 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Geometric Dual Compression: Training-Free Visual Token Reduction for Ultra-High-Resolution Remote Sensing Understanding
Apr 13, 2026Multimodal Large Language Models (MLLMs) have demonstrated immense potential in Earth observation. However, the massive visual tokens generated when processing Ultra-High-Resolution (UHR) imagery introduce prohibitive computational overhead, severely bottlenecking their inference efficiency. Existing visual token compression methods predominantly adopt static and uniform compression strategies, neglecting the inherent "Semantic-Geometric Duality" in remote sensing interpretation tasks. Specifically, object semantic tasks focus on the abstract semantics of objects and benefit from aggressive background pruning, whereas scene geometric tasks critically rely on the integrity of spatial topology. To address this challenge, we propose DualComp, a task-adaptive dual-stream token compression framework. Dynamically guided by a lightweight pre-trained router, DualComp decouples feature processing into two dedicated pathways. In the object semantic stream, the Spatially-Contiguous Semantic Aggregator (SCSA) utilizes size-adaptive clustering to aggregates redundant background while protecting small object. In the scene geometric stream, the Instruction-Guided Structure Recoverer (IGSR) introduces a greedy path-tracing topology completion mechanism to reconstruct spatial skeletons. Experiments on the UHR remote sensing benchmark XLRS-Bench demonstrate that DualComp accomplishes high-fidelity remote sensing interpretation at an exceptionally low computational cost, achieving simultaneous improvements in both efficiency and accuracy.
SVSR: A Self-Verification and Self-Rectification Paradigm for Multimodal Reasoning
Apr 11, 2026Current multimodal models often suffer from shallow reasoning, leading to errors caused by incomplete or inconsistent thought processes. To address this limitation, we propose Self-Verification and Self-Rectification (SVSR), a unified framework that explicitly integrates self-verification and self-rectification into the model's reasoning pipeline, substantially improving robustness and reliability in complex visual understanding and multimodal reasoning tasks. SVSR is built on a novel three-stage training paradigm. First, we construct a high-quality unified preference dataset by refining reasoning traces from pre-trained vision-language models, incorporating both forward and backward reasoning to embed self-reflective signals. Second, we perform cold-start supervised fine-tuning on this dataset to learn structured, multi-step reasoning behaviors. Third, we apply a Semi-online Direct Preference Optimization (Semi-online DPO) process, continuously augmenting the training corpus with high-quality, model-generated reasoning traces filtered by a powerful teacher VLM. This pipeline enables the model to learn, elicit, and refine its ability to self-verify and self-rectify. Extensive experiments across diverse benchmarks demonstrate that SVSR improves reasoning accuracy and enables stronger generalization to unseen tasks and question types. Notably, once trained with explicit self-reflective reasoning, the model also exhibits improved implicit reasoning ability, outperforming strong baselines even when no explicit reasoning traces are provided. These results highlight the potential of SVSR for building more dependable, introspective, and cognitively aligned multimodal systems.
M3D-BFS: a Multi-stage Dynamic Fusion Strategy for Sample-Adaptive Multi-Modal Brain Network Analysis
Apr 02, 2026Multi-modal fusion is of great significance in neuroscience which integrates information from different modalities and can achieve better performance than uni-modal methods in downstream tasks. Current multi-modal fusion methods in brain networks, which mainly focus on structural connectivity (SC) and functional connectivity (FC) modalities, are static in nature. They feed different samples into the same model with identical computation, ignoring inherent difference between input samples. This lack of sample adaptation hinders model's further performance. To this end, we innovatively propose a multi-stage dynamic fusion strategy (M3D-BFS) for sample-adaptive multi-modal brain network analysis. Unlike other static fusion methods, we design different mixture-of-experts (MoEs) for uni- and multi-modal representations where modules can adaptively change as input sample changes during inference. To alleviate issue of MoE where training of experts may be collapsed, we divide our method into 3 stages. We first train uni-modal encoders respectively, then pretrain single experts of MoEs before finally finetuning the whole model. A multi-modal disentanglement loss is designed to enhance the final representations. To the best of our knowledge, this is the first work for dynamic fusion for multi-modal brain network analysis. Extensive experiments on different real-world datasets demonstrates the superiority of M3D-BFS.
Text Before Vision: Staged Knowledge Injection Matters for Agentic RLVR in Ultra-High-Resolution Remote Sensing Understanding
Feb 15, 2026Multimodal reasoning for ultra-high-resolution (UHR) remote sensing (RS) is usually bottlenecked by visual evidence acquisition: the model necessitates localizing tiny task-relevant regions in massive pixel spaces. While Agentic Reinforcement Learning with Verifiable Rewards (RLVR) using zoom-in tools offers a path forward, we find that standard reinforcement learning struggles to navigate these vast visual spaces without structured domain priors. In this paper, we investigate the interplay between post-training paradigms: comparing Cold-start Supervised Fine-Tuning (SFT), RLVR, and Agentic RLVR on the UHR RS benchmark.Our controlled studies yield a counter-intuitive finding: high-quality Earth-science text-only QA is a primary driver of UHR visual reasoning gains. Despite lacking images, domain-specific text injects the concepts, mechanistic explanations, and decision rules necessary to guide visual evidence retrieval.Based on this, we propose a staged knowledge injection recipe: (1) cold-starting with scalable, knowledge-graph-verified Earth-science text QA to instill reasoning structures;and (2) "pre-warming" on the same hard UHR image-text examples during SFT to stabilize and amplify subsequent tool-based RL. This approach achieves a 60.40% Pass@1 on XLRS-Bench, significantly outperforming larger general purpose models (e.g., GPT-5.2, Gemini 3.0 Pro, Intern-S1) and establishing a new state-of-the-art.
GeoEyes: On-Demand Visual Focusing for Evidence-Grounded Understanding of Ultra-High-Resolution Remote Sensing Imagery
Feb 15, 2026The "thinking-with-images" paradigm enables multimodal large language models (MLLMs) to actively explore visual scenes via zoom-in tools. This is essential for ultra-high-resolution (UHR) remote sensing VQA, where task-relevant cues are sparse and tiny. However, we observe a consistent failure mode in existing zoom-enabled MLLMs: Tool Usage Homogenization, where tool calls collapse into task-agnostic patterns, limiting effective evidence acquisition. To address this, we propose GeoEyes, a staged training framework consisting of (1) a cold-start SFT dataset, UHR Chain-of-Zoom (UHR-CoZ), which covers diverse zooming regimes, and (2) an agentic reinforcement learning method, AdaZoom-GRPO, that explicitly rewards evidence gain and answer improvement during zoom interactions. The resulting model learns on-demand zooming with proper stopping behavior and achieves substantial improvements on UHR remote sensing benchmarks, with 54.23% accuracy on XLRS-Bench.
GeoLLaVA-8K: Scaling Remote-Sensing Multimodal Large Language Models to 8K Resolution
May 27, 2025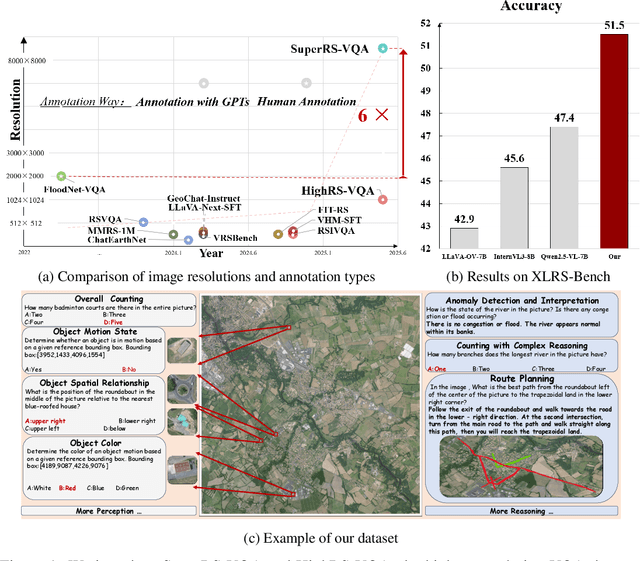
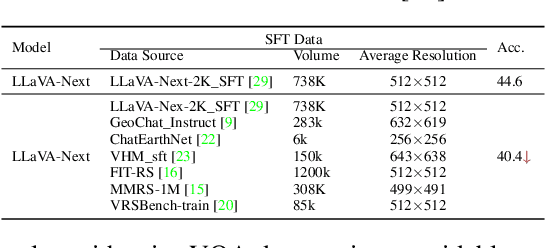
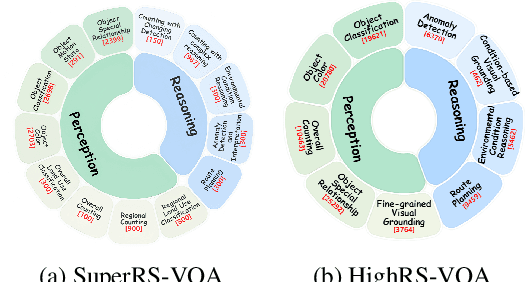
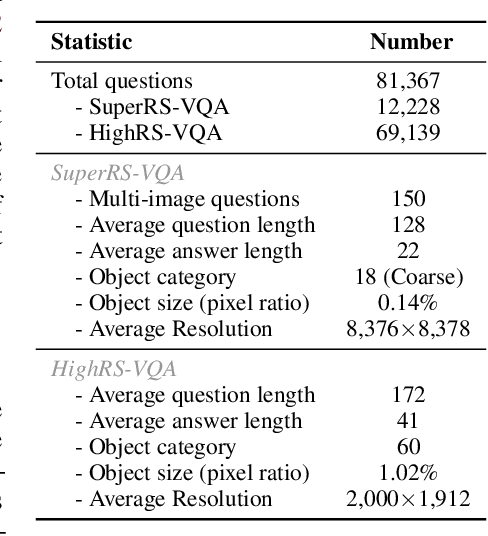
Ultra-high-resolution (UHR) remote sensing (RS) imagery offers valuable data for Earth observation but pose challenges for existing multimodal foundation models due to two key bottlenecks: (1) limited availability of UHR training data, and (2) token explosion caused by the large image size. To address data scarcity, we introduce SuperRS-VQA (avg. 8,376$\times$8,376) and HighRS-VQA (avg. 2,000$\times$1,912), the highest-resolution vision-language datasets in RS to date, covering 22 real-world dialogue tasks. To mitigate token explosion, our pilot studies reveal significant redundancy in RS images: crucial information is concentrated in a small subset of object-centric tokens, while pruning background tokens (e.g., ocean or forest) can even improve performance. Motivated by these findings, we propose two strategies: Background Token Pruning and Anchored Token Selection, to reduce the memory footprint while preserving key semantics.Integrating these techniques, we introduce GeoLLaVA-8K, the first RS-focused multimodal large language model capable of handling inputs up to 8K$\times$8K resolution, built on the LLaVA framework. Trained on SuperRS-VQA and HighRS-VQA, GeoLLaVA-8K sets a new state-of-the-art on the XLRS-Bench.
SplitReason: Learning To Offload Reasoning
Apr 23, 2025Reasoning in large language models (LLMs) tends to produce substantially longer token generation sequences than simpler language modeling tasks. This extended generation length reflects the multi-step, compositional nature of reasoning and is often correlated with higher solution accuracy. From an efficiency perspective, longer token generation exacerbates the inherently sequential and memory-bound decoding phase of LLMs. However, not all parts of this expensive reasoning process are equally difficult to generate. We leverage this observation by offloading only the most challenging parts of the reasoning process to a larger, more capable model, while performing most of the generation with a smaller, more efficient model; furthermore, we teach the smaller model to identify these difficult segments and independently trigger offloading when needed. To enable this behavior, we annotate difficult segments across 18k reasoning traces from the OpenR1-Math-220k chain-of-thought (CoT) dataset. We then apply supervised fine-tuning (SFT) and reinforcement learning fine-tuning (RLFT) to a 1.5B-parameter reasoning model, training it to learn to offload the most challenging parts of its own reasoning process to a larger model. This approach improves AIME24 reasoning accuracy by 24% and 28.3% while offloading 1.35% and 5% of the generated tokens respectively. We open-source our SplitReason model, data, code and logs.
Throughput-Optimal Scheduling Algorithms for LLM Inference and AI Agents
Apr 10, 2025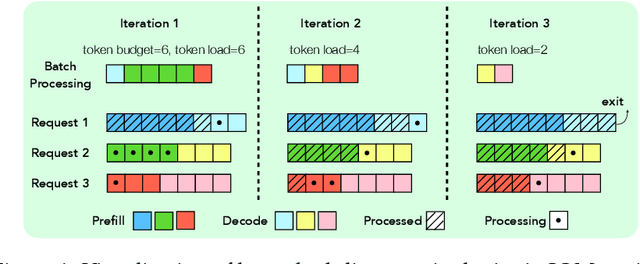
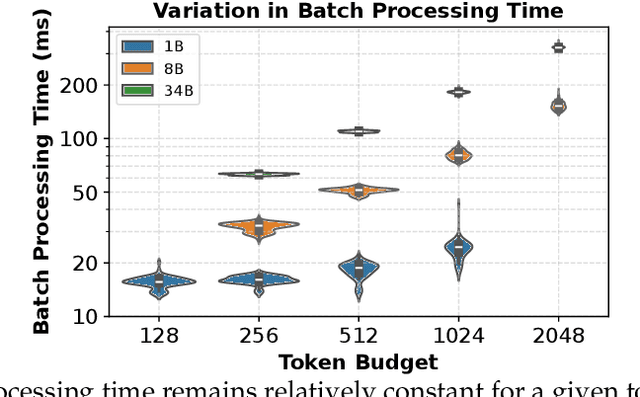
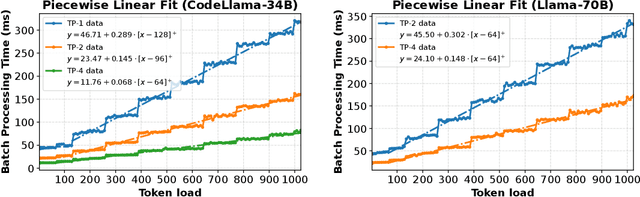
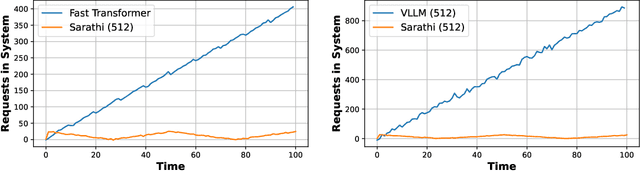
As demand for Large Language Models (LLMs) and AI agents rapidly grows, optimizing systems for efficient LLM inference becomes critical. While significant efforts have targeted system-level engineering, little is explored through a mathematical modeling and queuing perspective. In this paper, we aim to develop the queuing fundamentals for LLM inference, bridging the gap between queuing and LLM system communities. In particular, we study the throughput aspect in LLM inference systems. We prove that a large class of 'work-conserving' scheduling algorithms can achieve maximum throughput for both individual requests and AI agent workloads, highlighting 'work-conserving' as a key design principle in practice. Evaluations of real-world systems show that Orca and Sarathi-serve are throughput-optimal, reassuring practitioners, while FastTransformer and vanilla vLLM are not maximally stable and should be used with caution. Our results highlight the substantial benefits queuing community can offer in improving LLM inference systems and call for more interdisciplinary developments.
JoinGym: An Efficient Query Optimization Environment for Reinforcement Learning
Jul 21, 2023In this paper, we present \textsc{JoinGym}, an efficient and lightweight query optimization environment for reinforcement learning (RL). Join order selection (JOS) is a classic NP-hard combinatorial optimization problem from database query optimization and can serve as a practical testbed for the generalization capabilities of RL algorithms. We describe how to formulate each of the left-deep and bushy variants of the JOS problem as a Markov Decision Process (MDP), and we provide an implementation adhering to the standard Gymnasium API. We highlight that our implementation \textsc{JoinGym} is completely based on offline traces of all possible joins, which enables RL practitioners to easily and quickly test their methods on a realistic data management problem without needing to setup any systems. Moreover, we also provide all possible join traces on $3300$ novel SQL queries generated from the IMDB dataset. Upon benchmarking popular RL algorithms, we find that at least one method can obtain near-optimal performance on train-set queries but their performance degrades by several orders of magnitude on test-set queries. This gap motivates further research for RL algorithms that generalize well in multi-task combinatorial optimization problems.
Efficient Planning in a Compact Latent Action Space
Aug 25, 2022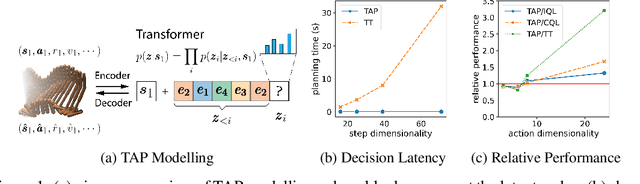
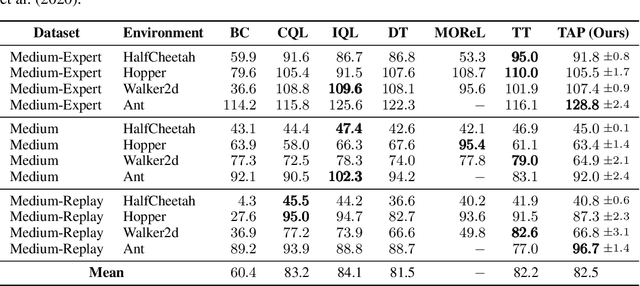
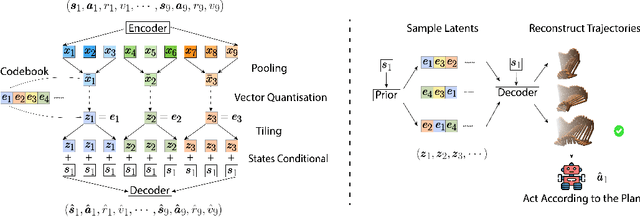
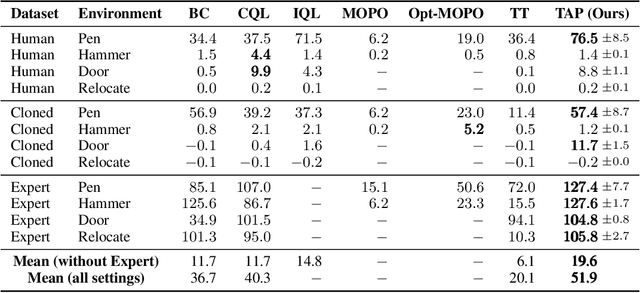
While planning-based sequence modelling methods have shown great potential in continuous control, scaling them to high-dimensional state-action sequences remains an open challenge due to the high computational complexity and innate difficulty of planning in high-dimensional spaces. We propose the Trajectory Autoencoding Planner (TAP), a planning-based sequence modelling RL method that scales to high state-action dimensionalities. Using a state-conditional Vector-Quantized Variational Autoencoder (VQ-VAE), TAP models the conditional distribution of the trajectories given the current state. When deployed as an RL agent, TAP avoids planning step-by-step in a high-dimensional continuous action space but instead looks for the optimal latent code sequences by beam search. Unlike $O(D^3)$ complexity of Trajectory Transformer, TAP enjoys constant $O(C)$ planning computational complexity regarding state-action dimensionality $D$. Our empirical evaluation also shows the increasingly strong performance of TAP with the growing dimensionality. For Adroit robotic hand manipulation tasks with high state and action dimensionality, TAP surpasses existing model-based methods, including TT, with a large margin and also beats strong model-free actor-critic baselines.