 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenDB: The Next Generation of Query Processing -- Synthesized, Not Engineered
Mar 02, 2026Traditional query processing relies on engines that are carefully optimized and engineered by many experts. However, new techniques and user requirements evolve rapidly, and existing systems often cannot keep pace. At the same time, these systems are difficult to extend due to their internal complexity, and developing new systems requires substantial engineering effort and cost. In this paper, we argue that recent advances in Large Language Models (LLMs) are starting to shape the next generation of query processing systems. We propose using LLMs to synthesize execution code for each incoming query, instead of continuously building, extending, and maintaining complex query processing engines. As a proof of concept, we present GenDB, an LLM-powered agentic system that generates instance-optimized and customized query execution code tailored to specific data, workloads, and hardware resources. We implemented an early prototype of GenDB that uses Claude Code Agent as the underlying component in the multi-agent system, and we evaluate it on OLAP workloads. We use queries from the well-known TPC-H benchmark and also construct a new benchmark designed to reduce potential data leakage from LLM training data. We compare GenDB with state-of-the-art query engines, including DuckDB, Umbra, MonetDB, ClickHouse, and PostgreSQL. GenDB achieves significantly better performance than these systems. Finally, we discuss the current limitations of GenDB and outline future extensions and related research challenges.
SQLBarber: A System Leveraging Large Language Models to Generate Customized and Realistic SQL Workloads
Jul 08, 2025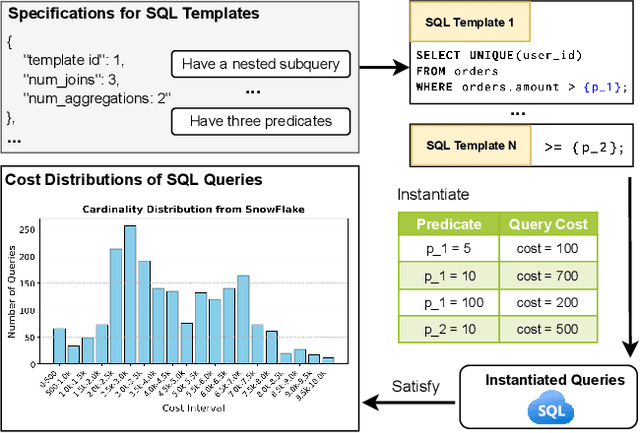

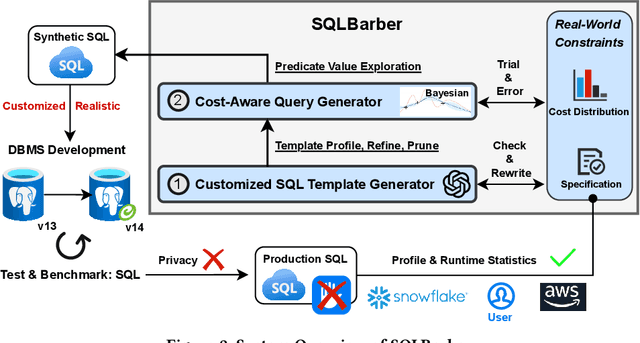

Database research and development often require a large number of SQL queries for benchmarking purposes. However, acquiring real-world SQL queries is challenging due to privacy concerns, and existing SQL generation methods are limited in customization and in satisfying realistic constraints. To address this issue, we present SQLBarber, a system based on Large Language Models (LLMs) to generate customized and realistic SQL workloads. SQLBarber (i) eliminates the need for users to manually craft SQL templates in advance, while providing the flexibility to accept natural language specifications to constrain SQL templates, (ii) scales efficiently to generate large volumes of queries matching any user-defined cost distribution (e.g., cardinality and execution plan cost), and (iii) uses execution statistics from Amazon Redshift and Snowflake to derive SQL template specifications and query cost distributions that reflect real-world query characteristics. SQLBarber introduces (i) a declarative interface for users to effortlessly generate customized SQL templates, (ii) an LLM-powered pipeline augmented with a self-correction module that profiles, refines, and prunes SQL templates based on query costs, and (iii) a Bayesian Optimizer to efficiently explore different predicate values and identify a set of queries that satisfy the target cost distribution. We construct and open-source ten benchmarks of varying difficulty levels and target query cost distributions based on real-world statistics from Snowflake and Amazon Redshift. Extensive experiments on these benchmarks show that SQLBarber is the only system that can generate customized SQL templates. It reduces query generation time by one to three orders of magnitude, and significantly improves alignment with the target cost distribution, compared with existing methods.
SMART: Automatically Scaling Down Language Models with Accuracy Guarantees for Reduced Processing Fees
Mar 11, 2024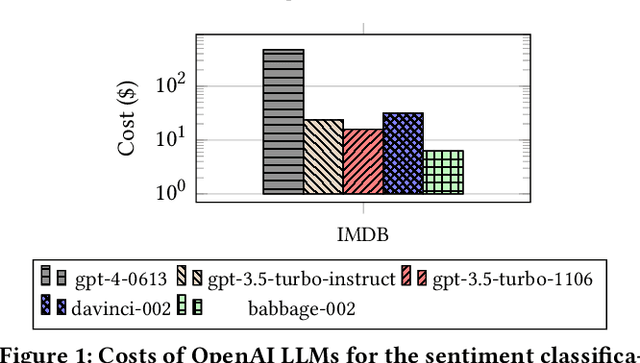


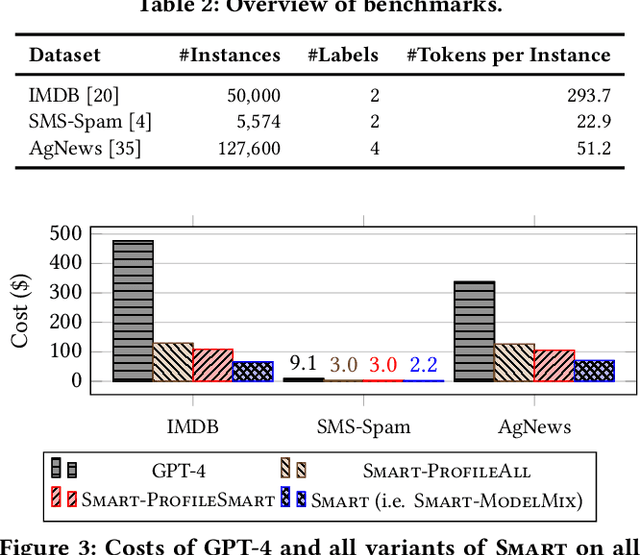
The advancement of Large Language Models (LLMs) has significantly boosted performance in natural language processing (NLP) tasks. However, the deployment of high-performance LLMs incurs substantial costs, primarily due to the increased number of parameters aimed at enhancing model performance. This has made the use of state-of-the-art LLMs more expensive for end-users. AI service providers, such as OpenAI and Anthropic, often offer multiple versions of LLMs with varying prices and performance. However, end-users still face challenges in choosing the appropriate LLM for their tasks that balance result quality with cost. We introduce SMART, Scaling Models Adaptively for Reduced Token Fees, a novel LLM framework designed to minimize the inference costs of NLP tasks while ensuring sufficient result quality. It enables users to specify an accuracy constraint in terms of the equivalence of outputs to those of the most powerful LLM. SMART then generates results that deviate from the outputs of this LLM only with a probability below a user-defined threshold. SMART employs a profiling phase that evaluates the performance of multiple LLMs to identify those that meet the user-defined accuracy level. SMART optimizes the tradeoff between profiling overheads and the anticipated cost savings resulting from profiling. Moreover, our approach significantly reduces inference costs by strategically leveraging a mix of LLMs. Our experiments on three real-world datasets show that, based on OpenAI models, SMART achieves significant cost savings, up to 25.6x in comparison to GPT-4.
JoinGym: An Efficient Query Optimization Environment for Reinforcement Learning
Jul 21, 2023In this paper, we present \textsc{JoinGym}, an efficient and lightweight query optimization environment for reinforcement learning (RL). Join order selection (JOS) is a classic NP-hard combinatorial optimization problem from database query optimization and can serve as a practical testbed for the generalization capabilities of RL algorithms. We describe how to formulate each of the left-deep and bushy variants of the JOS problem as a Markov Decision Process (MDP), and we provide an implementation adhering to the standard Gymnasium API. We highlight that our implementation \textsc{JoinGym} is completely based on offline traces of all possible joins, which enables RL practitioners to easily and quickly test their methods on a realistic data management problem without needing to setup any systems. Moreover, we also provide all possible join traces on $3300$ novel SQL queries generated from the IMDB dataset. Upon benchmarking popular RL algorithms, we find that at least one method can obtain near-optimal performance on train-set queries but their performance degrades by several orders of magnitude on test-set queries. This gap motivates further research for RL algorithms that generalize well in multi-task combinatorial optimization problems.
Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes
Apr 20, 2023
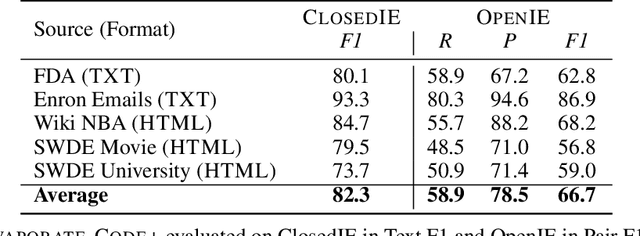

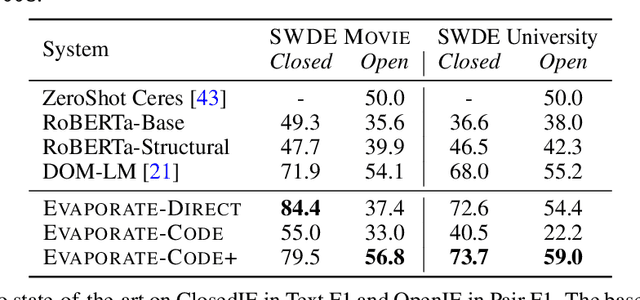
A long standing goal of the data management community is to develop general, automated systems that ingest semi-structured documents and output queryable tables without human effort or domain specific customization. Given the sheer variety of potential documents, state-of-the art systems make simplifying assumptions and use domain specific training. In this work, we ask whether we can maintain generality by using large language models (LLMs). LLMs, which are pretrained on broad data, can perform diverse downstream tasks simply conditioned on natural language task descriptions. We propose and evaluate EVAPORATE, a simple, prototype system powered by LLMs. We identify two fundamentally different strategies for implementing this system: prompt the LLM to directly extract values from documents or prompt the LLM to synthesize code that performs the extraction. Our evaluations show a cost-quality tradeoff between these two approaches. Code synthesis is cheap, but far less accurate than directly processing each document with the LLM. To improve quality while maintaining low cost, we propose an extended code synthesis implementation, EVAPORATE-CODE+, which achieves better quality than direct extraction. Our key insight is to generate many candidate functions and ensemble their extractions using weak supervision. EVAPORATE-CODE+ not only outperforms the state-of-the art systems, but does so using a sublinear pass over the documents with the LLM. This equates to a 110x reduction in the number of tokens the LLM needs to process, averaged across 16 real-world evaluation settings of 10k documents each.
CodexDB: Generating Code for Processing SQL Queries using GPT-3 Codex
Apr 19, 2022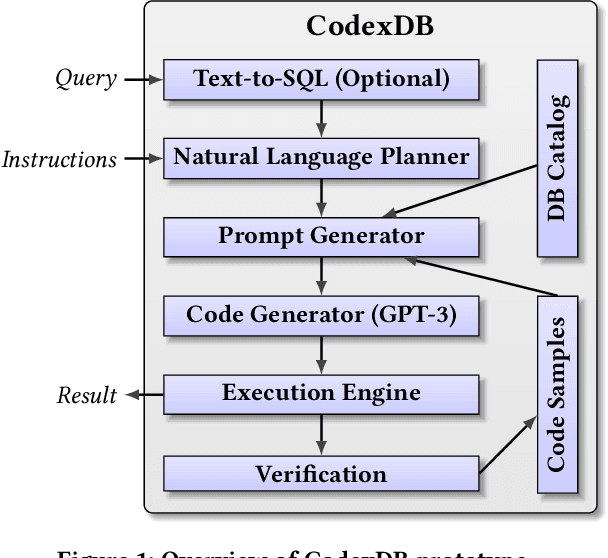



CodexDB is an SQL processing engine whose internals can be customized via natural language instructions. CodexDB is based on OpenAI's GPT-3 Codex model which translates text into code. It is a framework on top of GPT-3 Codex that decomposes complex SQL queries into a series of simple processing steps, described in natural language. Processing steps are enriched with user-provided instructions and descriptions of database properties. Codex translates the resulting text into query processing code. An early prototype of CodexDB is able to generate correct code for a majority of queries of the WikiSQL benchmark and can be customized in various ways.
DB-BERT: a Database Tuning Tool that "Reads the Manual"
Dec 21, 2021
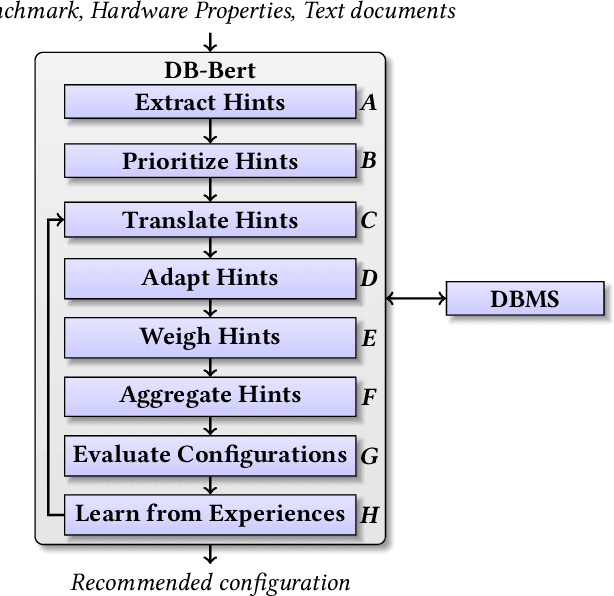
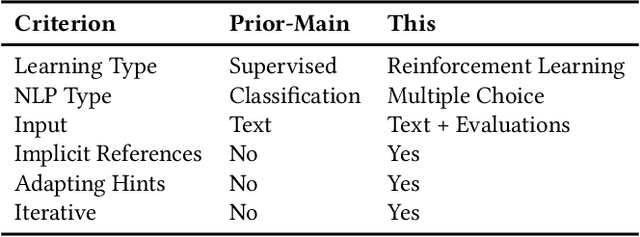
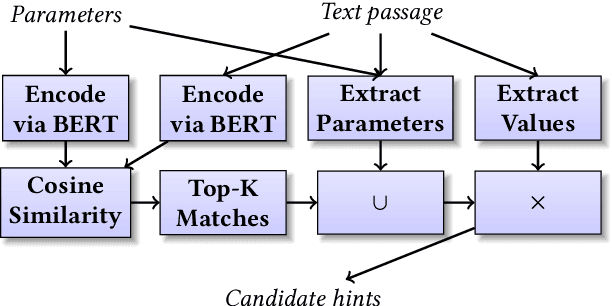
DB-BERT is a database tuning tool that exploits information gained via natural language analysis of manuals and other relevant text documents. It uses text to identify database system parameters to tune as well as recommended parameter values. DB-BERT applies large, pre-trained language models (specifically, the BERT model) for text analysis. During an initial training phase, it fine-tunes model weights in order to translate natural language hints into recommended settings. At run time, DB-BERT learns to aggregate, adapt, and prioritize hints to achieve optimal performance for a specific database system and benchmark. Both phases are iterative and use reinforcement learning to guide the selection of tuning settings to evaluate (penalizing settings that the database system rejects while rewarding settings that improve performance). In our experiments, we leverage hundreds of text documents about database tuning as input for DB-BERT. We compare DB-BERT against various baselines, considering different benchmarks (TPC-C and TPC-H), metrics (throughput and run time), as well as database systems (Postgres and MySQL). In all cases, DB-BERT finds the best parameter settings among all compared methods. The code of DB-BERT is available online at https://itrummer.github.io/dbbert/.
Procrastinated Tree Search: Black-box Optimization with Delayed, Noisy, and Multi-fidelity Feedback
Oct 14, 2021
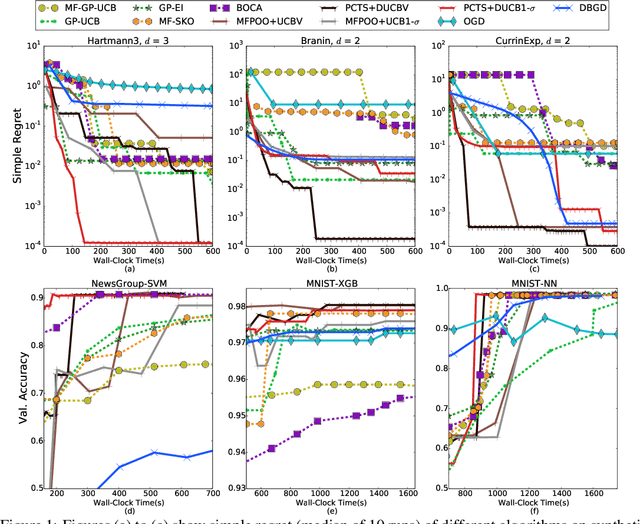


In black-box optimization problems, we aim to maximize an unknown objective function, where the function is only accessible through feedbacks of an evaluation or simulation oracle. In real-life, the feedbacks of such oracles are often noisy and available after some unknown delay that may depend on the computation time of the oracle. Additionally, if the exact evaluations are expensive but coarse approximations are available at a lower cost, the feedbacks can have multi-fidelity. In order to address this problem, we propose a generic extension of hierarchical optimistic tree search (HOO), called ProCrastinated Tree Search (PCTS), that flexibly accommodates a delay and noise-tolerant bandit algorithm. We provide a generic proof technique to quantify regret of PCTS under delayed, noisy, and multi-fidelity feedbacks. Specifically, we derive regret bounds of PCTS enabled with delayed-UCB1 (DUCB1) and delayed-UCB-V (DUCBV) algorithms. Given a horizon $T$, PCTS retains the regret bound of non-delayed HOO for expected delay of $O(\log T)$ and worsens by $O(T^{\frac{1-\alpha}{d+2}})$ for expected delays of $O(T^{1-\alpha})$ for $\alpha \in (0,1]$. We experimentally validate on multiple synthetic functions and hyperparameter tuning problems that PCTS outperforms the state-of-the-art black-box optimization methods for feedbacks with different noise levels, delays, and fidelity.
Can Deep Neural Networks Predict Data Correlations from Column Names?
Jul 09, 2021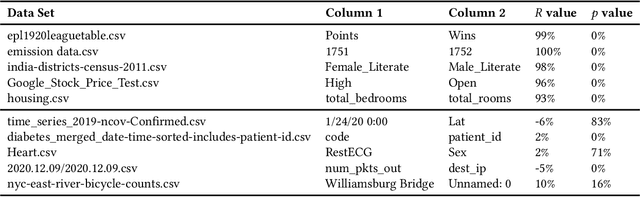
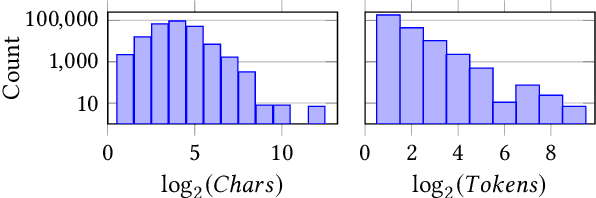

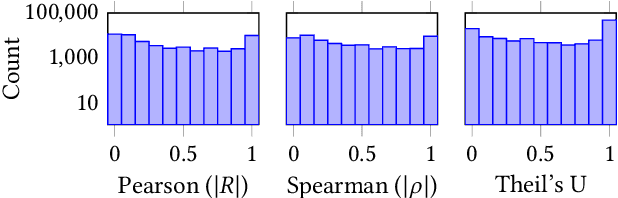
For humans, it is often possible to predict data correlations from column names. We conduct experiments to find out whether deep neural networks can learn to do the same. If so, e.g., it would open up the possibility of tuning tools that use NLP analysis on schema elements to prioritize their efforts for correlation detection. We analyze correlations for around 120,000 column pairs, taken from around 4,000 data sets. We try to predict correlations, based on column names alone. For predictions, we exploit pre-trained language models, based on the recently proposed Transformer architecture. We consider different types of correlations, multiple prediction methods, and various prediction scenarios. We study the impact of factors such as column name length or the amount of training data on prediction accuracy. Altogether, we find that deep neural networks can predict correlations with a relatively high accuracy in many scenarios (e.g., with an accuracy of 95% for long column names).