 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThroughput-Optimal Scheduling Algorithms for LLM Inference and AI Agents
Paper and Code
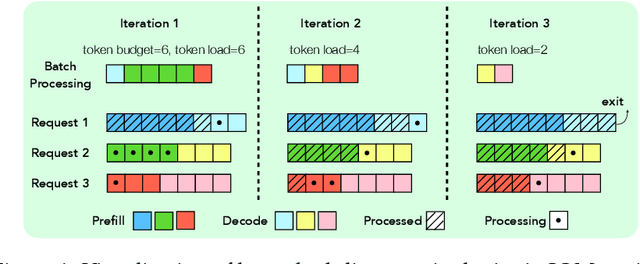
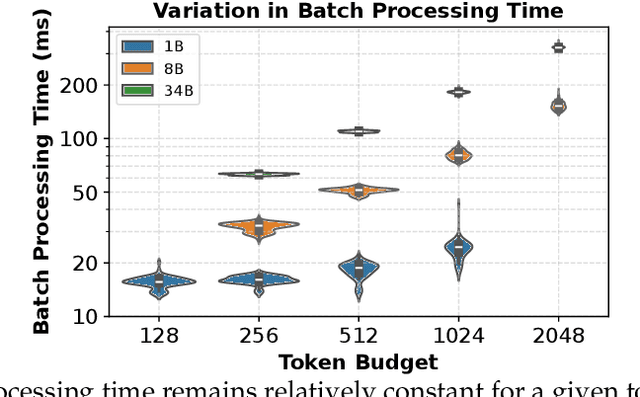
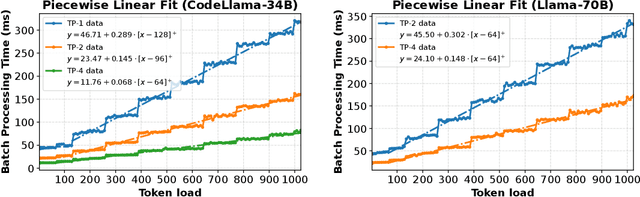
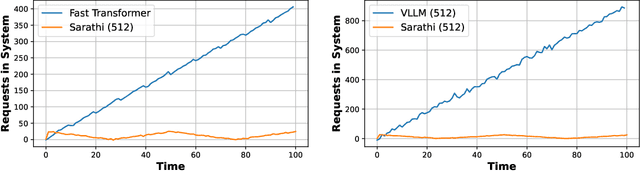
As demand for Large Language Models (LLMs) and AI agents rapidly grows, optimizing systems for efficient LLM inference becomes critical. While significant efforts have targeted system-level engineering, little is explored through a mathematical modeling and queuing perspective. In this paper, we aim to develop the queuing fundamentals for LLM inference, bridging the gap between queuing and LLM system communities. In particular, we study the throughput aspect in LLM inference systems. We prove that a large class of 'work-conserving' scheduling algorithms can achieve maximum throughput for both individual requests and AI agent workloads, highlighting 'work-conserving' as a key design principle in practice. Evaluations of real-world systems show that Orca and Sarathi-serve are throughput-optimal, reassuring practitioners, while FastTransformer and vanilla vLLM are not maximally stable and should be used with caution. Our results highlight the substantial benefits queuing community can offer in improving LLM inference systems and call for more interdisciplinary developments.