 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligence per Watt: Measuring Intelligence Efficiency of Local AI
Nov 14, 2025Large language model (LLM) queries are predominantly processed by frontier models in centralized cloud infrastructure. Rapidly growing demand strains this paradigm, and cloud providers struggle to scale infrastructure at pace. Two advances enable us to rethink this paradigm: small LMs (<=20B active parameters) now achieve competitive performance to frontier models on many tasks, and local accelerators (e.g., Apple M4 Max) run these models at interactive latencies. This raises the question: can local inference viably redistribute demand from centralized infrastructure? Answering this requires measuring whether local LMs can accurately answer real-world queries and whether they can do so efficiently enough to be practical on power-constrained devices (i.e., laptops). We propose intelligence per watt (IPW), task accuracy divided by unit of power, as a metric for assessing capability and efficiency of local inference across model-accelerator pairs. We conduct a large-scale empirical study across 20+ state-of-the-art local LMs, 8 accelerators, and a representative subset of LLM traffic: 1M real-world single-turn chat and reasoning queries. For each query, we measure accuracy, energy, latency, and power. Our analysis reveals $3$ findings. First, local LMs can accurately answer 88.7% of single-turn chat and reasoning queries with accuracy varying by domain. Second, from 2023-2025, IPW improved 5.3x and local query coverage rose from 23.2% to 71.3%. Third, local accelerators achieve at least 1.4x lower IPW than cloud accelerators running identical models, revealing significant headroom for optimization. These findings demonstrate that local inference can meaningfully redistribute demand from centralized infrastructure, with IPW serving as the critical metric for tracking this transition. We release our IPW profiling harness for systematic intelligence-per-watt benchmarking.
Minions: Cost-efficient Collaboration Between On-device and Cloud Language Models
Feb 21, 2025We investigate an emerging setup in which a small, on-device language model (LM) with access to local data communicates with a frontier, cloud-hosted LM to solve real-world tasks involving financial, medical, and scientific reasoning over long documents. Can a local-remote collaboration reduce cloud inference costs while preserving quality? First, we consider a naive collaboration protocol where the local and remote models simply chat back and forth. Because only the local model reads the full context, this protocol achieves a 30.4x reduction in remote costs, but recovers only 87% of the performance of the frontier model. We identify two key limitations of this protocol: the local model struggles to (1) follow the remote model's multi-step instructions and (2) reason over long contexts. Motivated by these observations, we study an extension of this protocol, coined MinionS, in which the remote model decomposes the task into easier subtasks over shorter chunks of the document, that are executed locally in parallel. MinionS reduces costs by 5.7x on average while recovering 97.9% of the performance of the remote model alone. Our analysis reveals several key design choices that influence the trade-off between cost and performance in local-remote systems.
Cookbook: A framework for improving LLM generative abilities via programmatic data generating templates
Oct 07, 2024



Fine-tuning large language models (LLMs) on instruction datasets is a common way to improve their generative capabilities. However, instruction datasets can be expensive and time-consuming to manually curate, and while LLM-generated data is less labor-intensive, it may violate user privacy agreements or terms of service of LLM providers. Therefore, we seek a way of constructing instruction datasets with samples that are not generated by humans or LLMs but still improve LLM generative capabilities. In this work, we introduce Cookbook, a framework that programmatically generates training data consisting of simple patterns over random tokens, resulting in a scalable, cost-effective approach that avoids legal and privacy issues. First, Cookbook uses a template -- a data generating Python function -- to produce training data that encourages the model to learn an explicit pattern-based rule that corresponds to a desired task. We find that fine-tuning on Cookbook-generated data is able to improve performance on its corresponding task by up to 52.7 accuracy points. Second, since instruction datasets improve performance on multiple downstream tasks simultaneously, Cookbook algorithmically learns how to mix data from various templates to optimize performance on multiple tasks. On the standard multi-task GPT4ALL evaluation suite, Mistral-7B fine-tuned using a Cookbook-generated dataset attains the best accuracy on average compared to other 7B parameter instruction-tuned models and is the best performing model on 3 out of 8 tasks. Finally, we analyze when and why Cookbook improves performance and present a metric that allows us to verify that the improvement is largely explained by the model's generations adhering better to template rules.
Do Multimodal Foundation Models Understand Enterprise Workflows? A Benchmark for Business Process Management Tasks
Jun 19, 2024



Existing ML benchmarks lack the depth and diversity of annotations needed for evaluating models on business process management (BPM) tasks. BPM is the practice of documenting, measuring, improving, and automating enterprise workflows. However, research has focused almost exclusively on one task - full end-to-end automation using agents based on multimodal foundation models (FMs) like GPT-4. This focus on automation ignores the reality of how most BPM tools are applied today - simply documenting the relevant workflow takes 60% of the time of the typical process optimization project. To address this gap we present WONDERBREAD, the first benchmark for evaluating multimodal FMs on BPM tasks beyond automation. Our contributions are: (1) a dataset containing 2928 documented workflow demonstrations; (2) 6 novel BPM tasks sourced from real-world applications ranging from workflow documentation to knowledge transfer to process improvement; and (3) an automated evaluation harness. Our benchmark shows that while state-of-the-art FMs can automatically generate documentation (e.g. recalling 88% of the steps taken in a video demonstration of a workflow), they struggle to re-apply that knowledge towards finer-grained validation of workflow completion (F1 < 0.3). We hope WONDERBREAD encourages the development of more "human-centered" AI tooling for enterprise applications and furthers the exploration of multimodal FMs for the broader universe of BPM tasks. We publish our dataset and experiments here: https://github.com/HazyResearch/wonderbread
Automating the Enterprise with Foundation Models
May 03, 2024



Automating enterprise workflows could unlock $4 trillion/year in productivity gains. Despite being of interest to the data management community for decades, the ultimate vision of end-to-end workflow automation has remained elusive. Current solutions rely on process mining and robotic process automation (RPA), in which a bot is hard-coded to follow a set of predefined rules for completing a workflow. Through case studies of a hospital and large B2B enterprise, we find that the adoption of RPA has been inhibited by high set-up costs (12-18 months), unreliable execution (60% initial accuracy), and burdensome maintenance (requiring multiple FTEs). Multimodal foundation models (FMs) such as GPT-4 offer a promising new approach for end-to-end workflow automation given their generalized reasoning and planning abilities. To study these capabilities we propose ECLAIR, a system to automate enterprise workflows with minimal human supervision. We conduct initial experiments showing that multimodal FMs can address the limitations of traditional RPA with (1) near-human-level understanding of workflows (93% accuracy on a workflow understanding task) and (2) instant set-up with minimal technical barrier (based solely on a natural language description of a workflow, ECLAIR achieves end-to-end completion rates of 40%). We identify human-AI collaboration, validation, and self-improvement as open challenges, and suggest ways they can be solved with data management techniques. Code is available at: https://github.com/HazyResearch/eclair-agents
TART: A plug-and-play Transformer module for task-agnostic reasoning
Jun 13, 2023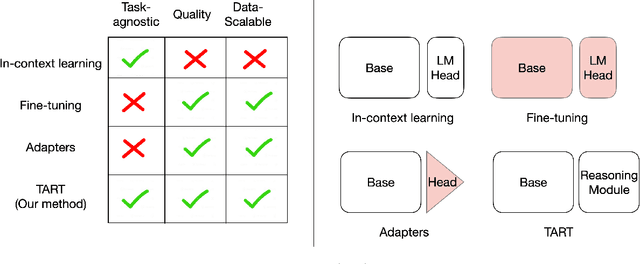

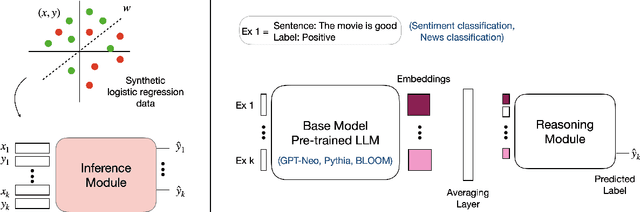
Large language models (LLMs) exhibit in-context learning abilities which enable the same model to perform several tasks without any task-specific training. In contrast, traditional adaptation approaches, such as fine-tuning, modify the underlying models for each specific task. In-context learning, however, consistently underperforms task-specific tuning approaches even when presented with the same examples. While most existing approaches (e.g., prompt engineering) focus on the LLM's learned representations to patch this performance gap, our analysis actually reveal that LLM representations contain sufficient information to make good predictions. As such, we focus on the LLM's reasoning abilities and demonstrate that this performance gap exists due to their inability to perform simple probabilistic reasoning tasks. This raises an intriguing question: Are LLMs actually capable of learning how to reason in a task-agnostic manner? We answer this in the affirmative and propose TART which generically improves an LLM's reasoning abilities using a synthetically trained Transformer-based reasoning module. TART trains this reasoning module in a task-agnostic manner using only synthetic logistic regression tasks and composes it with an arbitrary real-world pre-trained model without any additional training. With a single inference module, TART improves performance across different model families (GPT-Neo, Pythia, BLOOM), model sizes (100M - 6B), tasks (14 NLP binary classification tasks), and even across different modalities (audio and vision). Additionally, on the RAFT Benchmark, TART improves GPT-Neo (125M)'s performance such that it outperforms BLOOM (176B), and is within 4% of GPT-3 (175B). Our code and models are available at https://github.com/HazyResearch/TART .
Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes
Apr 20, 2023
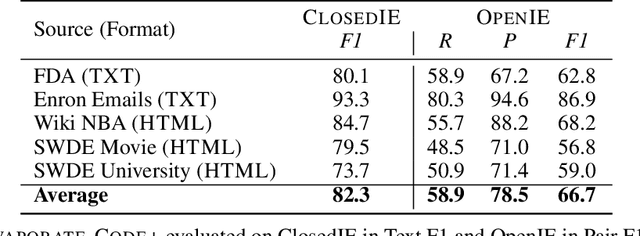

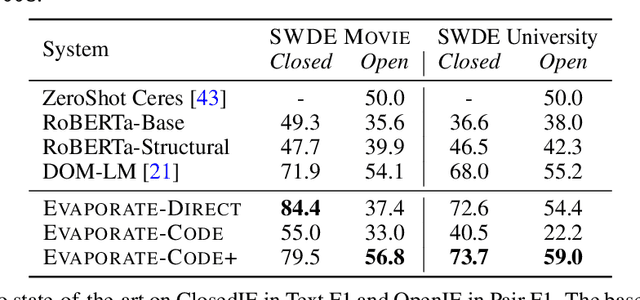
A long standing goal of the data management community is to develop general, automated systems that ingest semi-structured documents and output queryable tables without human effort or domain specific customization. Given the sheer variety of potential documents, state-of-the art systems make simplifying assumptions and use domain specific training. In this work, we ask whether we can maintain generality by using large language models (LLMs). LLMs, which are pretrained on broad data, can perform diverse downstream tasks simply conditioned on natural language task descriptions. We propose and evaluate EVAPORATE, a simple, prototype system powered by LLMs. We identify two fundamentally different strategies for implementing this system: prompt the LLM to directly extract values from documents or prompt the LLM to synthesize code that performs the extraction. Our evaluations show a cost-quality tradeoff between these two approaches. Code synthesis is cheap, but far less accurate than directly processing each document with the LLM. To improve quality while maintaining low cost, we propose an extended code synthesis implementation, EVAPORATE-CODE+, which achieves better quality than direct extraction. Our key insight is to generate many candidate functions and ensemble their extractions using weak supervision. EVAPORATE-CODE+ not only outperforms the state-of-the art systems, but does so using a sublinear pass over the documents with the LLM. This equates to a 110x reduction in the number of tokens the LLM needs to process, averaged across 16 real-world evaluation settings of 10k documents each.
Ask Me Anything: A simple strategy for prompting language models
Oct 06, 2022
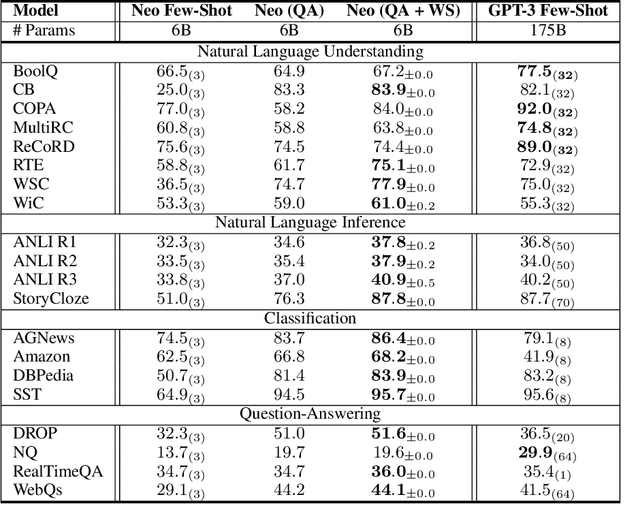

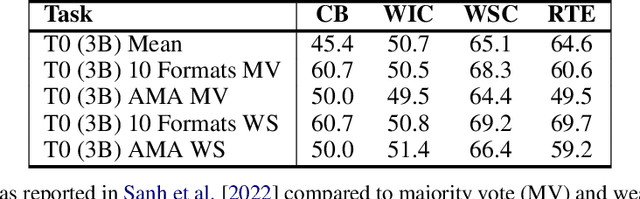
Large language models (LLMs) transfer well to new tasks out-of-the-box simply given a natural language prompt that demonstrates how to perform the task and no additional training. Prompting is a brittle process wherein small modifications to the prompt can cause large variations in the model predictions, and therefore significant effort is dedicated towards designing a painstakingly "perfect prompt" for a task. To mitigate the high degree of effort involved in prompt-design, we instead ask whether producing multiple effective, yet imperfect, prompts and aggregating them can lead to a high quality prompting strategy. Our observations motivate our proposed prompting method, ASK ME ANYTHING (AMA). We first develop an understanding of the effective prompt formats, finding that question-answering (QA) prompts, which encourage open-ended generation ("Who went to the park?") tend to outperform those that restrict the model outputs ("John went to the park. Output True or False."). Our approach recursively uses the LLM itself to transform task inputs to the effective QA format. We apply the collected prompts to obtain several noisy votes for the input's true label. We find that the prompts can have very different accuracies and complex dependencies and thus propose to use weak supervision, a procedure for combining the noisy predictions, to produce the final predictions for the inputs. We evaluate AMA across open-source model families (e.g., EleutherAI, BLOOM, OPT, and T0) and model sizes (125M-175B parameters), demonstrating an average performance lift of 10.2% over the few-shot baseline. This simple strategy enables the open-source GPT-J-6B model to match and exceed the performance of few-shot GPT3-175B on 15 of 20 popular benchmarks. Averaged across these tasks, the GPT-Neo-6B model outperforms few-shot GPT3-175B. We release our code here: https://github.com/HazyResearch/ama_prompting
Neural Generation Meets Real People: Building a Social, Informative Open-Domain Dialogue Agent
Jul 25, 2022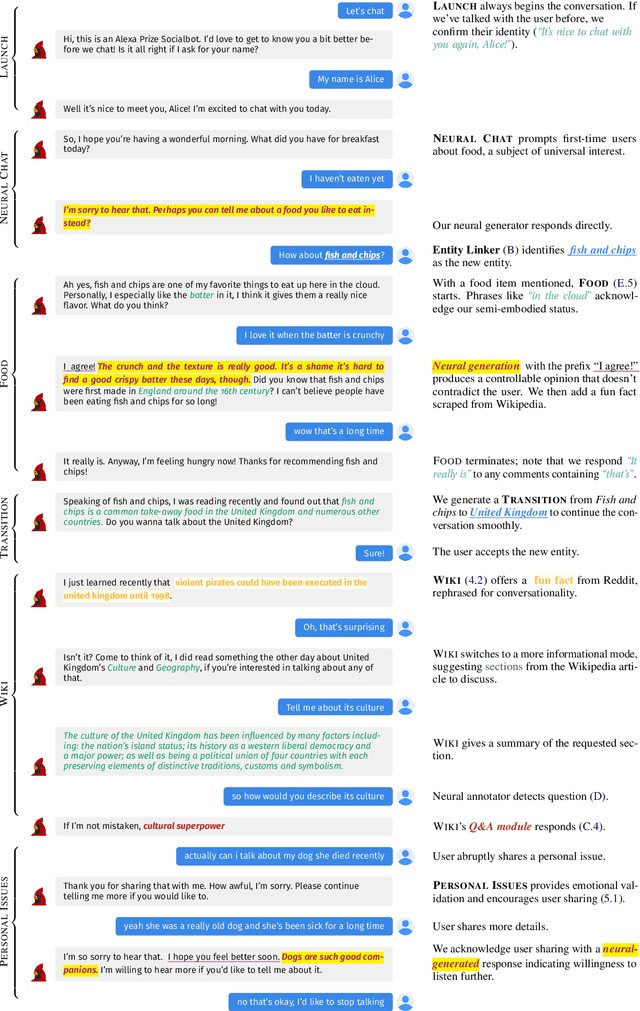


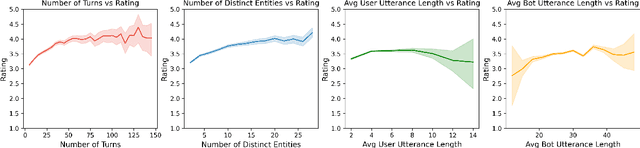
We present Chirpy Cardinal, an open-domain social chatbot. Aiming to be both informative and conversational, our bot chats with users in an authentic, emotionally intelligent way. By integrating controlled neural generation with scaffolded, hand-written dialogue, we let both the user and bot take turns driving the conversation, producing an engaging and socially fluent experience. Deployed in the fourth iteration of the Alexa Prize Socialbot Grand Challenge, Chirpy Cardinal handled thousands of conversations per day, placing second out of nine bots with an average user rating of 3.58/5.
Can Foundation Models Wrangle Your Data?
May 20, 2022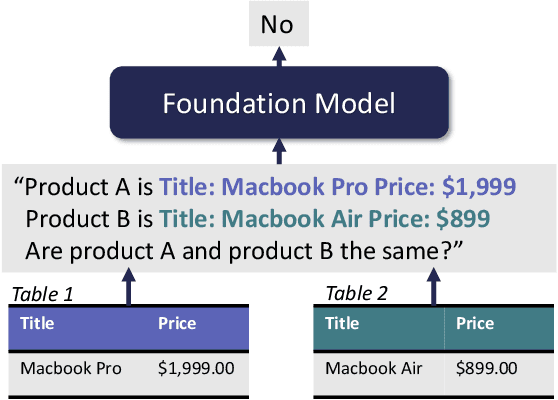
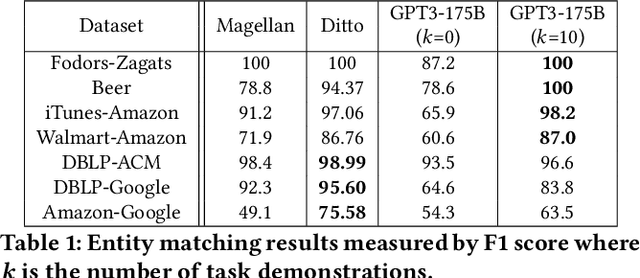
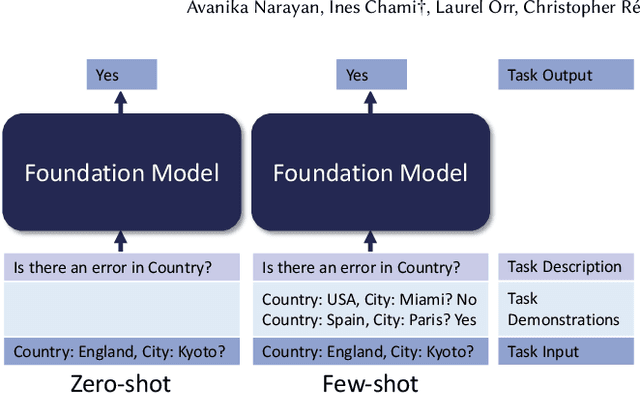
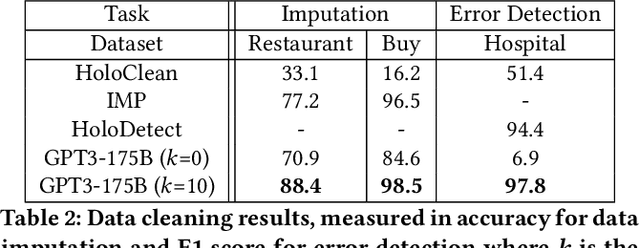
Foundation Models (FMs) are models trained on large corpora of data that, at very large scale, can generalize to new tasks without any task-specific finetuning. As these models continue to grow in size, innovations continue to push the boundaries of what these models can do on language and image tasks. This paper aims to understand an underexplored area of FMs: classical data tasks like cleaning and integration. As a proof-of-concept, we cast three data cleaning and integration tasks as prompting tasks and evaluate the performance of FMs on these tasks. We find that large FMs generalize and achieve SoTA performance on data cleaning and integration tasks, even though they are not trained for these data tasks. We identify specific research challenges and opportunities that these models present, including challenges with private and temporal data, and opportunities to make data driven systems more accessible to non-experts. We make our code and experiments publicly available at: https://github.com/HazyResearch/fm_data_tasks.