 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Before You Leap: Using Serialized State Machine for Language Conditioned Robotic Manipulation
Mar 07, 2025



Imitation learning frameworks for robotic manipulation have drawn attention in the recent development of language model grounded robotics. However, the success of the frameworks largely depends on the coverage of the demonstration cases: When the demonstration set does not include examples of how to act in all possible situations, the action may fail and can result in cascading errors. To solve this problem, we propose a framework that uses serialized Finite State Machine (FSM) to generate demonstrations and improve the success rate in manipulation tasks requiring a long sequence of precise interactions. To validate its effectiveness, we use environmentally evolving and long-horizon puzzles that require long sequential actions. Experimental results show that our approach achieves a success rate of up to 98 in these tasks, compared to the controlled condition using existing approaches, which only had a success rate of up to 60, and, in some tasks, almost failed completely.
Rule Based Rewards for Language Model Safety
Nov 02, 2024Reinforcement learning based fine-tuning of large language models (LLMs) on human preferences has been shown to enhance both their capabilities and safety behavior. However, in cases related to safety, without precise instructions to human annotators, the data collected may cause the model to become overly cautious, or to respond in an undesirable style, such as being judgmental. Additionally, as model capabilities and usage patterns evolve, there may be a costly need to add or relabel data to modify safety behavior. We propose a novel preference modeling approach that utilizes AI feedback and only requires a small amount of human data. Our method, Rule Based Rewards (RBR), uses a collection of rules for desired or undesired behaviors (e.g. refusals should not be judgmental) along with a LLM grader. In contrast to prior methods using AI feedback, our method uses fine-grained, composable, LLM-graded few-shot prompts as reward directly in RL training, resulting in greater control, accuracy and ease of updating. We show that RBRs are an effective training method, achieving an F1 score of 97.1, compared to a human-feedback baseline of 91.7, resulting in much higher safety-behavior accuracy through better balancing usefulness and safety.
Simple Embodied Language Learning as a Byproduct of Meta-Reinforcement Learning
Jun 14, 2023



Whereas machine learning models typically learn language by directly training on language tasks (e.g., next-word prediction), language emerges in human children as a byproduct of solving non-language tasks (e.g., acquiring food). Motivated by this observation, we ask: can embodied reinforcement learning (RL) agents also indirectly learn language from non-language tasks? Learning to associate language with its meaning requires a dynamic environment with varied language. Therefore, we investigate this question in a multi-task environment with language that varies across the different tasks. Specifically, we design an office navigation environment, where the agent's goal is to find a particular office, and office locations differ in different buildings (i.e., tasks). Each building includes a floor plan with a simple language description of the goal office's location, which can be visually read as an RGB image when visited. We find RL agents indeed are able to indirectly learn language. Agents trained with current meta-RL algorithms successfully generalize to reading floor plans with held-out layouts and language phrases, and quickly navigate to the correct office, despite receiving no direct language supervision.
MC-MLP:Multiple Coordinate Frames in all-MLP Architecture for Vision
Apr 08, 2023



In deep learning, Multi-Layer Perceptrons (MLPs) have once again garnered attention from researchers. This paper introduces MC-MLP, a general MLP-like backbone for computer vision that is composed of a series of fully-connected (FC) layers. In MC-MLP, we propose that the same semantic information has varying levels of difficulty in learning, depending on the coordinate frame of features. To address this, we perform an orthogonal transform on the feature information, equivalent to changing the coordinate frame of features. Through this design, MC-MLP is equipped with multi-coordinate frame receptive fields and the ability to learn information across different coordinate frames. Experiments demonstrate that MC-MLP outperforms most MLPs in image classification tasks, achieving better performance at the same parameter level. The code will be available at: https://github.com/ZZM11/MC-MLP.
Modeling Bounded Rationality in Multi-Agent Simulations Using Rationally Inattentive Reinforcement Learning
Jan 18, 2022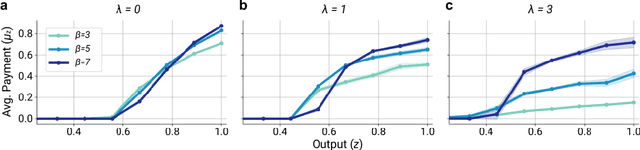
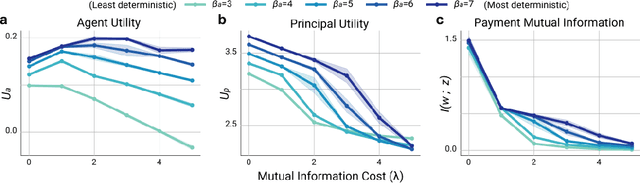
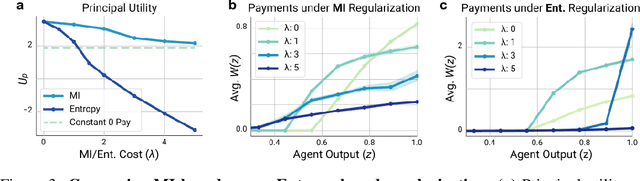
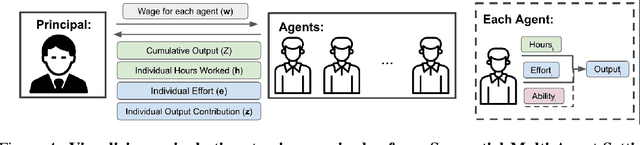
Multi-agent reinforcement learning (MARL) is a powerful framework for studying emergent behavior in complex agent-based simulations. However, RL agents are often assumed to be rational and behave optimally, which does not fully reflect human behavior. Here, we study more human-like RL agents which incorporate an established model of human-irrationality, the Rational Inattention (RI) model. RI models the cost of cognitive information processing using mutual information. Our RIRL framework generalizes and is more flexible than prior work by allowing for multi-timestep dynamics and information channels with heterogeneous processing costs. We evaluate RIRL in Principal-Agent (specifically manager-employee relations) problem settings of varying complexity where RI models information asymmetry (e.g. it may be costly for the manager to observe certain information about the employees). We show that using RIRL yields a rich spectrum of new equilibrium behaviors that differ from those found under rational assumptions. For instance, some forms of a Principal's inattention can increase Agent welfare due to increased compensation, while other forms of inattention can decrease Agent welfare by encouraging extra work effort. Additionally, new strategies emerge compared to those under rationality assumptions, e.g., Agents are incentivized to increase work effort. These results suggest RIRL is a powerful tool towards building AI agents that can mimic real human behavior.
Constraint Sampling Reinforcement Learning: Incorporating Expertise For Faster Learning
Dec 30, 2021


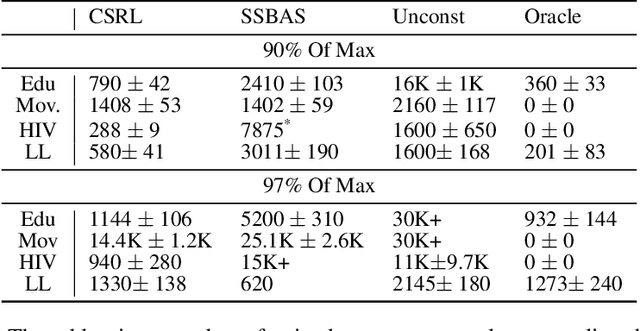
Online reinforcement learning (RL) algorithms are often difficult to deploy in complex human-facing applications as they may learn slowly and have poor early performance. To address this, we introduce a practical algorithm for incorporating human insight to speed learning. Our algorithm, Constraint Sampling Reinforcement Learning (CSRL), incorporates prior domain knowledge as constraints/restrictions on the RL policy. It takes in multiple potential policy constraints to maintain robustness to misspecification of individual constraints while leveraging helpful ones to learn quickly. Given a base RL learning algorithm (ex. UCRL, DQN, Rainbow) we propose an upper confidence with elimination scheme that leverages the relationship between the constraints, and their observed performance, to adaptively switch among them. We instantiate our algorithm with DQN-type algorithms and UCRL as base algorithms, and evaluate our algorithm in four environments, including three simulators based on real data: recommendations, educational activity sequencing, and HIV treatment sequencing. In all cases, CSRL learns a good policy faster than baselines.
PLOTS: Procedure Learning from Observations using Subtask Structure
Apr 17, 2019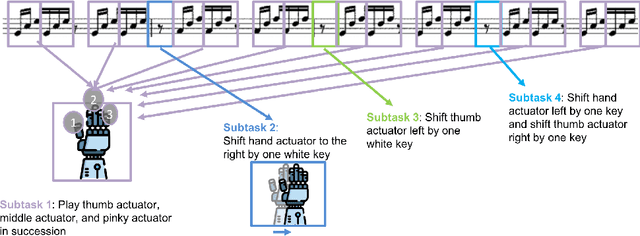
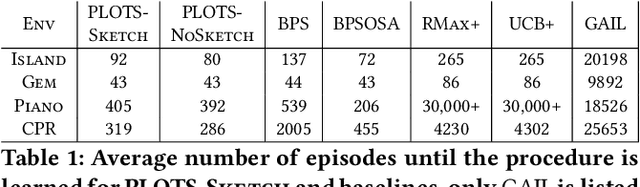
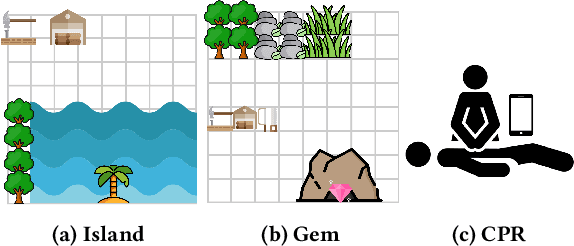
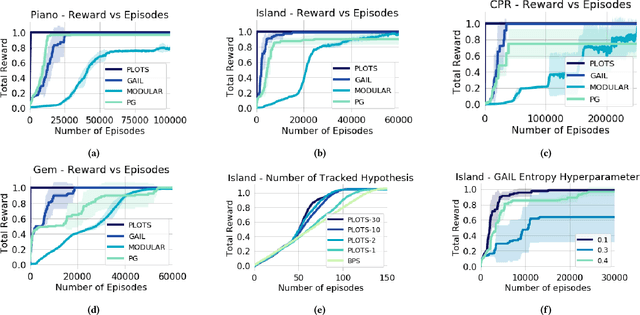
In many cases an intelligent agent may want to learn how to mimic a single observed demonstrated trajectory. In this work we consider how to perform such procedural learning from observation, which could help to enable agents to better use the enormous set of video data on observation sequences. Our approach exploits the properties of this setting to incrementally build an open loop action plan that can yield the desired subsequence, and can be used in both Markov and partially observable Markov domains. In addition, procedures commonly involve repeated extended temporal action subsequences. Our method optimistically explores actions to leverage potential repeated structure in the procedure. In comparing to some state-of-the-art approaches we find that our explicit procedural learning from observation method is about 100 times faster than policy-gradient based approaches that learn a stochastic policy and is faster than model based approaches as well. We also find that performing optimistic action selection yields substantial speed ups when latent dynamical structure is present.