 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompute Where it Counts: Self Optimizing Language Models
May 11, 2026Efficient LLM inference research has largely focused on reducing the cost of each decoding step (e.g., using quantization, pruning, or sparse attention), typically applying a uniform computation budget to every generated token. In practice, token difficulty varies widely, so static compression can over-compute on easy steps and under-compute on hard ones. We study dynamic budget allocation for autoregressive decoding: learning how much computation to spend per token from within a single model. Self-Optimizing Language Models (SOL) pair a frozen LLM with a lightweight policy network that reads the LLM hidden state and selects a discrete efficiency action at each decode step. Actions can jointly control (i) token-level attention sparsity, (ii) structured activation pruning in the MLP, and (iii) activation quantization bit-width, while leaving the base model weights unchanged. We train the policy with group-relative policy optimization on teacher-forced episodes: the token sequence is fixed, while we sample multiple compute schedules (i.e., "counterfactual" schedules that vary only the efficiency actions for the same token path) and compare their likelihoods under the same supervision. Our reward trades off language-model quality against soft penalties that encourage episode-average budget usage to match a requested target. Across model variants and compute regimes, SOL improves quality at matched budget over static allocation and strong random schedule search, offering a complementary axis for inference-efficiency optimization. SOL discovers a better quality-efficiency pareto-front across all our experiments and improves MMLU accuracy by up to 7.3% over uniform budget allocation strategies.
Regression Language Models for Code
Sep 30, 2025We study code-to-metric regression: predicting numeric outcomes of code executions, a challenging task due to the open-ended nature of programming languages. While prior methods have resorted to heavy and domain-specific feature engineering, we show that a single unified Regression Language Model (RLM) can simultaneously predict directly from text, (i) the memory footprint of code across multiple high-level languages such as Python and C++, (ii) the latency of Triton GPU kernels, and (iii) the accuracy and speed of trained neural networks represented in ONNX. In particular, a relatively small 300M parameter RLM initialized from T5Gemma, obtains > 0.9 Spearman-rank on competitive programming submissions from APPS, and a single unified model achieves > 0.5 average Spearman-rank across 17 separate languages from CodeNet. Furthermore, the RLM can obtain the highest average Kendall-Tau of 0.46 on five classic NAS design spaces previously dominated by graph neural networks, and simultaneously predict architecture latencies on numerous hardware platforms.
Accelerating Diffusion Language Model Inference via Efficient KV Caching and Guided Diffusion
May 27, 2025



Diffusion language models offer parallel token generation and inherent bidirectionality, promising more efficient and powerful sequence modeling compared to autoregressive approaches. However, state-of-the-art diffusion models (e.g., Dream 7B, LLaDA 8B) suffer from slow inference. While they match the quality of similarly sized Autoregressive (AR) Models (e.g., Qwen2.5 7B, Llama3 8B), their iterative denoising requires multiple full-sequence forward passes, resulting in high computational costs and latency, particularly for long input prompts and long-context scenarios. Furthermore, parallel token generation introduces token incoherence problems, and current sampling heuristics suffer from significant quality drops with decreasing denoising steps. We address these limitations with two training-free techniques. First, we propose FreeCache, a Key-Value (KV) approximation caching technique that reuses stable KV projections across denoising steps, effectively reducing the computational cost of DLM inference. Second, we introduce Guided Diffusion, a training-free method that uses a lightweight pretrained autoregressive model to supervise token unmasking, dramatically reducing the total number of denoising iterations without sacrificing quality. We conduct extensive evaluations on open-source reasoning benchmarks, and our combined methods deliver up to a 34x end-to-end speedup without compromising accuracy. For the first time, diffusion language models achieve a comparable and even faster latency as the widely adopted autoregressive models. Our work successfully paved the way for scaling up the diffusion language model to a broader scope of applications across different domains.
SplitReason: Learning To Offload Reasoning
Apr 23, 2025Reasoning in large language models (LLMs) tends to produce substantially longer token generation sequences than simpler language modeling tasks. This extended generation length reflects the multi-step, compositional nature of reasoning and is often correlated with higher solution accuracy. From an efficiency perspective, longer token generation exacerbates the inherently sequential and memory-bound decoding phase of LLMs. However, not all parts of this expensive reasoning process are equally difficult to generate. We leverage this observation by offloading only the most challenging parts of the reasoning process to a larger, more capable model, while performing most of the generation with a smaller, more efficient model; furthermore, we teach the smaller model to identify these difficult segments and independently trigger offloading when needed. To enable this behavior, we annotate difficult segments across 18k reasoning traces from the OpenR1-Math-220k chain-of-thought (CoT) dataset. We then apply supervised fine-tuning (SFT) and reinforcement learning fine-tuning (RLFT) to a 1.5B-parameter reasoning model, training it to learn to offload the most challenging parts of its own reasoning process to a larger model. This approach improves AIME24 reasoning accuracy by 24% and 28.3% while offloading 1.35% and 5% of the generated tokens respectively. We open-source our SplitReason model, data, code and logs.
xKV: Cross-Layer SVD for KV-Cache Compression
Mar 24, 2025Large Language Models (LLMs) with long context windows enable powerful applications but come at the cost of high memory consumption to store the Key and Value states (KV-Cache). Recent studies attempted to merge KV-cache from multiple layers into shared representations, yet these approaches either require expensive pretraining or rely on assumptions of high per-token cosine similarity across layers which generally does not hold in practice. We find that the dominant singular vectors are remarkably well-aligned across multiple layers of the KV-Cache. Exploiting this insight, we propose xKV, a simple post-training method that applies Singular Value Decomposition (SVD) on the KV-Cache of grouped layers. xKV consolidates the KV-Cache of multiple layers into a shared low-rank subspace, significantly reducing KV-Cache sizes. Through extensive evaluations on the RULER long-context benchmark with widely-used LLMs (e.g., Llama-3.1 and Qwen2.5), xKV achieves up to 6.8x higher compression rates than state-of-the-art inter-layer technique while improving accuracy by 2.7%. Moreover, xKV is compatible with the emerging Multi-Head Latent Attention (MLA) (e.g., DeepSeek-Coder-V2), yielding a notable 3x compression rates on coding tasks without performance degradation. These results highlight xKV's strong capability and versatility in addressing memory bottlenecks for long-context LLM inference. Our code is publicly available at: https://github.com/abdelfattah-lab/xKV.
TokenButler: Token Importance is Predictable
Mar 10, 2025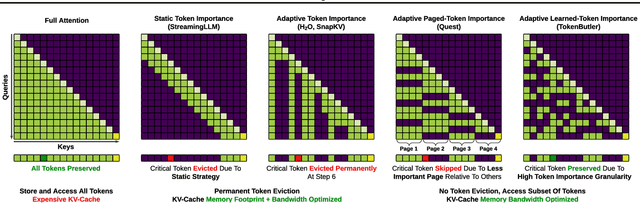
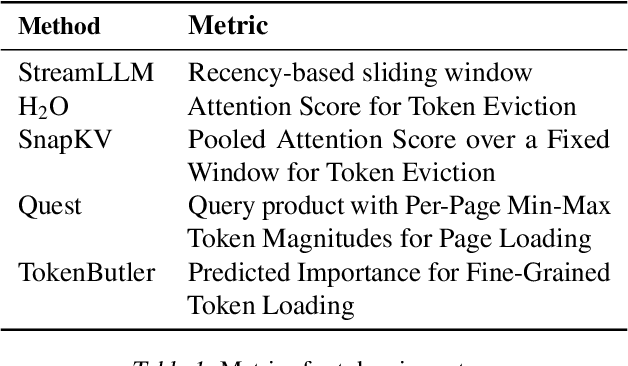
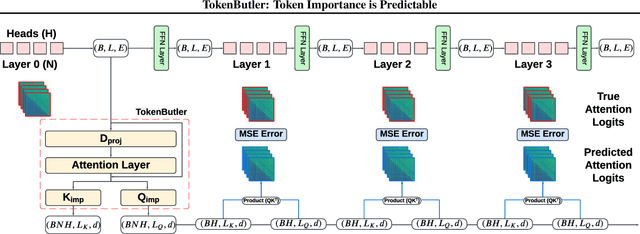
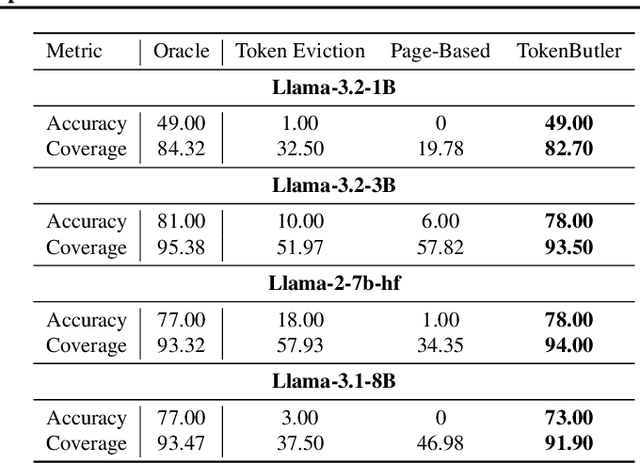
Large Language Models (LLMs) rely on the Key-Value (KV) Cache to store token history, enabling efficient decoding of tokens. As the KV-Cache grows, it becomes a major memory and computation bottleneck, however, there is an opportunity to alleviate this bottleneck, especially because prior research has shown that only a small subset of tokens contribute meaningfully to each decoding step. A key challenge in finding these critical tokens is that they are dynamic, and heavily input query-dependent. Existing methods either risk quality by evicting tokens permanently, or retain the full KV-Cache but rely on retrieving chunks (pages) of tokens at generation, failing at dense, context-rich tasks. Additionally, many existing KV-Cache sparsity methods rely on inaccurate proxies for token importance. To address these limitations, we introduce TokenButler, a high-granularity, query-aware predictor that learns to identify these critical tokens. By training a light-weight predictor with less than 1.2% parameter overhead, TokenButler prioritizes tokens based on their contextual, predicted importance. This improves perplexity & downstream accuracy by over 8% relative to SoTA methods for estimating token importance. We evaluate TokenButler on a novel synthetic small-context co-referential retrieval task, demonstrating near-oracle accuracy. Code, models and benchmarks: https://github.com/abdelfattah-lab/TokenButler
SparAMX: Accelerating Compressed LLMs Token Generation on AMX-powered CPUs
Feb 18, 2025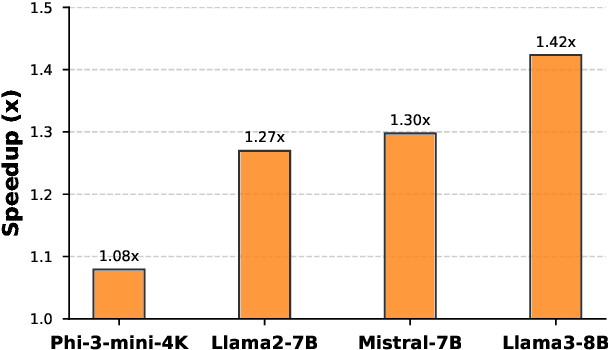

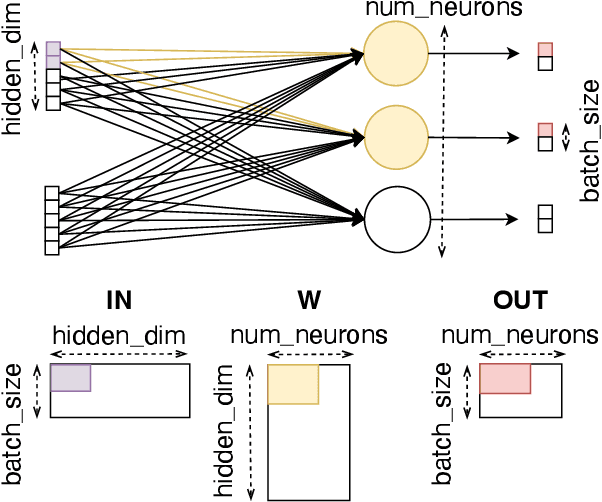
Large language models have high compute, latency, and memory requirements. While specialized accelerators such as GPUs and TPUs typically run these workloads, CPUs are more widely available and consume less energy. Accelerating LLMs with CPUs enables broader AI access at a lower cost and power consumption. This acceleration potential for CPUs is especially relevant during the memory-bound decoding stage of LLM inference, which processes one token at a time and is becoming increasingly utilized with reasoning models. We utilize Advanced Matrix Extensions (AMX) support on the latest Intel CPUs together with unstructured sparsity to achieve a $1.42 \times$ reduction in end-to-end latency compared to the current PyTorch implementation by applying our technique in linear layers. We provide a set of open-source customized sparse kernels that can speed up any PyTorch model by automatically replacing all linear layers with our custom sparse implementation. Furthermore, we demonstrate for the first time the use of unstructured sparsity in the attention computation achieving a $1.14 \times$ speedup over the current systems without compromising accuracy. Code: https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning/tree/main/SparAMX
The Power of Negative Zero: Datatype Customization for Quantized Large Language Models
Jan 06, 2025



Large language models (LLMs) have demonstrated remarkable performance across various machine learning tasks, quickly becoming one of the most prevalent AI workloads. Yet the substantial memory requirement of LLMs significantly hinders their deployment for end users. Post-training quantization (PTQ) serves as one of the most hardware-efficient methods to mitigate the memory and computational demands of LLMs. Although the traditional integer (INT) datatype has received widespread adoption in PTQ methods, floating-point (FP) quantization has emerged as a viable alternative thanks to its effectiveness in fitting LLM numerical distributions. However, the FP datatype in sign-magnitude binary representation contains both positive and negative zero, which constrains its representation capability, particularly under low precision (3 and 4 bits). In this paper, we extend the basic FP datatype to perform Redundant Zero Remapping (RaZeR), which remaps the negative zero FP encoding to a set of pre-defined special values to maximally utilize FP quantization encodings and to better fit LLM numerical distributions. Through careful selection of special values, RaZeR outperforms conventional asymmetric INT quantization while achieving high computational efficiency. We demonstrate that RaZeR can be seamlessly integrated with quantization algorithms for both weights and KV-cache, including advanced methods with clipping and transformations, and consistently achieve better model accuracy. Additionally, we implement a fast GEMV kernel with fused dequantization that efficiently converts the 4-bit RaZeR value to FP16 through novel bit-level manipulation. On modern GPUs, our evaluation shows that RaZeR improves the GEMV speed by up to 7.56$\times$ compared to the FP16 implementation, while achieving up to 2.72$\times$ speedup in the LLM decoding throughput.
Attamba: Attending To Multi-Token States
Nov 26, 2024



When predicting the next token in a sequence, vanilla transformers compute attention over all previous tokens, resulting in quadratic scaling of compute with sequence length. State-space models compress the entire sequence of tokens into a fixed-dimensional representation to improve efficiency, while other architectures achieve sub-quadratic complexity via low-rank projections or sparse attention patterns over the sequence. In this paper, we introduce Attamba, a novel architecture that uses state-space models to compress chunks of tokens and applies attention on these compressed key-value representations. We find that replacing key and value projections in a transformer with SSMs can improve model quality and enable flexible token chunking, resulting in 24% improved perplexity with transformer of similar KV-Cache and attention footprint, and ~4 times smaller KV-Cache and Attention FLOPs for 5% perplexity trade-off. Attamba can perform attention on chunked-sequences of variable length, enabling a smooth transition between quadratic and linear scaling, offering adaptable efficiency gains.
ShadowLLM: Predictor-based Contextual Sparsity for Large Language Models
Jun 24, 2024



The high power consumption and latency-sensitive deployments of large language models (LLMs) have motivated techniques like quantization and sparsity. Contextual sparsity, where the sparsity pattern is input-dependent, is crucial in LLMs because the permanent removal of attention heads or neurons from LLMs can significantly degrade accuracy. Prior work has attempted to model contextual sparsity using neural networks trained to predict activation magnitudes, which can be used to dynamically prune structures with low predicted activation magnitude. In this paper, we look beyond magnitude-based pruning criteria to assess attention head and neuron importance in LLMs. We developed a novel predictor called ShadowLLM, which can shadow the LLM behavior and enforce better sparsity patterns, resulting in over 15% improvement in end-to-end accuracy without increasing latency compared to previous methods. ShadowLLM achieves up to a 20\% speed-up over the state-of-the-art DejaVu framework. These enhancements are validated on models with up to 30 billion parameters. Our code is available at \href{https://github.com/abdelfattah-lab/shadow_llm/}{ShadowLLM}.