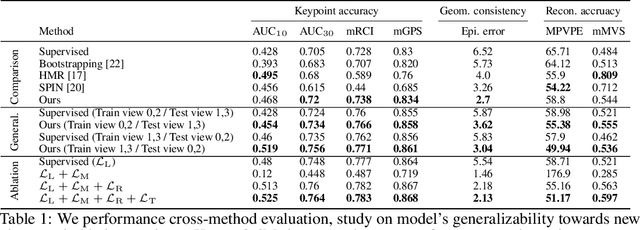


This paper presents a new end-to-end semi-supervised framework to learn a dense keypoint detector using unlabeled multiview images. A key challenge lies in finding the exact correspondences between the dense keypoints in multiple views since the inverse of keypoint mapping can be neither analytically derived nor differentiated. This limits applying existing multiview supervision approaches on sparse keypoint detection that rely on the exact correspondences. To address this challenge, we derive a new probabilistic epipolar constraint that encodes the two desired properties. (1) Soft correspondence: we define a matchability, which measures a likelihood of a point matching to the other image's corresponding point, thus relaxing the exact correspondences' requirement. (2) Geometric consistency: every point in the continuous correspondence fields must satisfy the multiview consistency collectively. We formulate a probabilistic epipolar constraint using a weighted average of epipolar errors through the matchability thereby generalizing the point-to-point geometric error to the field-to-field geometric error. This generalization facilitates learning a geometrically coherent dense keypoint detection model by utilizing a large number of unlabeled multiview images. Additionally, to prevent degenerative cases, we employ a distillation-based regularization by using a pretrained model. Finally, we design a new neural network architecture, made of twin networks, that effectively minimizes the probabilistic epipolar errors of all possible correspondences between two view images by building affinity matrices. Our method shows superior performance compared to existing methods, including non-differentiable bootstrapping in terms of keypoint accuracy, multiview consistency, and 3D reconstruction accuracy.
Variance Regularization for Accelerating Stochastic Optimization
Aug 13, 2020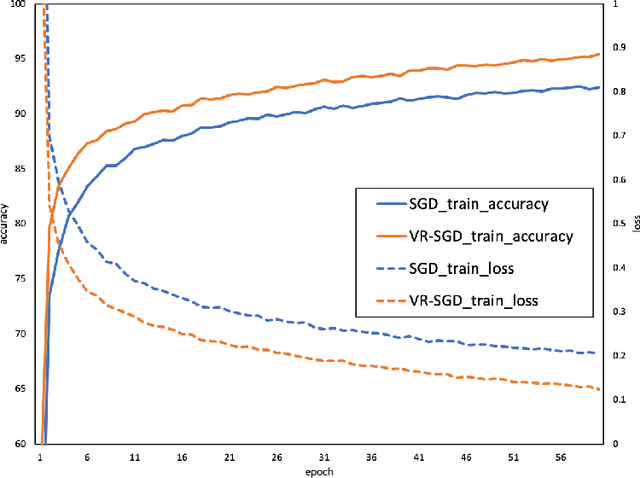

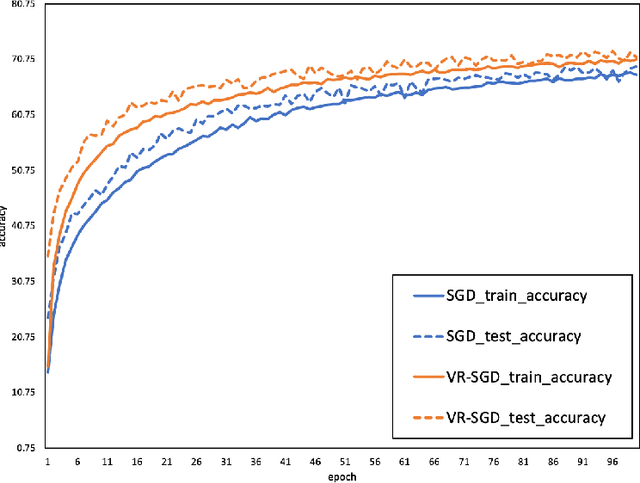
While nowadays most gradient-based optimization methods focus on exploring the high-dimensional geometric features, the random error accumulated in a stochastic version of any algorithm implementation has not been stressed yet. In this work, we propose a universal principle which reduces the random error accumulation by exploiting statistic information hidden in mini-batch gradients. This is achieved by regularizing the learning-rate according to mini-batch variances. Due to the complementarity of our perspective, this regularization could provide a further improvement for stochastic implementation of generic 1st order approaches. With empirical results, we demonstrated the variance regularization could speed up the convergence as well as stabilize the stochastic optimization.
A Deep Learning Approach for COVID-19 Trend Prediction
Aug 09, 2020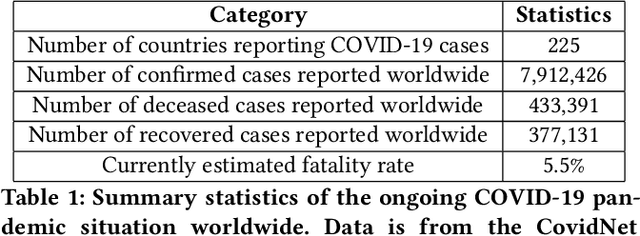
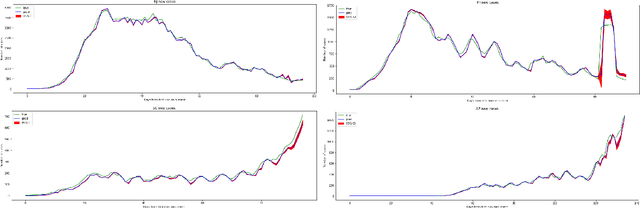
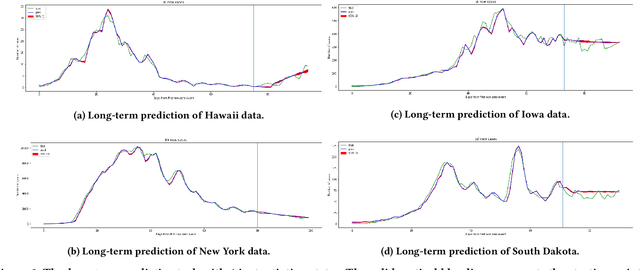
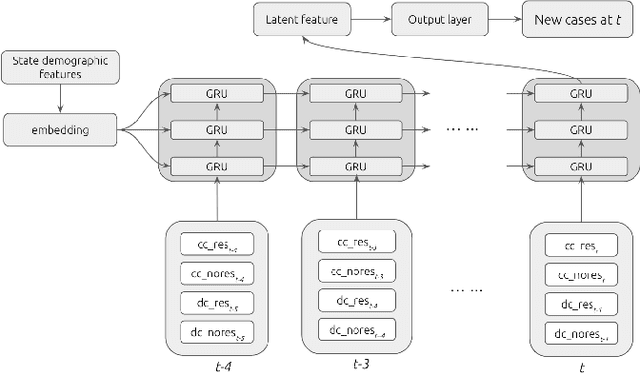
In this work, we developed a deep learning model-based approach to forecast the spreading trend of SARS-CoV-2 in the United States. We implemented the designed model using the United States to confirm cases and state demographic data and achieved promising trend prediction results. The model incorporates demographic information and epidemic time-series data through a Gated Recurrent Unit structure. The identification of dominating demographic factors is delivered in the end.
A Group-Theoretic Framework for Knowledge Graph Embedding
May 22, 2020


We demonstrated the existence of a group algebraic structure hidden in relational knowledge embedding problems, which suggests that a group-based embedding framework is essential for designing embedding models. Our theoretical analysis explores merely the intrinsic property of the embedding problem itself hence is model-independent. Motivated by the theoretical analysis, we have proposed a group theory-based knowledge graph embedding framework, in which relations are embedded as group elements, and entities are represented by vectors in group action spaces. We provide a generic recipe to construct embedding models associated with two instantiating examples: SO3E and SU2E, both of which apply a continuous non-Abelian group as the relation embedding. Empirical experiments using these two exampling models have shown state-of-the-art results on benchmark datasets.
Improved Structural Discovery and Representation Learning of Multi-Agent Data
Dec 30, 2019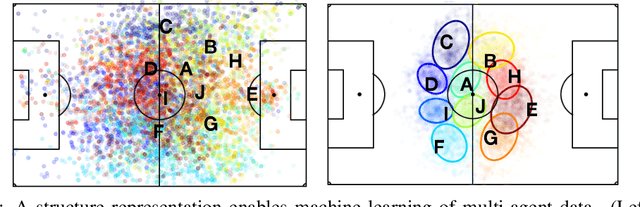
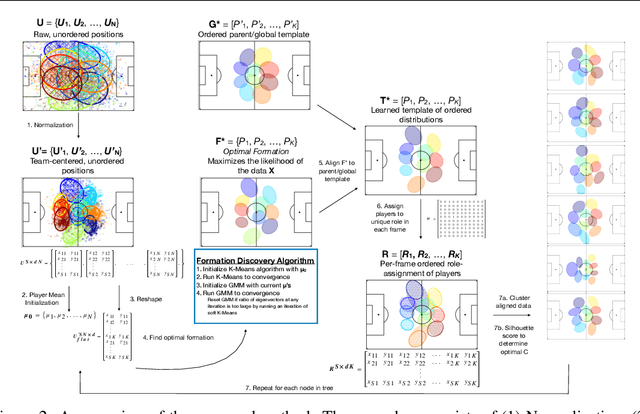
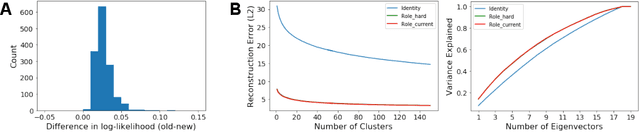
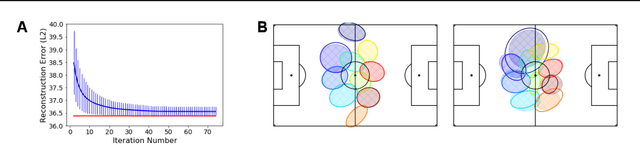
Central to all machine learning algorithms is data representation. For multi-agent systems, selecting a representation which adequately captures the interactions among agents is challenging due to the latent group structure which tends to vary depending on context. However, in multi-agent systems with strong group structure, we can simultaneously learn this structure and map a set of agents to a consistently ordered representation for further learning. In this paper, we present a dynamic alignment method which provides a robust ordering of structured multi-agent data enabling representation learning to occur in a fraction of the time of previous methods. We demonstrate the value of this approach using a large amount of soccer tracking data from a professional league.
Generative Multi-Agent Behavioral Cloning
May 20, 2018
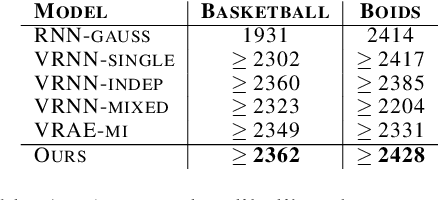
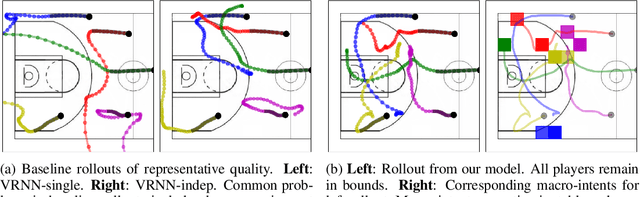
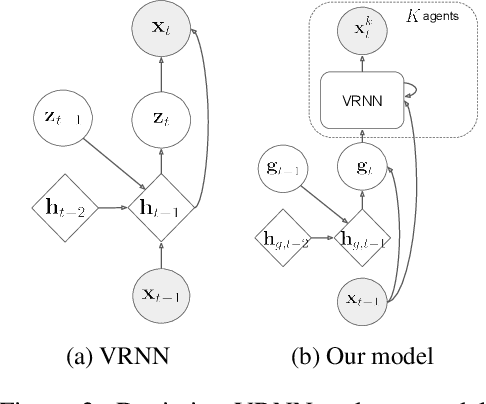
We propose and study the problem of generative multi-agent behavioral cloning, where the goal is to learn a generative, i.e., non-deterministic, multi-agent policy from pre-collected demonstration data. Building upon advances in deep generative models, we present a hierarchical policy framework that can tractably learn complex mappings from input states to distributions over multi-agent action spaces by introducing a hierarchy with macro-intent variables that encode long-term intent. In addition to synthetic settings, we show how to instantiate our framework to effectively model complex interactions between basketball players and generate realistic multi-agent trajectories of basketball gameplay over long time periods. We validate our approach using both quantitative and qualitative evaluations, including a user study comparison conducted with professional sports analysts.