 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Environment Design
Feb 21, 2024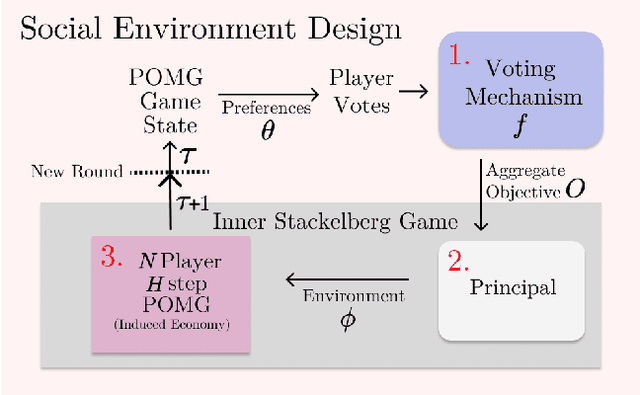
Artificial Intelligence (AI) holds promise as a technology that can be used to improve government and economic policy-making. This paper proposes a new research agenda towards this end by introducing Social Environment Design, a general framework for the use of AI for automated policy-making that connects with the Reinforcement Learning, EconCS, and Computational Social Choice communities. The framework seeks to capture general economic environments, includes voting on policy objectives, and gives a direction for the systematic analysis of government and economic policy through AI simulation. We highlight key open problems for future research in AI-based policy-making. By solving these challenges, we hope to achieve various social welfare objectives, thereby promoting more ethical and responsible decision making.
AI For Global Climate Cooperation 2023 Competition Proceedings
Jul 10, 2023The international community must collaborate to mitigate climate change and sustain economic growth. However, collaboration is hard to achieve, partly because no global authority can ensure compliance with international climate agreements. Combining AI with climate-economic simulations offers a promising solution to design international frameworks, including negotiation protocols and climate agreements, that promote and incentivize collaboration. In addition, these frameworks should also have policy goals fulfillment, and sustained commitment, taking into account climate-economic dynamics and strategic behaviors. These challenges require an interdisciplinary approach across machine learning, economics, climate science, law, policy, ethics, and other fields. Towards this objective, we organized AI for Global Climate Cooperation, a Mila competition in which teams submitted proposals and analyses of international frameworks, based on (modifications of) RICE-N, an AI-driven integrated assessment model (IAM). In particular, RICE-N supports modeling regional decision-making using AI agents. Furthermore, the IAM then models the climate-economic impact of those decisions into the future. Whereas the first track focused only on performance metrics, the proposals submitted to the second track were evaluated both quantitatively and qualitatively. The quantitative evaluation focused on a combination of (i) the degree of mitigation of global temperature rise and (ii) the increase in economic productivity. On the other hand, an interdisciplinary panel of human experts in law, policy, sociology, economics and environmental science, evaluated the solutions qualitatively. In particular, the panel considered the effectiveness, simplicity, feasibility, ethics, and notions of climate justice of the protocols. In the third track, the participants were asked to critique and improve RICE-N.
MERMAIDE: Learning to Align Learners using Model-Based Meta-Learning
Apr 10, 2023



We study how a principal can efficiently and effectively intervene on the rewards of a previously unseen learning agent in order to induce desirable outcomes. This is relevant to many real-world settings like auctions or taxation, where the principal may not know the learning behavior nor the rewards of real people. Moreover, the principal should be few-shot adaptable and minimize the number of interventions, because interventions are often costly. We introduce MERMAIDE, a model-based meta-learning framework to train a principal that can quickly adapt to out-of-distribution agents with different learning strategies and reward functions. We validate this approach step-by-step. First, in a Stackelberg setting with a best-response agent, we show that meta-learning enables quick convergence to the theoretically known Stackelberg equilibrium at test time, although noisy observations severely increase the sample complexity. We then show that our model-based meta-learning approach is cost-effective in intervening on bandit agents with unseen explore-exploit strategies. Finally, we outperform baselines that use either meta-learning or agent behavior modeling, in both $0$-shot and $K=1$-shot settings with partial agent information.
AI for Global Climate Cooperation: Modeling Global Climate Negotiations, Agreements, and Long-Term Cooperation in RICE-N
Aug 15, 2022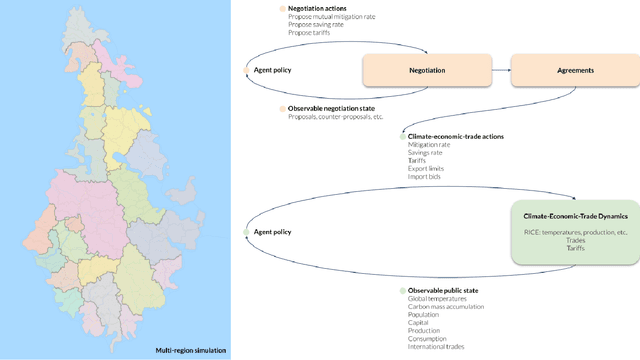
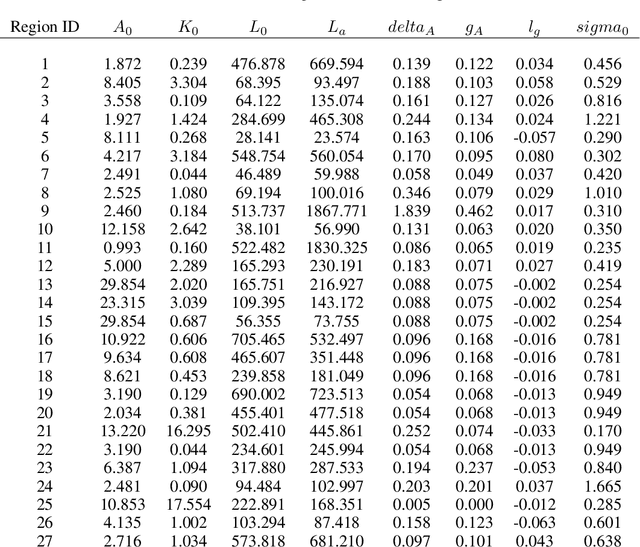
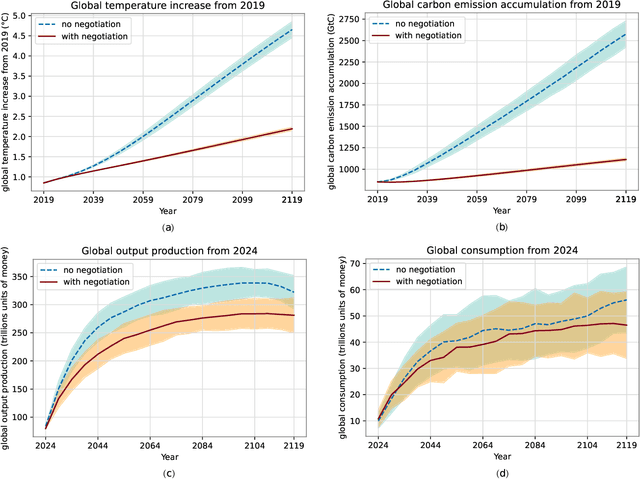

Comprehensive global cooperation is essential to limit global temperature increases while continuing economic development, e.g., reducing severe inequality or achieving long-term economic growth. Achieving long-term cooperation on climate change mitigation with n strategic agents poses a complex game-theoretic problem. For example, agents may negotiate and reach climate agreements, but there is no central authority to enforce adherence to those agreements. Hence, it is critical to design negotiation and agreement frameworks that foster cooperation, allow all agents to meet their individual policy objectives, and incentivize long-term adherence. This is an interdisciplinary challenge that calls for collaboration between researchers in machine learning, economics, climate science, law, policy, ethics, and other fields. In particular, we argue that machine learning is a critical tool to address the complexity of this domain. To facilitate this research, here we introduce RICE-N, a multi-region integrated assessment model that simulates the global climate and economy, and which can be used to design and evaluate the strategic outcomes for different negotiation and agreement frameworks. We also describe how to use multi-agent reinforcement learning to train rational agents using RICE-N. This framework underpinsAI for Global Climate Cooperation, a working group collaboration and competition on climate negotiation and agreement design. Here, we invite the scientific community to design and evaluate their solutions using RICE-N, machine learning, economic intuition, and other domain knowledge. More information can be found on www.ai4climatecoop.org.
Modeling Bounded Rationality in Multi-Agent Simulations Using Rationally Inattentive Reinforcement Learning
Jan 18, 2022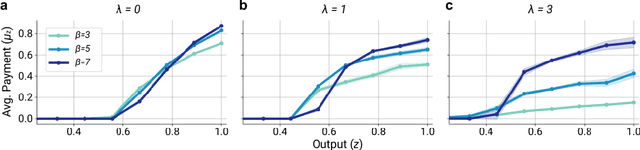
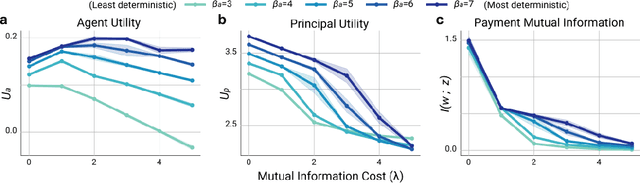
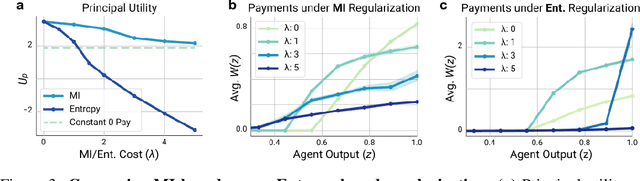
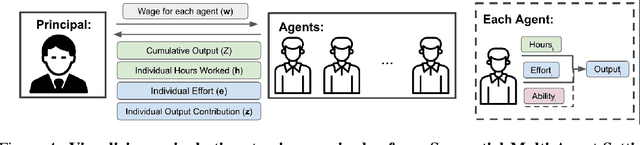
Multi-agent reinforcement learning (MARL) is a powerful framework for studying emergent behavior in complex agent-based simulations. However, RL agents are often assumed to be rational and behave optimally, which does not fully reflect human behavior. Here, we study more human-like RL agents which incorporate an established model of human-irrationality, the Rational Inattention (RI) model. RI models the cost of cognitive information processing using mutual information. Our RIRL framework generalizes and is more flexible than prior work by allowing for multi-timestep dynamics and information channels with heterogeneous processing costs. We evaluate RIRL in Principal-Agent (specifically manager-employee relations) problem settings of varying complexity where RI models information asymmetry (e.g. it may be costly for the manager to observe certain information about the employees). We show that using RIRL yields a rich spectrum of new equilibrium behaviors that differ from those found under rational assumptions. For instance, some forms of a Principal's inattention can increase Agent welfare due to increased compensation, while other forms of inattention can decrease Agent welfare by encouraging extra work effort. Additionally, new strategies emerge compared to those under rationality assumptions, e.g., Agents are incentivized to increase work effort. These results suggest RIRL is a powerful tool towards building AI agents that can mimic real human behavior.
Finding General Equilibria in Many-Agent Economic Simulations Using Deep Reinforcement Learning
Jan 03, 2022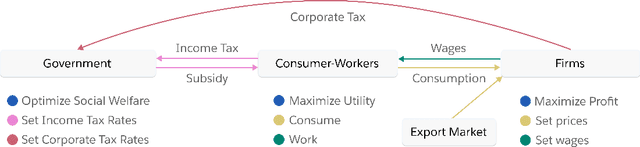

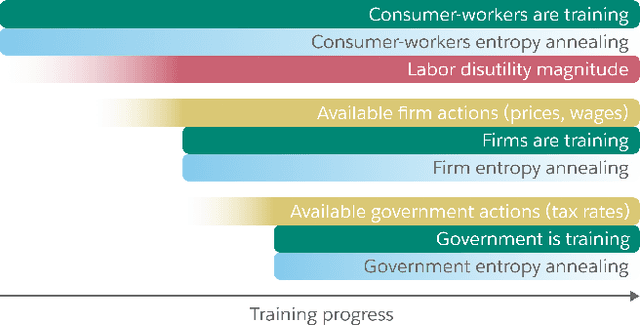
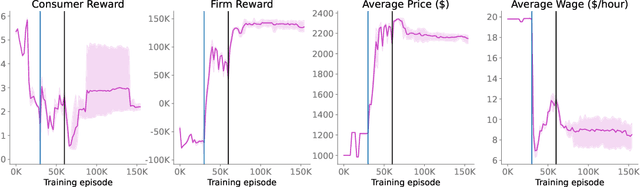
Real economies can be seen as a sequential imperfect-information game with many heterogeneous, interacting strategic agents of various agent types, such as consumers, firms, and governments. Dynamic general equilibrium models are common economic tools to model the economic activity, interactions, and outcomes in such systems. However, existing analytical and computational methods struggle to find explicit equilibria when all agents are strategic and interact, while joint learning is unstable and challenging. Amongst others, a key reason is that the actions of one economic agent may change the reward function of another agent, e.g., a consumer's expendable income changes when firms change prices or governments change taxes. We show that multi-agent deep reinforcement learning (RL) can discover stable solutions that are epsilon-Nash equilibria for a meta-game over agent types, in economic simulations with many agents, through the use of structured learning curricula and efficient GPU-only simulation and training. Conceptually, our approach is more flexible and does not need unrealistic assumptions, e.g., market clearing, that are commonly used for analytical tractability. Our GPU implementation enables training and analyzing economies with a large number of agents within reasonable time frames, e.g., training completes within a day. We demonstrate our approach in real-business-cycle models, a representative family of DGE models, with 100 worker-consumers, 10 firms, and a government who taxes and redistributes. We validate the learned meta-game epsilon-Nash equilibria through approximate best-response analyses, show that RL policies align with economic intuitions, and that our approach is constructive, e.g., by explicitly learning a spectrum of meta-game epsilon-Nash equilibria in open RBC models.
Simulation Intelligence: Towards a New Generation of Scientific Methods
Dec 06, 2021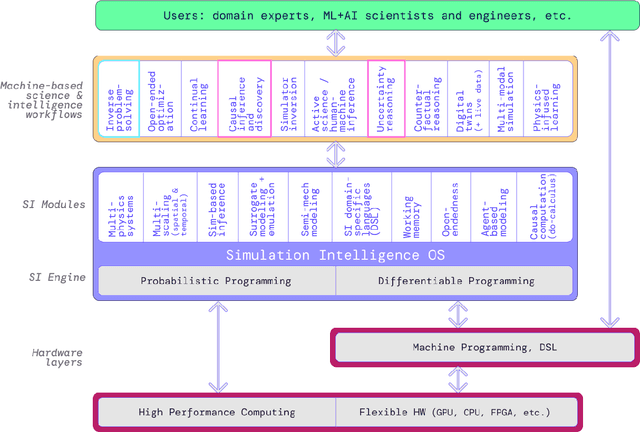
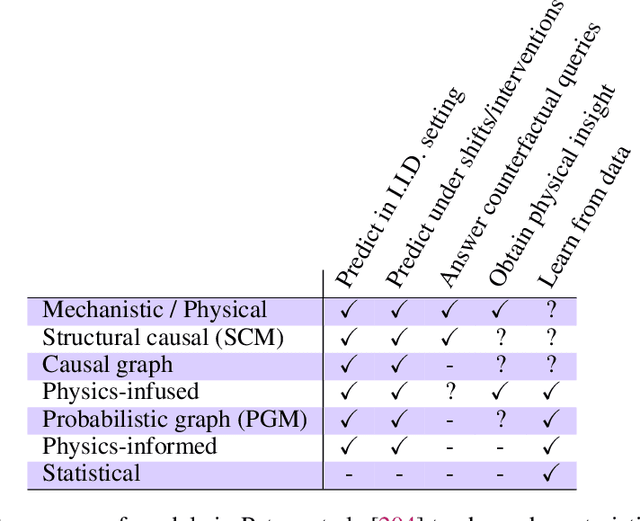
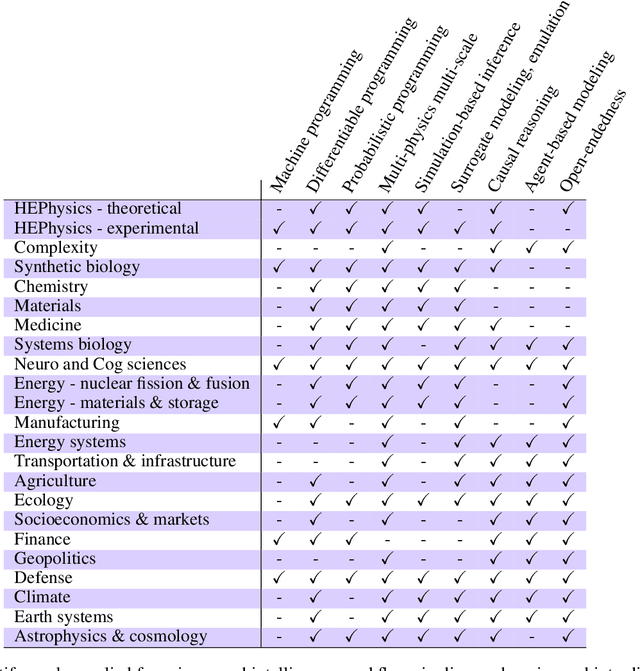
The original "Seven Motifs" set forth a roadmap of essential methods for the field of scientific computing, where a motif is an algorithmic method that captures a pattern of computation and data movement. We present the "Nine Motifs of Simulation Intelligence", a roadmap for the development and integration of the essential algorithms necessary for a merger of scientific computing, scientific simulation, and artificial intelligence. We call this merger simulation intelligence (SI), for short. We argue the motifs of simulation intelligence are interconnected and interdependent, much like the components within the layers of an operating system. Using this metaphor, we explore the nature of each layer of the simulation intelligence operating system stack (SI-stack) and the motifs therein: (1) Multi-physics and multi-scale modeling; (2) Surrogate modeling and emulation; (3) Simulation-based inference; (4) Causal modeling and inference; (5) Agent-based modeling; (6) Probabilistic programming; (7) Differentiable programming; (8) Open-ended optimization; (9) Machine programming. We believe coordinated efforts between motifs offers immense opportunity to accelerate scientific discovery, from solving inverse problems in synthetic biology and climate science, to directing nuclear energy experiments and predicting emergent behavior in socioeconomic settings. We elaborate on each layer of the SI-stack, detailing the state-of-art methods, presenting examples to highlight challenges and opportunities, and advocating for specific ways to advance the motifs and the synergies from their combinations. Advancing and integrating these technologies can enable a robust and efficient hypothesis-simulation-analysis type of scientific method, which we introduce with several use-cases for human-machine teaming and automated science.
WarpDrive: Extremely Fast End-to-End Deep Multi-Agent Reinforcement Learning on a GPU
Aug 31, 2021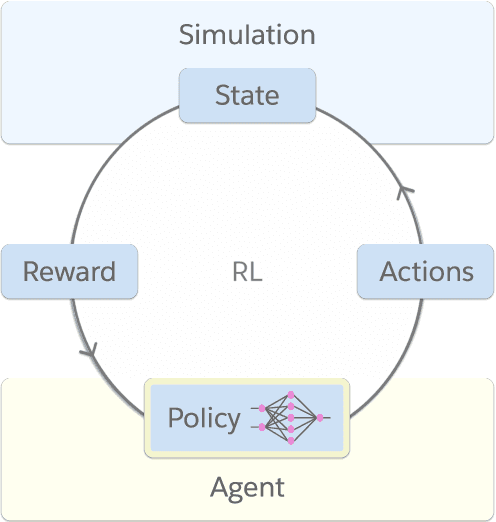
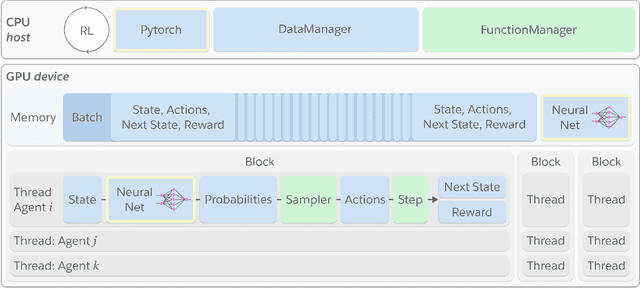

Deep reinforcement learning (RL) is a powerful framework to train decision-making models in complex dynamical environments. However, RL can be slow as it learns through repeated interaction with a simulation of the environment. Accelerating RL requires both algorithmic and engineering innovations. In particular, there are key systems engineering bottlenecks when using RL in complex environments that feature multiple agents or high-dimensional state, observation, or action spaces, for example. We present WarpDrive, a flexible, lightweight, and easy-to-use open-source RL framework that implements end-to-end multi-agent RL on a single GPU (Graphics Processing Unit), building on PyCUDA and PyTorch. Using the extreme parallelization capability of GPUs, WarpDrive enables orders-of-magnitude faster RL compared to common implementations that blend CPU simulations and GPU models. Our design runs simulations and the agents in each simulation in parallel. It eliminates data copying between CPU and GPU. It also uses a single simulation data store on the GPU that is safely updated in-place. Together, this allows the user to run thousands of concurrent multi-agent simulations and train on extremely large batches of experience. For example, WarpDrive yields 2.9 million environment steps/second with 2000 environments and 1000 agents (at least 100x higher throughput compared to a CPU implementation) in a benchmark Tag simulation. WarpDrive provides a lightweight Python interface and environment wrappers to simplify usage and promote flexibility and extensions. As such, WarpDrive provides a framework for building high-throughput RL systems.
Building a Foundation for Data-Driven, Interpretable, and Robust Policy Design using the AI Economist
Aug 06, 2021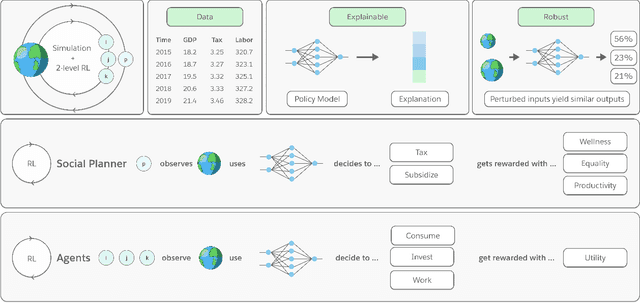

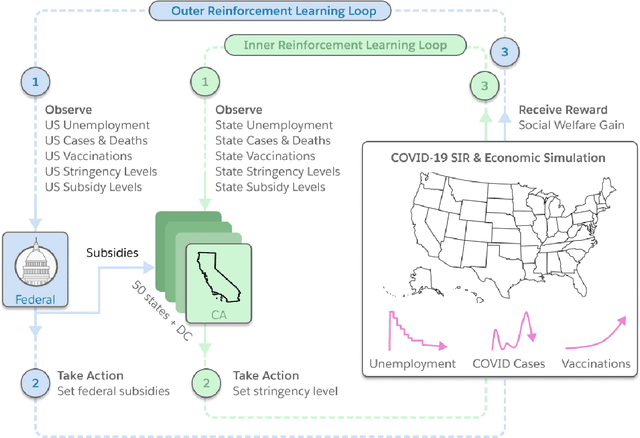
Optimizing economic and public policy is critical to address socioeconomic issues and trade-offs, e.g., improving equality, productivity, or wellness, and poses a complex mechanism design problem. A policy designer needs to consider multiple objectives, policy levers, and behavioral responses from strategic actors who optimize for their individual objectives. Moreover, real-world policies should be explainable and robust to simulation-to-reality gaps, e.g., due to calibration issues. Existing approaches are often limited to a narrow set of policy levers or objectives that are hard to measure, do not yield explicit optimal policies, or do not consider strategic behavior, for example. Hence, it remains challenging to optimize policy in real-world scenarios. Here we show that the AI Economist framework enables effective, flexible, and interpretable policy design using two-level reinforcement learning (RL) and data-driven simulations. We validate our framework on optimizing the stringency of US state policies and Federal subsidies during a pandemic, e.g., COVID-19, using a simulation fitted to real data. We find that log-linear policies trained using RL significantly improve social welfare, based on both public health and economic outcomes, compared to past outcomes. Their behavior can be explained, e.g., well-performing policies respond strongly to changes in recovery and vaccination rates. They are also robust to calibration errors, e.g., infection rates that are over or underestimated. As of yet, real-world policymaking has not seen adoption of machine learning methods at large, including RL and AI-driven simulations. Our results show the potential of AI to guide policy design and improve social welfare amidst the complexity of the real world.
The AI Economist: Optimal Economic Policy Design via Two-level Deep Reinforcement Learning
Aug 05, 2021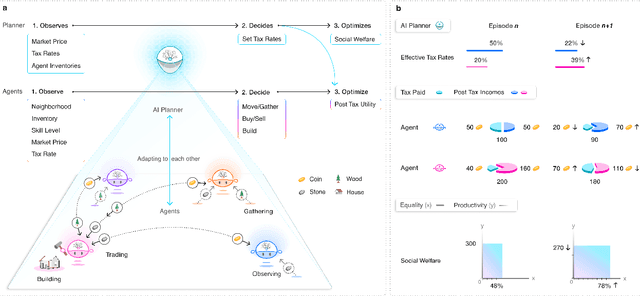
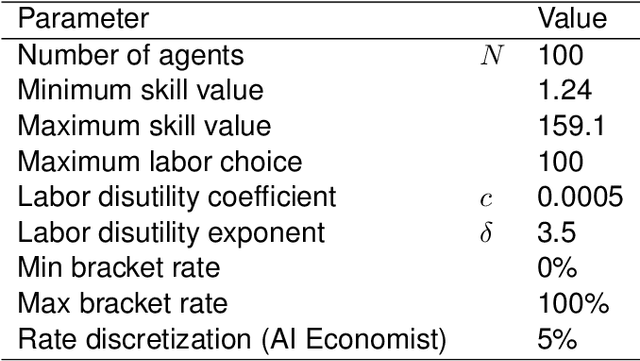
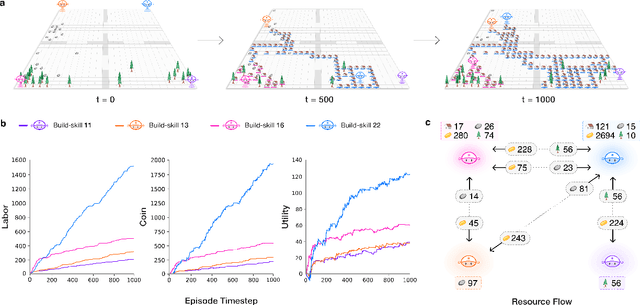
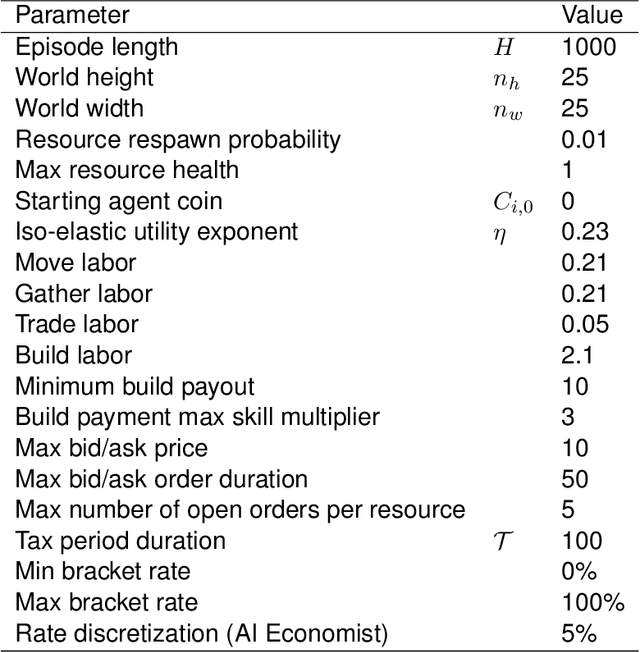
AI and reinforcement learning (RL) have improved many areas, but are not yet widely adopted in economic policy design, mechanism design, or economics at large. At the same time, current economic methodology is limited by a lack of counterfactual data, simplistic behavioral models, and limited opportunities to experiment with policies and evaluate behavioral responses. Here we show that machine-learning-based economic simulation is a powerful policy and mechanism design framework to overcome these limitations. The AI Economist is a two-level, deep RL framework that trains both agents and a social planner who co-adapt, providing a tractable solution to the highly unstable and novel two-level RL challenge. From a simple specification of an economy, we learn rational agent behaviors that adapt to learned planner policies and vice versa. We demonstrate the efficacy of the AI Economist on the problem of optimal taxation. In simple one-step economies, the AI Economist recovers the optimal tax policy of economic theory. In complex, dynamic economies, the AI Economist substantially improves both utilitarian social welfare and the trade-off between equality and productivity over baselines. It does so despite emergent tax-gaming strategies, while accounting for agent interactions and behavioral change more accurately than economic theory. These results demonstrate for the first time that two-level, deep RL can be used for understanding and as a complement to theory for economic design, unlocking a new computational learning-based approach to understanding economic policy.