 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparAMX: Accelerating Compressed LLMs Token Generation on AMX-powered CPUs
Feb 18, 2025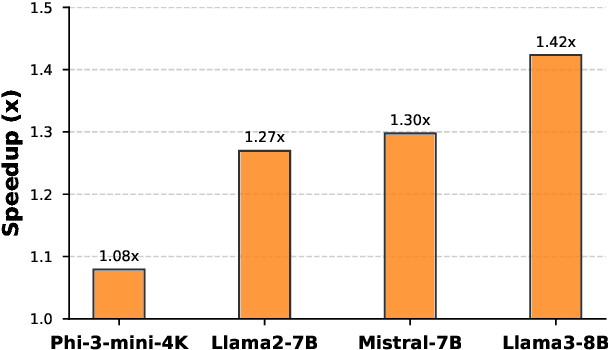

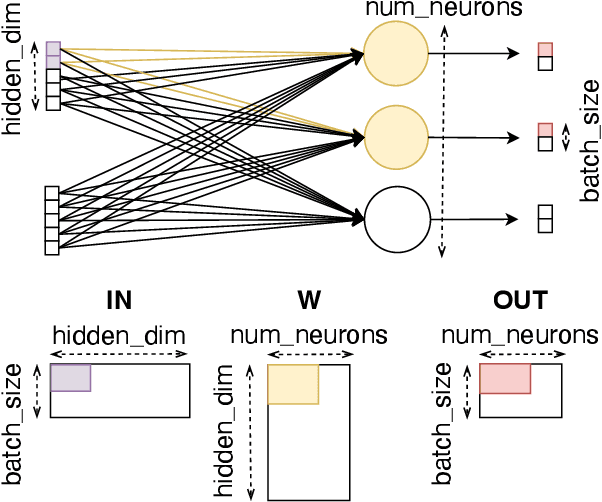
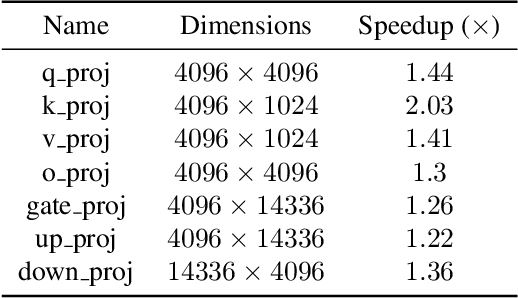
Large language models have high compute, latency, and memory requirements. While specialized accelerators such as GPUs and TPUs typically run these workloads, CPUs are more widely available and consume less energy. Accelerating LLMs with CPUs enables broader AI access at a lower cost and power consumption. This acceleration potential for CPUs is especially relevant during the memory-bound decoding stage of LLM inference, which processes one token at a time and is becoming increasingly utilized with reasoning models. We utilize Advanced Matrix Extensions (AMX) support on the latest Intel CPUs together with unstructured sparsity to achieve a $1.42 \times$ reduction in end-to-end latency compared to the current PyTorch implementation by applying our technique in linear layers. We provide a set of open-source customized sparse kernels that can speed up any PyTorch model by automatically replacing all linear layers with our custom sparse implementation. Furthermore, we demonstrate for the first time the use of unstructured sparsity in the attention computation achieving a $1.14 \times$ speedup over the current systems without compromising accuracy. Code: https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning/tree/main/SparAMX
Post-Training Statistical Calibration for Higher Activation Sparsity
Dec 10, 2024



We present Statistical Calibrated Activation Pruning (SCAP), a post-training activation pruning framework that (1) generalizes sparsification by input activations of Fully-Connected layers for generic and flexible application across Transformers, and (2) features a simple Mode-Centering technique to pre-calibrate activation distributions for maximizing post-training sparsity. Our results demonstrate robust Pareto efficiency compared to prior methods, translating to a 1.5x additional LLM decoding speedup against CATS at iso model quality. SCAP effectiveness is empirically verified across a wide range of models, including recent Transformer Decoders, MoE, Mamba2, Encoding Transformer, and pre-quantized models, highlighting its practicality and scalability. The code is available at: https://github.com/IntelLabs/SCAP.
Neuroevolution-Enhanced Multi-Objective Optimization for Mixed-Precision Quantization
Jun 14, 2021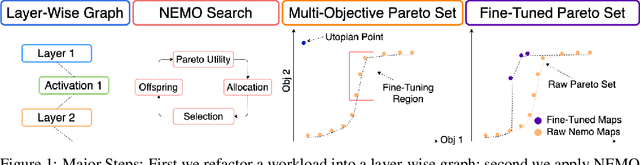
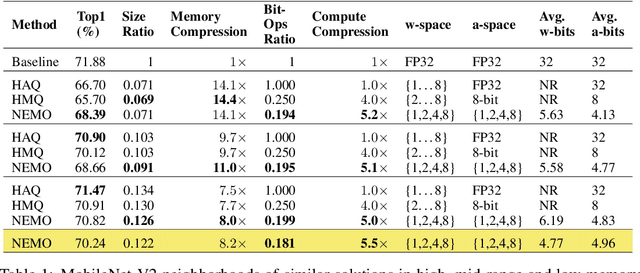
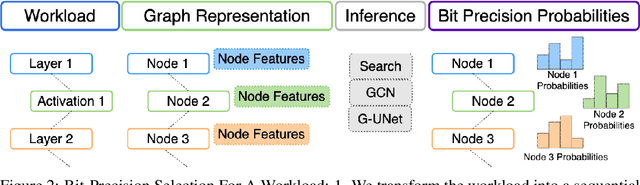
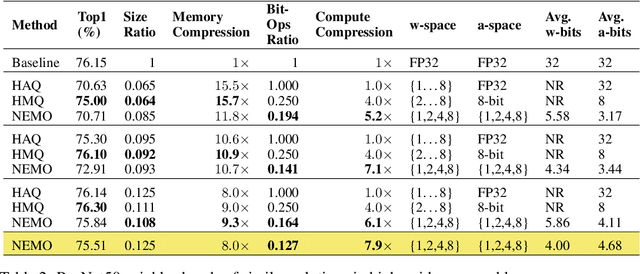
Mixed-precision quantization is a powerful tool to enable memory and compute savings of neural network workloads by deploying different sets of bit-width precisions on separate compute operations. Recent research has shown significant progress in applying mixed-precision quantization techniques to reduce the memory footprint of various workloads, while also preserving task performance. Prior work, however, has often ignored additional objectives, such as bit-operations, that are important for deployment of workloads on hardware. Here we present a flexible and scalable framework for automated mixed-precision quantization that optimizes multiple objectives. Our framework relies on Neuroevolution-Enhanced Multi-Objective Optimization (NEMO), a novel search method, to find Pareto optimal mixed-precision configurations for memory and bit-operations objectives. Within NEMO, a population is divided into structurally distinct sub-populations (species) which jointly form the Pareto frontier of solutions for the multi-objective problem. At each generation, species are re-sized in proportion to the goodness of their contribution to the Pareto frontier. This allows NEMO to leverage established search techniques and neuroevolution methods to continually improve the goodness of the Pareto frontier. In our experiments we apply a graph-based representation to describe the underlying workload, enabling us to deploy graph neural networks trained by NEMO to find Pareto optimal configurations for various workloads trained on ImageNet. Compared to the state-of-the-art, we achieve competitive results on memory compression and superior results for compute compression for MobileNet-V2, ResNet50 and ResNeXt-101-32x8d. A deeper analysis of the results obtained by NEMO also shows that both the graph representation and the species-based approach are critical in finding effective configurations for all workloads.