 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Cannot Do That Ben Stokes: Dynamically Predicting Shot Type in Cricket Using a Personalized Deep Neural Network
Feb 03, 2021
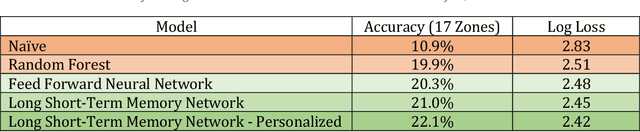


The ability to predict what shot a batsman will attempt given the type of ball and match situation is both one of the most challenging and strategically important tasks in cricket. The goal of the batsman is to score as many runs without being dismissed, whilst for bowlers their goal is to stem the flow of runs and ideally to dismiss their opponent. Getting the best batsman vs bowler match-up is of paramount importance. For example, for the fielding team, the choice of bowler against the opposition star batsman could be the key difference between winning or losing. Therefore, the ability to have a predefined playbook (as in the NFL) which would allow a team to predict how best to set their fielders given the context of the game, the batsman they are bowling to and bowlers at their disposal would give them a significant strategic advantage. To this end, we present a personalized deep neural network approach which can predict the probabilities of where a specific batsman will hit a specific bowler and bowl type, in a specific game-scenario. We demonstrate how our personalized predictions provide vital information to inform the decision-making of coaches and captains, both in terms of pre-match and in-game tactical choices, using the 2019 World Cup final between England and New Zealand as a case study example.
Improved Structural Discovery and Representation Learning of Multi-Agent Data
Dec 30, 2019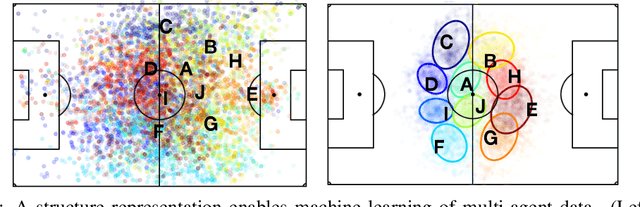
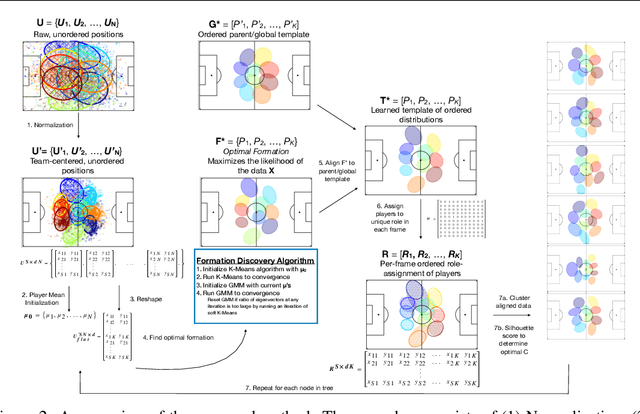
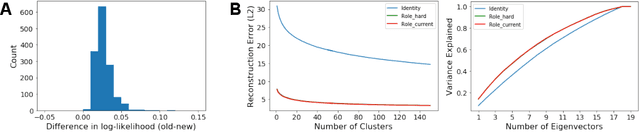
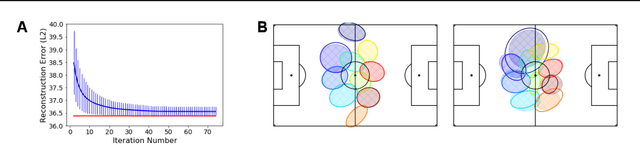
Central to all machine learning algorithms is data representation. For multi-agent systems, selecting a representation which adequately captures the interactions among agents is challenging due to the latent group structure which tends to vary depending on context. However, in multi-agent systems with strong group structure, we can simultaneously learn this structure and map a set of agents to a consistently ordered representation for further learning. In this paper, we present a dynamic alignment method which provides a robust ordering of structured multi-agent data enabling representation learning to occur in a fraction of the time of previous methods. We demonstrate the value of this approach using a large amount of soccer tracking data from a professional league.
Rugby-Bot: Utilizing Multi-Task Learning & Fine-Grained Features for Rugby League Analysis
Oct 16, 2019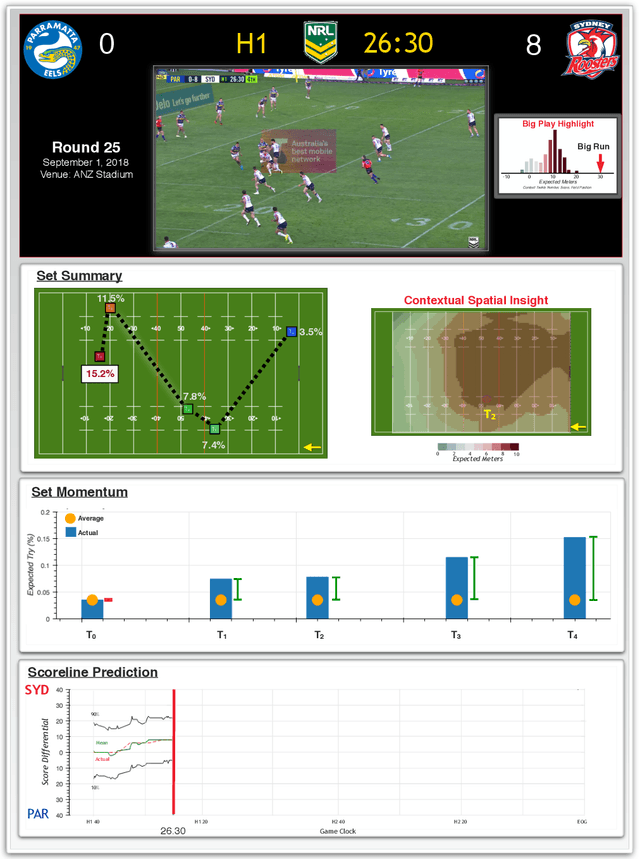
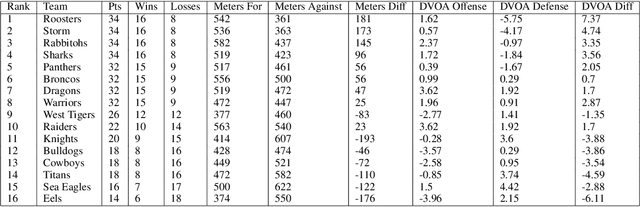
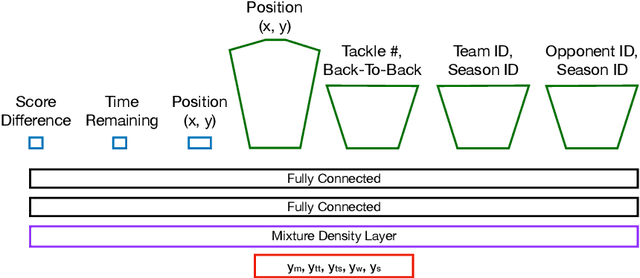

Sporting events are extremely complex and require a multitude of metrics to accurate describe the event. When making multiple predictions, one should make them from a single source to keep consistency across the predictions. We present a multi-task learning method of generating multiple predictions for analysis via a single prediction source. To enable this approach, we utilize a fine-grain representation using fine-grain spatial data using a wide-and-deep learning approach. Additionally, our approach can predict distributions rather than single point values. We highlighted the utility of our approach on the sport of Rugby League and call our prediction engine "Rugby-Bot".
Coordinated Multi-Agent Imitation Learning
May 25, 2018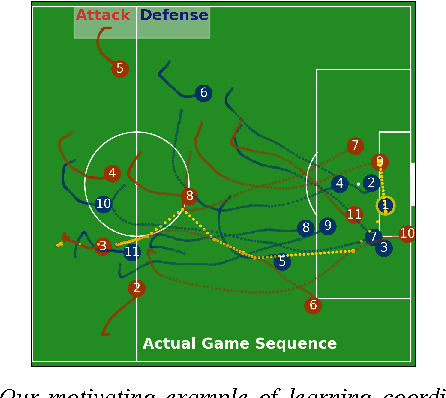
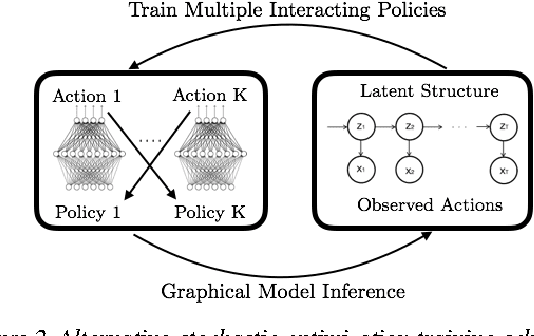
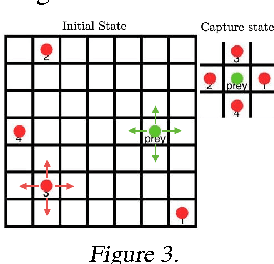
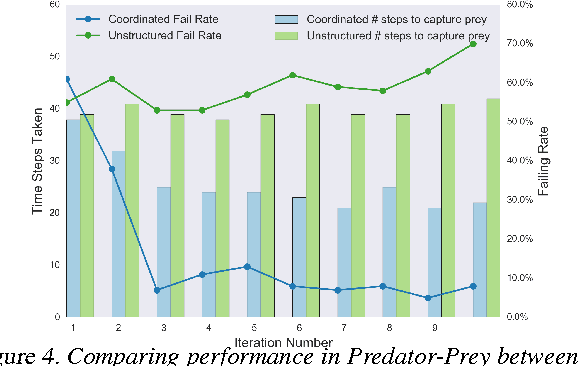
We study the problem of imitation learning from demonstrations of multiple coordinating agents. One key challenge in this setting is that learning a good model of coordination can be difficult, since coordination is often implicit in the demonstrations and must be inferred as a latent variable. We propose a joint approach that simultaneously learns a latent coordination model along with the individual policies. In particular, our method integrates unsupervised structure learning with conventional imitation learning. We illustrate the power of our approach on a difficult problem of learning multiple policies for fine-grained behavior modeling in team sports, where different players occupy different roles in the coordinated team strategy. We show that having a coordination model to infer the roles of players yields substantially improved imitation loss compared to conventional baselines.
* International Conference on Machine Learning 2017
Generative Multi-Agent Behavioral Cloning
May 20, 2018
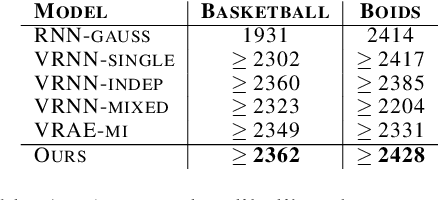
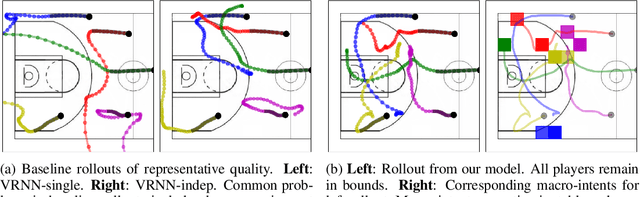
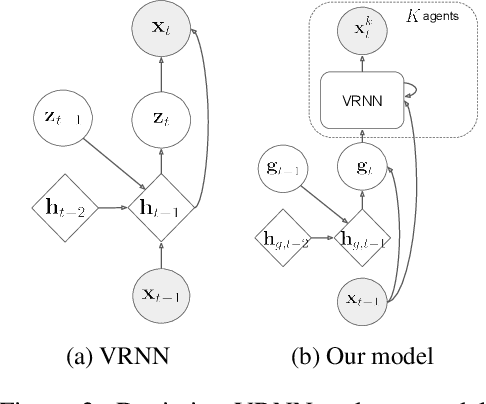
We propose and study the problem of generative multi-agent behavioral cloning, where the goal is to learn a generative, i.e., non-deterministic, multi-agent policy from pre-collected demonstration data. Building upon advances in deep generative models, we present a hierarchical policy framework that can tractably learn complex mappings from input states to distributions over multi-agent action spaces by introducing a hierarchy with macro-intent variables that encode long-term intent. In addition to synthetic settings, we show how to instantiate our framework to effectively model complex interactions between basketball players and generate realistic multi-agent trajectories of basketball gameplay over long time periods. We validate our approach using both quantitative and qualitative evaluations, including a user study comparison conducted with professional sports analysts.
Predicting Shot Making in Basketball Learnt from Adversarial Multiagent Trajectories
Dec 28, 2017

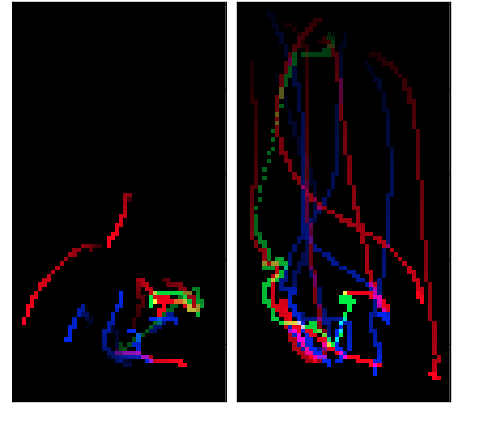
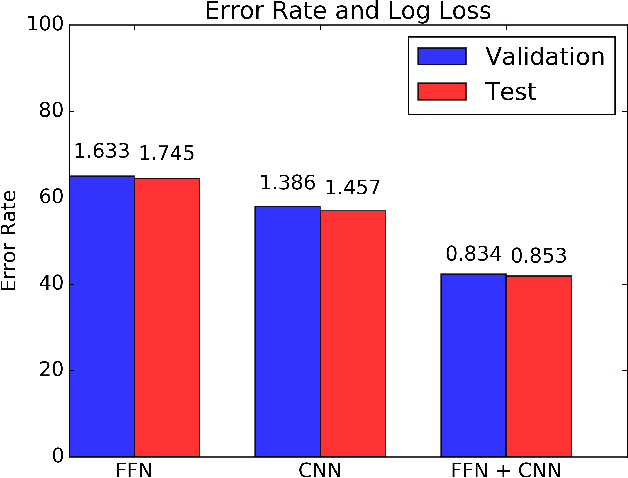
In this paper, we predict the likelihood of a player making a shot in basketball from multiagent trajectories. Previous approaches to similar problems center on hand-crafting features to capture domain specific knowledge. Although intuitive, recent work in deep learning has shown this approach is prone to missing important predictive features. To circumvent this issue, we present a convolutional neural network (CNN) approach where we initially represent the multiagent behavior as an image. To encode the adversarial nature of basketball, we use a multi-channel image which we then feed into a CNN. Additionally, to capture the temporal aspect of the trajectories we "fade" the player trajectories. We find that this approach is superior to a traditional FFN model. By using gradient ascent to create images using an already trained CNN, we discover what features the CNN filters learn. Last, we find that a combined CNN+FFN is the best performing network with an error rate of 39%.
Generating Long-term Trajectories Using Deep Hierarchical Networks
Jun 21, 2017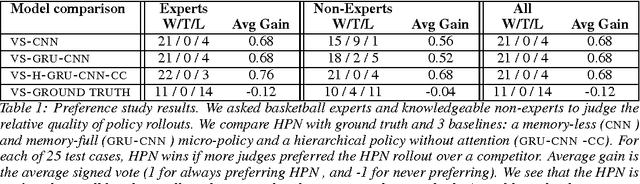
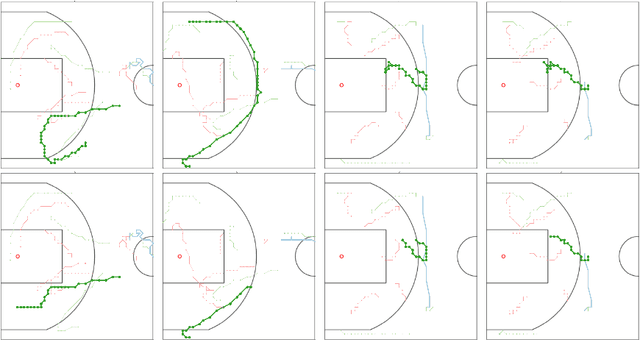
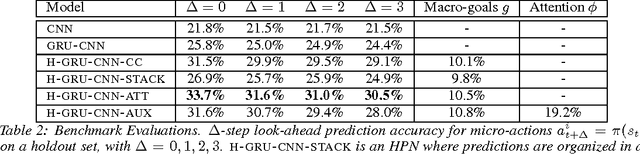
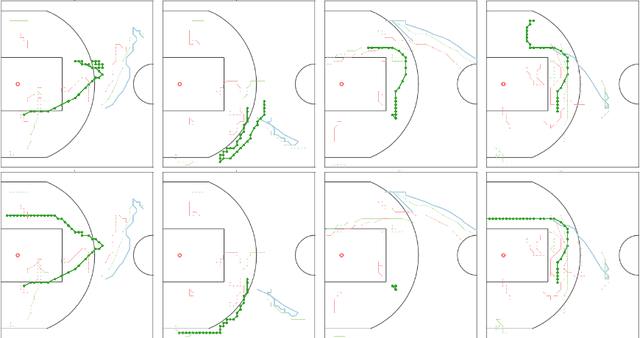
We study the problem of modeling spatiotemporal trajectories over long time horizons using expert demonstrations. For instance, in sports, agents often choose action sequences with long-term goals in mind, such as achieving a certain strategic position. Conventional policy learning approaches, such as those based on Markov decision processes, generally fail at learning cohesive long-term behavior in such high-dimensional state spaces, and are only effective when myopic modeling lead to the desired behavior. The key difficulty is that conventional approaches are "shallow" models that only learn a single state-action policy. We instead propose a hierarchical policy class that automatically reasons about both long-term and short-term goals, which we instantiate as a hierarchical neural network. We showcase our approach in a case study on learning to imitate demonstrated basketball trajectories, and show that it generates significantly more realistic trajectories compared to non-hierarchical baselines as judged by professional sports analysts.