 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectively Modeling Time Series with Simple Discrete State Spaces
Mar 16, 2023



Time series modeling is a well-established problem, which often requires that methods (1) expressively represent complicated dependencies, (2) forecast long horizons, and (3) efficiently train over long sequences. State-space models (SSMs) are classical models for time series, and prior works combine SSMs with deep learning layers for efficient sequence modeling. However, we find fundamental limitations with these prior approaches, proving their SSM representations cannot express autoregressive time series processes. We thus introduce SpaceTime, a new state-space time series architecture that improves all three criteria. For expressivity, we propose a new SSM parameterization based on the companion matrix -- a canonical representation for discrete-time processes -- which enables SpaceTime's SSM layers to learn desirable autoregressive processes. For long horizon forecasting, we introduce a "closed-loop" variation of the companion SSM, which enables SpaceTime to predict many future time-steps by generating its own layer-wise inputs. For efficient training and inference, we introduce an algorithm that reduces the memory and compute of a forward pass with the companion matrix. With sequence length $\ell$ and state-space size $d$, we go from $\tilde{O}(d \ell)$ na\"ively to $\tilde{O}(d + \ell)$. In experiments, our contributions lead to state-of-the-art results on extensive and diverse benchmarks, with best or second-best AUROC on 6 / 7 ECG and speech time series classification, and best MSE on 14 / 16 Informer forecasting tasks. Furthermore, we find SpaceTime (1) fits AR($p$) processes that prior deep SSMs fail on, (2) forecasts notably more accurately on longer horizons than prior state-of-the-art, and (3) speeds up training on real-world ETTh1 data by 73% and 80% relative wall-clock time over Transformers and LSTMs.
S4ND: Modeling Images and Videos as Multidimensional Signals Using State Spaces
Oct 14, 2022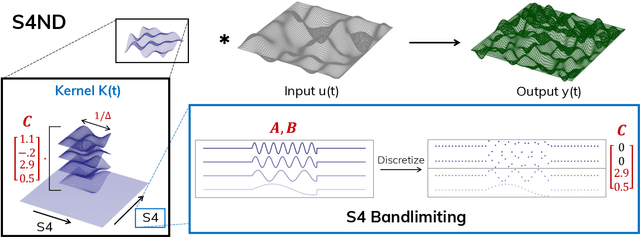
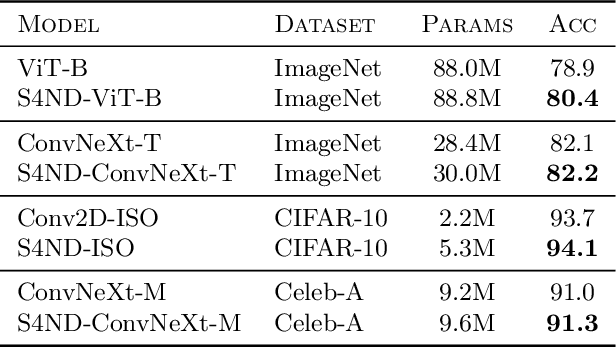
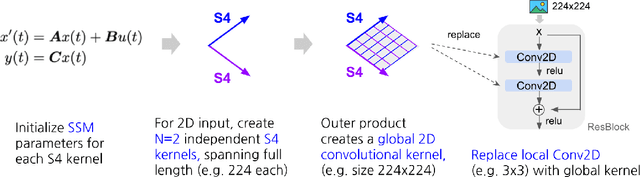
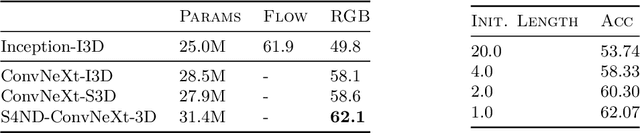
Visual data such as images and videos are typically modeled as discretizations of inherently continuous, multidimensional signals. Existing continuous-signal models attempt to exploit this fact by modeling the underlying signals of visual (e.g., image) data directly. However, these models have not yet been able to achieve competitive performance on practical vision tasks such as large-scale image and video classification. Building on a recent line of work on deep state space models (SSMs), we propose S4ND, a new multidimensional SSM layer that extends the continuous-signal modeling ability of SSMs to multidimensional data including images and videos. We show that S4ND can model large-scale visual data in $1$D, $2$D, and $3$D as continuous multidimensional signals and demonstrates strong performance by simply swapping Conv2D and self-attention layers with S4ND layers in existing state-of-the-art models. On ImageNet-1k, S4ND exceeds the performance of a Vision Transformer baseline by $1.5\%$ when training with a $1$D sequence of patches, and matches ConvNeXt when modeling images in $2$D. For videos, S4ND improves on an inflated $3$D ConvNeXt in activity classification on HMDB-51 by $4\%$. S4ND implicitly learns global, continuous convolutional kernels that are resolution invariant by construction, providing an inductive bias that enables generalization across multiple resolutions. By developing a simple bandlimiting modification to S4 to overcome aliasing, S4ND achieves strong zero-shot (unseen at training time) resolution performance, outperforming a baseline Conv2D by $40\%$ on CIFAR-10 when trained on $8 \times 8$ and tested on $32 \times 32$ images. When trained with progressive resizing, S4ND comes within $\sim 1\%$ of a high-resolution model while training $22\%$ faster.
On the Parameterization and Initialization of Diagonal State Space Models
Jun 23, 2022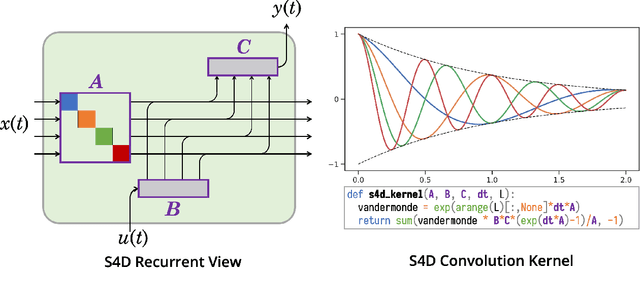

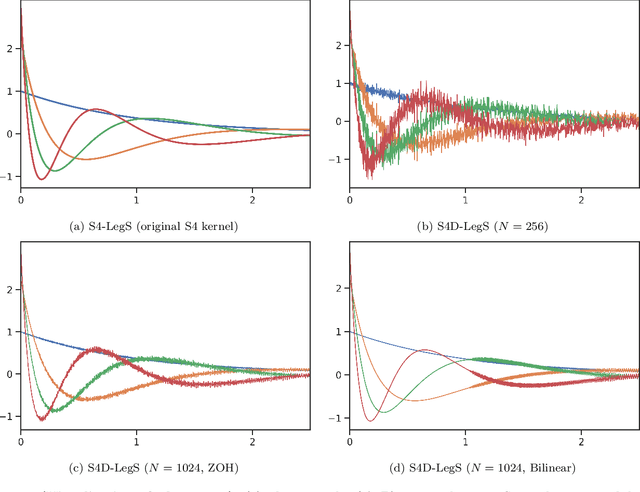

State space models (SSM) have recently been shown to be very effective as a deep learning layer as a promising alternative to sequence models such as RNNs, CNNs, or Transformers. The first version to show this potential was the S4 model, which is particularly effective on tasks involving long-range dependencies by using a prescribed state matrix called the HiPPO matrix. While this has an interpretable mathematical mechanism for modeling long dependencies, it introduces a custom representation and algorithm that can be difficult to implement. On the other hand, a recent variant of S4 called DSS showed that restricting the state matrix to be fully diagonal can still preserve the performance of the original model when using a specific initialization based on approximating S4's matrix. This work seeks to systematically understand how to parameterize and initialize such diagonal state space models. While it follows from classical results that almost all SSMs have an equivalent diagonal form, we show that the initialization is critical for performance. We explain why DSS works mathematically, by showing that the diagonal restriction of S4's matrix surprisingly recovers the same kernel in the limit of infinite state dimension. We also systematically describe various design choices in parameterizing and computing diagonal SSMs, and perform a controlled empirical study ablating the effects of these choices. Our final model S4D is a simple diagonal version of S4 whose kernel computation requires just 2 lines of code and performs comparably to S4 in almost all settings, with state-of-the-art results for image, audio, and medical time-series domains, and averaging 85\% on the Long Range Arena benchmark.
It's Raw! Audio Generation with State-Space Models
Feb 20, 2022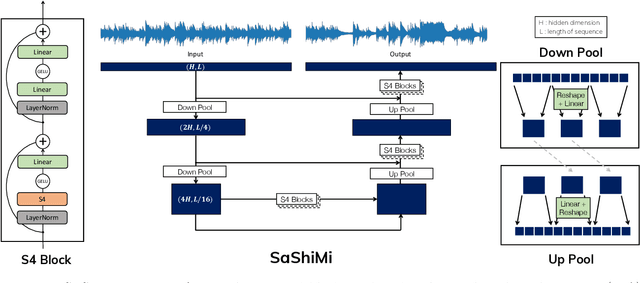

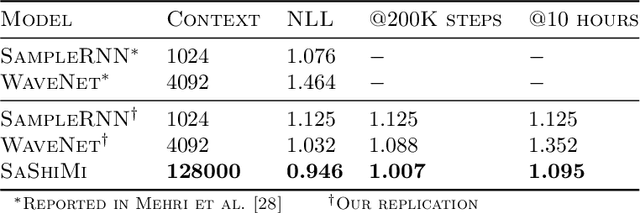
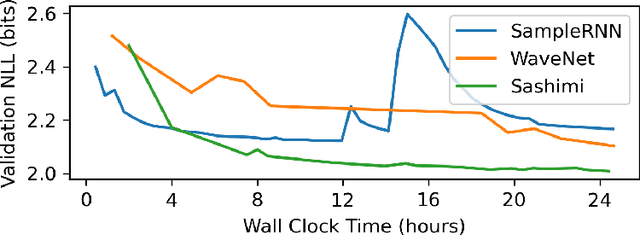
Developing architectures suitable for modeling raw audio is a challenging problem due to the high sampling rates of audio waveforms. Standard sequence modeling approaches like RNNs and CNNs have previously been tailored to fit the demands of audio, but the resultant architectures make undesirable computational tradeoffs and struggle to model waveforms effectively. We propose SaShiMi, a new multi-scale architecture for waveform modeling built around the recently introduced S4 model for long sequence modeling. We identify that S4 can be unstable during autoregressive generation, and provide a simple improvement to its parameterization by drawing connections to Hurwitz matrices. SaShiMi yields state-of-the-art performance for unconditional waveform generation in the autoregressive setting. Additionally, SaShiMi improves non-autoregressive generation performance when used as the backbone architecture for a diffusion model. Compared to prior architectures in the autoregressive generation setting, SaShiMi generates piano and speech waveforms which humans find more musical and coherent respectively, e.g. 2x better mean opinion scores than WaveNet on an unconditional speech generation task. On a music generation task, SaShiMi outperforms WaveNet on density estimation and speed at both training and inference even when using 3x fewer parameters. Code can be found at https://github.com/HazyResearch/state-spaces and samples at https://hazyresearch.stanford.edu/sashimi-examples.
Personalized Benchmarking with the Ludwig Benchmarking Toolkit
Nov 08, 2021
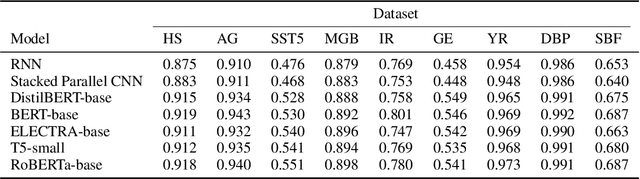
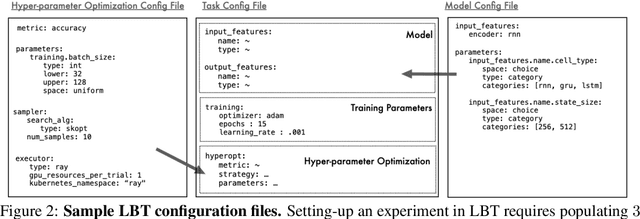
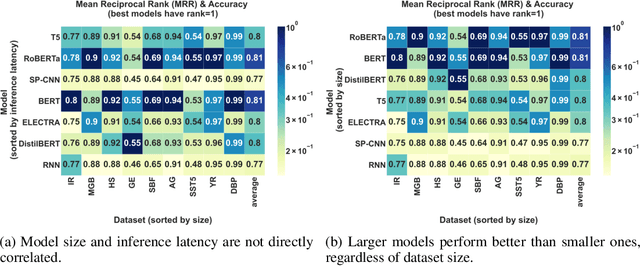
The rapid proliferation of machine learning models across domains and deployment settings has given rise to various communities (e.g. industry practitioners) which seek to benchmark models across tasks and objectives of personal value. Unfortunately, these users cannot use standard benchmark results to perform such value-driven comparisons as traditional benchmarks evaluate models on a single objective (e.g. average accuracy) and fail to facilitate a standardized training framework that controls for confounding variables (e.g. computational budget), making fair comparisons difficult. To address these challenges, we introduce the open-source Ludwig Benchmarking Toolkit (LBT), a personalized benchmarking toolkit for running end-to-end benchmark studies (from hyperparameter optimization to evaluation) across an easily extensible set of tasks, deep learning models, datasets and evaluation metrics. LBT provides a configurable interface for controlling training and customizing evaluation, a standardized training framework for eliminating confounding variables, and support for multi-objective evaluation. We demonstrate how LBT can be used to create personalized benchmark studies with a large-scale comparative analysis for text classification across 7 models and 9 datasets. We explore the trade-offs between inference latency and performance, relationships between dataset attributes and performance, and the effects of pretraining on convergence and robustness, showing how LBT can be used to satisfy various benchmarking objectives.
Efficiently Modeling Long Sequences with Structured State Spaces
Oct 31, 2021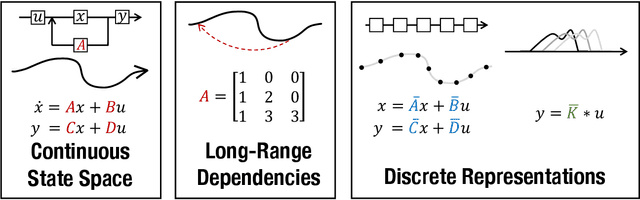
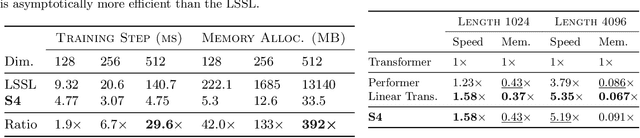


A central goal of sequence modeling is designing a single principled model that can address sequence data across a range of modalities and tasks, particularly on long-range dependencies. Although conventional models including RNNs, CNNs, and Transformers have specialized variants for capturing long dependencies, they still struggle to scale to very long sequences of $10000$ or more steps. A promising recent approach proposed modeling sequences by simulating the fundamental state space model (SSM) \( x'(t) = Ax(t) + Bu(t), y(t) = Cx(t) + Du(t) \), and showed that for appropriate choices of the state matrix \( A \), this system could handle long-range dependencies mathematically and empirically. However, this method has prohibitive computation and memory requirements, rendering it infeasible as a general sequence modeling solution. We propose the Structured State Space (S4) sequence model based on a new parameterization for the SSM, and show that it can be computed much more efficiently than prior approaches while preserving their theoretical strengths. Our technique involves conditioning \( A \) with a low-rank correction, allowing it to be diagonalized stably and reducing the SSM to the well-studied computation of a Cauchy kernel. S4 achieves strong empirical results across a diverse range of established benchmarks, including (i) 91\% accuracy on sequential CIFAR-10 with no data augmentation or auxiliary losses, on par with a larger 2-D ResNet, (ii) substantially closing the gap to Transformers on image and language modeling tasks, while performing generation $60\times$ faster (iii) SoTA on every task from the Long Range Arena benchmark, including solving the challenging Path-X task of length 16k that all prior work fails on, while being as efficient as all competitors.
Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers
Oct 26, 2021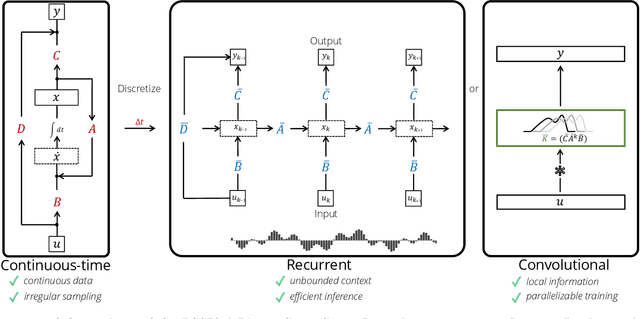
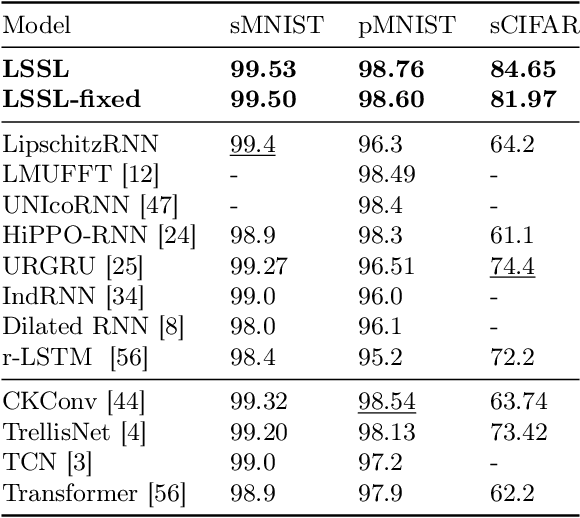
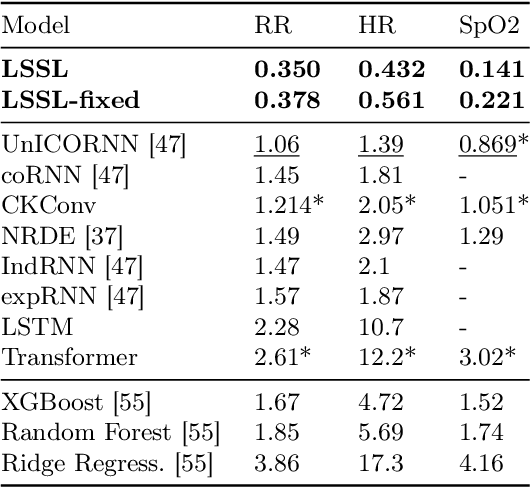
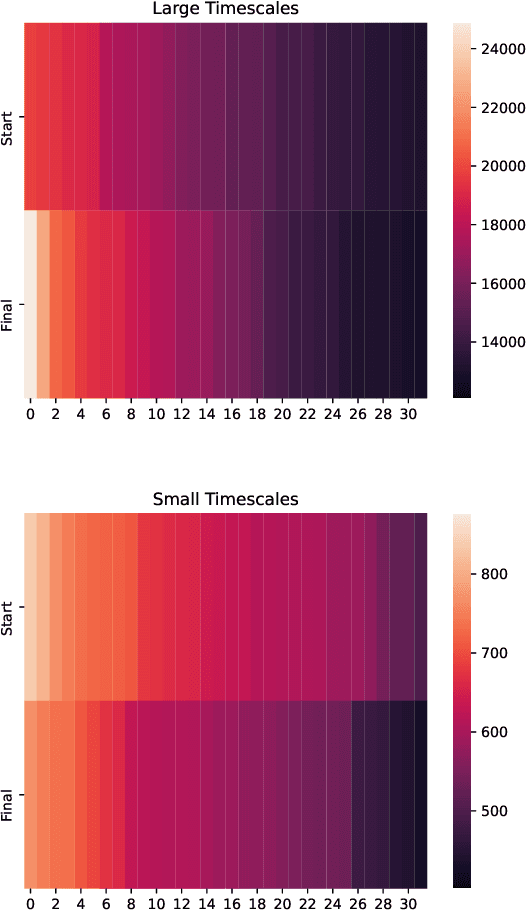
Recurrent neural networks (RNNs), temporal convolutions, and neural differential equations (NDEs) are popular families of deep learning models for time-series data, each with unique strengths and tradeoffs in modeling power and computational efficiency. We introduce a simple sequence model inspired by control systems that generalizes these approaches while addressing their shortcomings. The Linear State-Space Layer (LSSL) maps a sequence $u \mapsto y$ by simply simulating a linear continuous-time state-space representation $\dot{x} = Ax + Bu, y = Cx + Du$. Theoretically, we show that LSSL models are closely related to the three aforementioned families of models and inherit their strengths. For example, they generalize convolutions to continuous-time, explain common RNN heuristics, and share features of NDEs such as time-scale adaptation. We then incorporate and generalize recent theory on continuous-time memorization to introduce a trainable subset of structured matrices $A$ that endow LSSLs with long-range memory. Empirically, stacking LSSL layers into a simple deep neural network obtains state-of-the-art results across time series benchmarks for long dependencies in sequential image classification, real-world healthcare regression tasks, and speech. On a difficult speech classification task with length-16000 sequences, LSSL outperforms prior approaches by 24 accuracy points, and even outperforms baselines that use hand-crafted features on 100x shorter sequences.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Managing ML Pipelines: Feature Stores and the Coming Wave of Embedding Ecosystems
Aug 11, 2021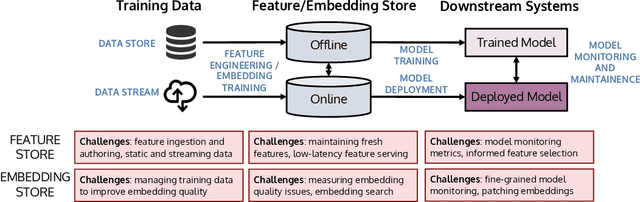
The industrial machine learning pipeline requires iterating on model features, training and deploying models, and monitoring deployed models at scale. Feature stores were developed to manage and standardize the engineer's workflow in this end-to-end pipeline, focusing on traditional tabular feature data. In recent years, however, model development has shifted towards using self-supervised pretrained embeddings as model features. Managing these embeddings and the downstream systems that use them introduces new challenges with respect to managing embedding training data, measuring embedding quality, and monitoring downstream models that use embeddings. These challenges are largely unaddressed in standard feature stores. Our goal in this tutorial is to introduce the feature store system and discuss the challenges and current solutions to managing these new embedding-centric pipelines.
Mandoline: Model Evaluation under Distribution Shift
Jul 01, 2021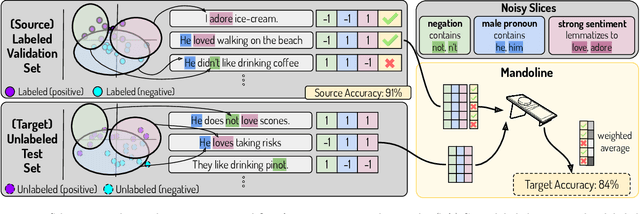
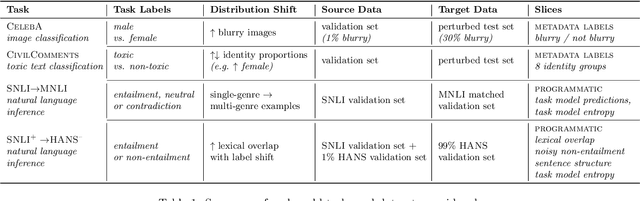
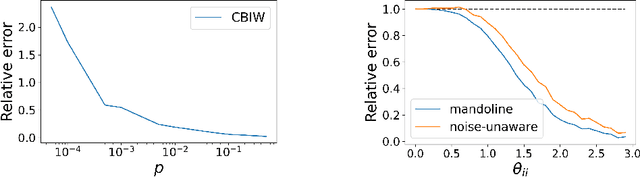
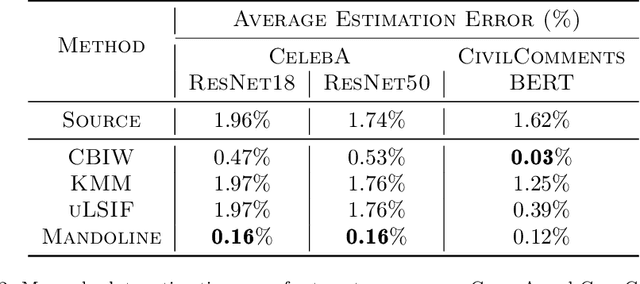
Machine learning models are often deployed in different settings than they were trained and validated on, posing a challenge to practitioners who wish to predict how well the deployed model will perform on a target distribution. If an unlabeled sample from the target distribution is available, along with a labeled sample from a possibly different source distribution, standard approaches such as importance weighting can be applied to estimate performance on the target. However, importance weighting struggles when the source and target distributions have non-overlapping support or are high-dimensional. Taking inspiration from fields such as epidemiology and polling, we develop Mandoline, a new evaluation framework that mitigates these issues. Our key insight is that practitioners may have prior knowledge about the ways in which the distribution shifts, which we can use to better guide the importance weighting procedure. Specifically, users write simple "slicing functions" - noisy, potentially correlated binary functions intended to capture possible axes of distribution shift - to compute reweighted performance estimates. We further describe a density ratio estimation framework for the slices and show how its estimation error scales with slice quality and dataset size. Empirical validation on NLP and vision tasks shows that \name can estimate performance on the target distribution up to $3\times$ more accurately compared to standard baselines.