 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Compression of 3D Objects for Open and Collaborative Virtual Worlds
May 22, 2025

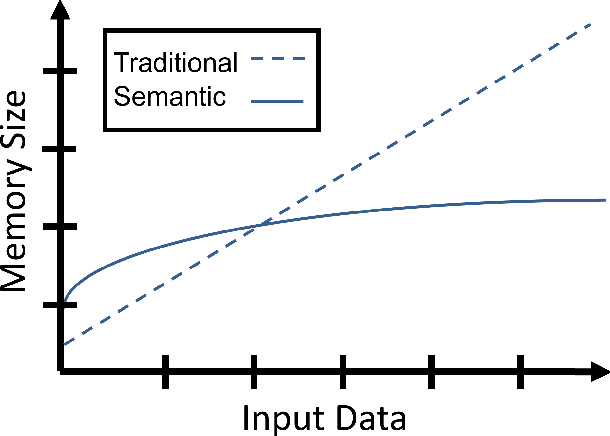

Traditional methods for 3D object compression operate only on structural information within the object vertices, polygons, and textures. These methods are effective at compression rates up to 10x for standard object sizes but quickly deteriorate at higher compression rates with texture artifacts, low-polygon counts, and mesh gaps. In contrast, semantic compression ignores structural information and operates directly on the core concepts to push to extreme levels of compression. In addition, it uses natural language as its storage format, which makes it natively human-readable and a natural fit for emerging applications built around large-scale, collaborative projects within augmented and virtual reality. It deprioritizes structural information like location, size, and orientation and predicts the missing information with state-of-the-art deep generative models. In this work, we construct a pipeline for 3D semantic compression from public generative models and explore the quality-compression frontier for 3D object compression. We apply this pipeline to achieve rates as high as 105x for 3D objects taken from the Objaverse dataset and show that semantic compression can outperform traditional methods in the important quality-preserving region around 100x compression.
SparAMX: Accelerating Compressed LLMs Token Generation on AMX-powered CPUs
Feb 18, 2025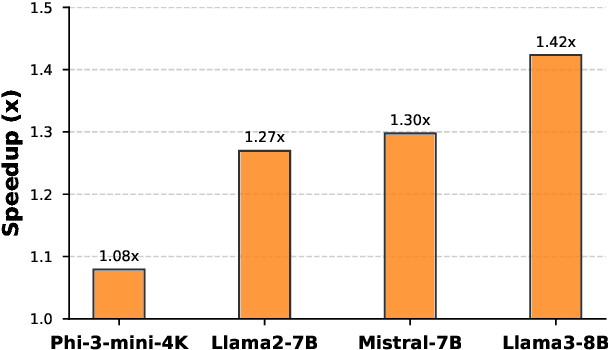

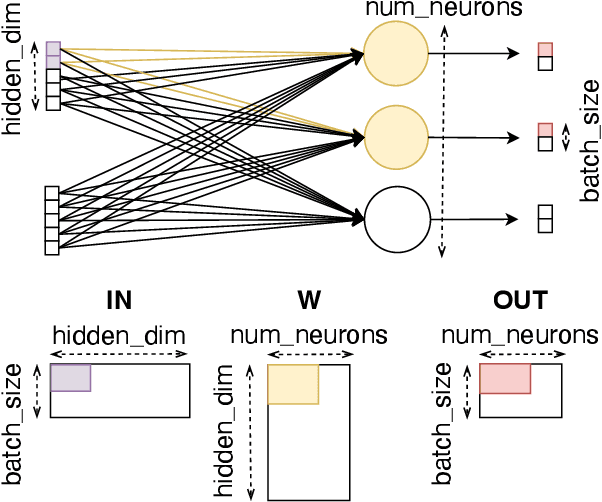
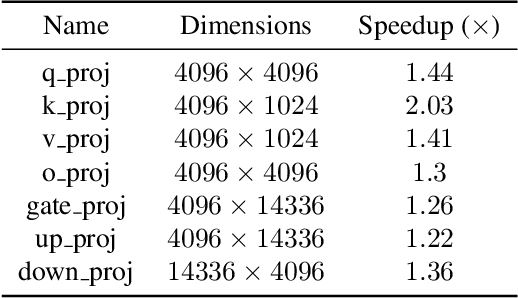
Large language models have high compute, latency, and memory requirements. While specialized accelerators such as GPUs and TPUs typically run these workloads, CPUs are more widely available and consume less energy. Accelerating LLMs with CPUs enables broader AI access at a lower cost and power consumption. This acceleration potential for CPUs is especially relevant during the memory-bound decoding stage of LLM inference, which processes one token at a time and is becoming increasingly utilized with reasoning models. We utilize Advanced Matrix Extensions (AMX) support on the latest Intel CPUs together with unstructured sparsity to achieve a $1.42 \times$ reduction in end-to-end latency compared to the current PyTorch implementation by applying our technique in linear layers. We provide a set of open-source customized sparse kernels that can speed up any PyTorch model by automatically replacing all linear layers with our custom sparse implementation. Furthermore, we demonstrate for the first time the use of unstructured sparsity in the attention computation achieving a $1.14 \times$ speedup over the current systems without compromising accuracy. Code: https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning/tree/main/SparAMX
ShadowLLM: Predictor-based Contextual Sparsity for Large Language Models
Jun 24, 2024



The high power consumption and latency-sensitive deployments of large language models (LLMs) have motivated techniques like quantization and sparsity. Contextual sparsity, where the sparsity pattern is input-dependent, is crucial in LLMs because the permanent removal of attention heads or neurons from LLMs can significantly degrade accuracy. Prior work has attempted to model contextual sparsity using neural networks trained to predict activation magnitudes, which can be used to dynamically prune structures with low predicted activation magnitude. In this paper, we look beyond magnitude-based pruning criteria to assess attention head and neuron importance in LLMs. We developed a novel predictor called ShadowLLM, which can shadow the LLM behavior and enforce better sparsity patterns, resulting in over 15% improvement in end-to-end accuracy without increasing latency compared to previous methods. ShadowLLM achieves up to a 20\% speed-up over the state-of-the-art DejaVu framework. These enhancements are validated on models with up to 30 billion parameters. Our code is available at \href{https://github.com/abdelfattah-lab/shadow_llm/}{ShadowLLM}.
Learning from Students: Applying t-Distributions to Explore Accurate and Efficient Formats for LLMs
May 06, 2024



Large language models (LLMs) have recently achieved state-of-the-art performance across various tasks, yet due to their large computational requirements, they struggle with strict latency and power demands. Deep neural network (DNN) quantization has traditionally addressed these limitations by converting models to low-precision integer formats. Yet recently alternative formats, such as Normal Float (NF4), have been shown to consistently increase model accuracy, albeit at the cost of increased chip area. In this work, we first conduct a large-scale analysis of LLM weights and activations across 30 networks to conclude most distributions follow a Student's t-distribution. We then derive a new theoretically optimal format, Student Float (SF4), with respect to this distribution, that improves over NF4 across modern LLMs, for example increasing the average accuracy on LLaMA2-7B by 0.76% across tasks. Using this format as a high-accuracy reference, we then propose augmenting E2M1 with two variants of supernormal support for higher model accuracy. Finally, we explore the quality and performance frontier across 11 datatypes, including non-traditional formats like Additive-Powers-of-Two (APoT), by evaluating their model accuracy and hardware complexity. We discover a Pareto curve composed of INT4, E2M1, and E2M1 with supernormal support, which offers a continuous tradeoff between model accuracy and chip area. For example, E2M1 with supernormal support increases the accuracy of Phi-2 by up to 2.19% with 1.22% area overhead, enabling more LLM-based applications to be run at four bits.
Radial Networks: Dynamic Layer Routing for High-Performance Large Language Models
Apr 07, 2024Large language models (LLMs) often struggle with strict memory, latency, and power demands. To meet these demands, various forms of dynamic sparsity have been proposed that reduce compute on an input-by-input basis. These methods improve over static methods by exploiting the variance across individual inputs, which has steadily grown with the exponential increase in training data. Yet, the increasing depth within modern models, currently with hundreds of layers, has opened opportunities for dynamic layer sparsity, which skips the computation for entire layers. In this work, we explore the practicality of layer sparsity by profiling residual connections and establish the relationship between model depth and layer sparsity. For example, the residual blocks in the OPT-66B model have a median contribution of 5% to its output. We then take advantage of this dynamic sparsity and propose Radial Networks, which perform token-level routing between layers guided by a trained router module. These networks can be used in a post-training distillation from sequential networks or trained from scratch to co-learn the router and layer weights. They enable scaling to larger model sizes by decoupling the number of layers from the dynamic depth of the network, and their design allows for layer reuse. By varying the compute token by token, they reduce the overall resources needed for generating entire sequences. Overall, this leads to larger capacity networks with significantly lower compute and serving costs for large language models.
Exploring the Limits of Semantic Image Compression at Micro-bits per Pixel
Feb 21, 2024



Traditional methods, such as JPEG, perform image compression by operating on structural information, such as pixel values or frequency content. These methods are effective to bitrates around one bit per pixel (bpp) and higher at standard image sizes. In contrast, text-based semantic compression directly stores concepts and their relationships using natural language, which has evolved with humans to efficiently represent these salient concepts. These methods can operate at extremely low bitrates by disregarding structural information like location, size, and orientation. In this work, we use GPT-4V and DALL-E3 from OpenAI to explore the quality-compression frontier for image compression and identify the limitations of current technology. We push semantic compression as low as 100 $\mu$bpp (up to $10,000\times$ smaller than JPEG) by introducing an iterative reflection process to improve the decoded image. We further hypothesize this 100 $\mu$bpp level represents a soft limit on semantic compression at standard image resolutions.
FLIQS: One-Shot Mixed-Precision Floating-Point and Integer Quantization Search
Aug 07, 2023


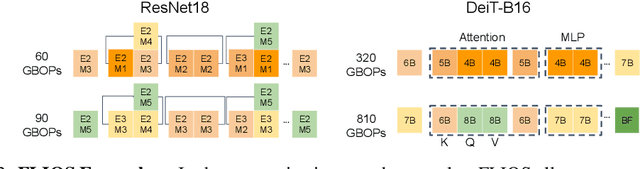
Quantization has become a mainstream compression technique for reducing model size, computational requirements, and energy consumption for modern deep neural networks (DNNs). With the improved numerical support in recent hardware, including multiple variants of integer and floating point, mixed-precision quantization has become necessary to achieve high-quality results with low model cost. Prior mixed-precision quantization methods have performed a post-training quantization search, which compromises on accuracy, or a differentiable quantization search, which leads to high memory usage from branching. Therefore, we propose the first one-shot mixed-precision quantization search that eliminates the need for retraining in both integer and low-precision floating point models. We evaluate our floating-point and integer quantization search (FLIQS) on multiple convolutional networks and vision transformer models to discover Pareto-optimal models. Our approach discovers models that improve upon uniform precision, manual mixed-precision, and recent integer quantization search methods. With the proposed integer quantization search, we increase the accuracy of ResNet-18 on ImageNet by 1.31% points and ResNet-50 by 0.90% points with equivalent model cost over previous methods. Additionally, for the first time, we explore a novel mixed-precision floating-point search and improve MobileNetV2 by up to 0.98% points compared to prior state-of-the-art FP8 models. Finally, we extend FLIQS to simultaneously search a joint quantization and neural architecture space and improve the ImageNet accuracy by 2.69% points with similar model cost on a MobileNetV2 search space.
Enabling Design Methodologies and Future Trends for Edge AI: Specialization and Co-design
Mar 30, 2021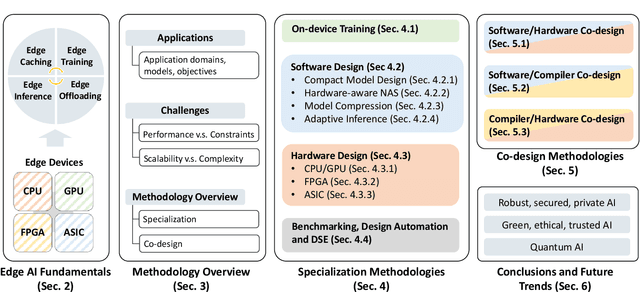
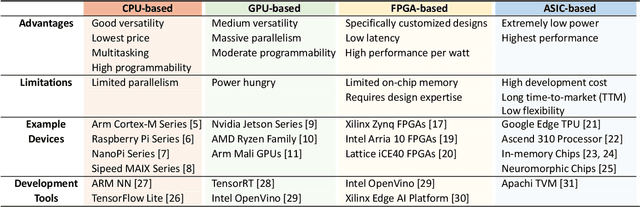

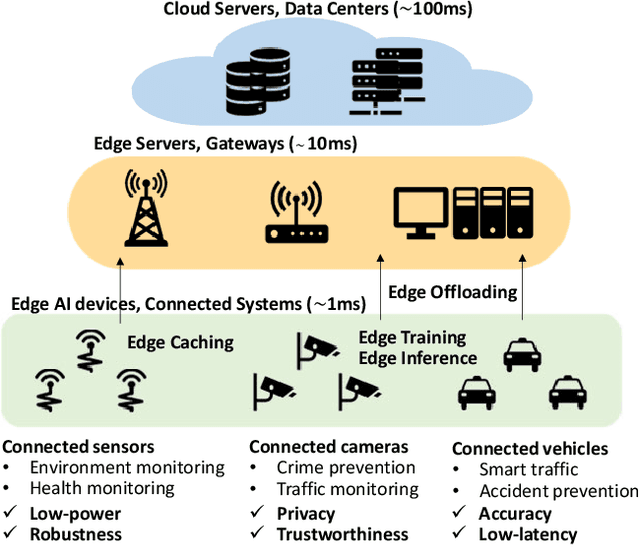
Artificial intelligence (AI) technologies have dramatically advanced in recent years, resulting in revolutionary changes in people's lives. Empowered by edge computing, AI workloads are migrating from centralized cloud architectures to distributed edge systems, introducing a new paradigm called edge AI. While edge AI has the promise of bringing significant increases in autonomy and intelligence into everyday lives through common edge devices, it also raises new challenges, especially for the development of its algorithms and the deployment of its services, which call for novel design methodologies catered to these unique challenges. In this paper, we provide a comprehensive survey of the latest enabling design methodologies that span the entire edge AI development stack. We suggest that the key methodologies for effective edge AI development are single-layer specialization and cross-layer co-design. We discuss representative methodologies in each category in detail, including on-device training methods, specialized software design, dedicated hardware design, benchmarking and design automation, software/hardware co-design, software/compiler co-design, and compiler/hardware co-design. Moreover, we attempt to reveal hidden cross-layer design opportunities that can further boost the solution quality of future edge AI and provide insights into future directions and emerging areas that require increased research focus.
Logic Synthesis Meets Machine Learning: Trading Exactness for Generalization
Dec 15, 2020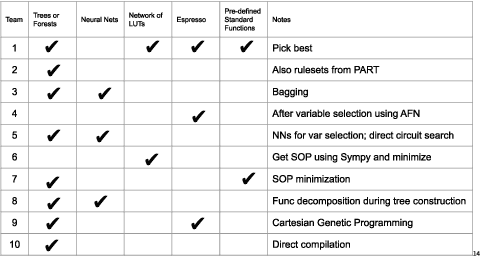
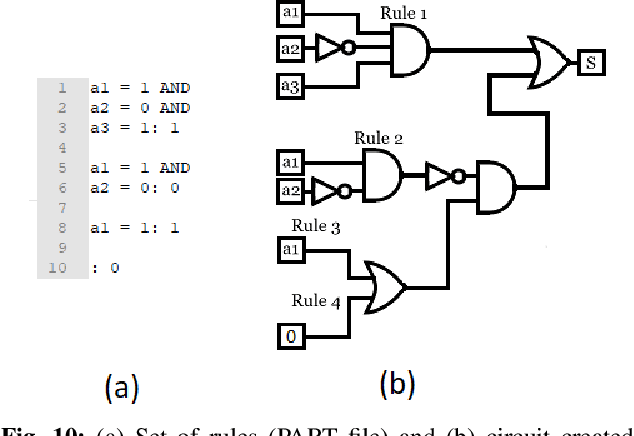
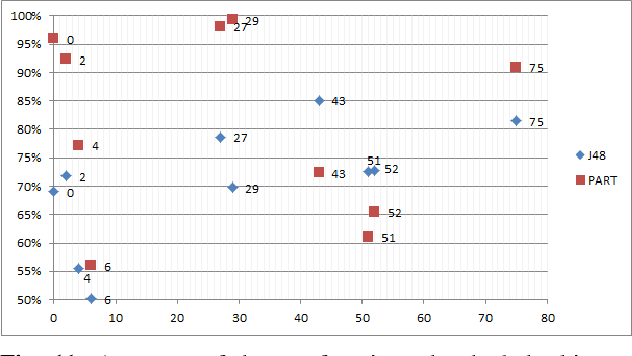
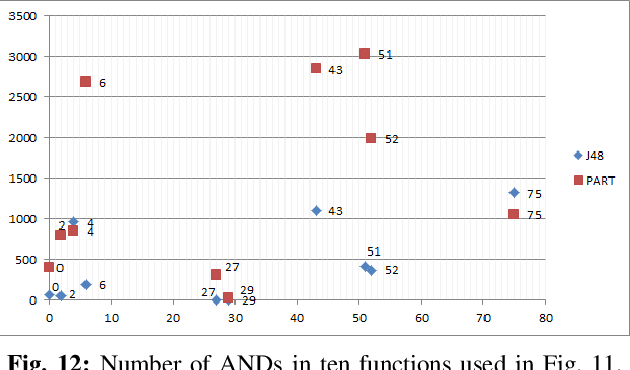
Logic synthesis is a fundamental step in hardware design whose goal is to find structural representations of Boolean functions while minimizing delay and area. If the function is completely-specified, the implementation accurately represents the function. If the function is incompletely-specified, the implementation has to be true only on the care set. While most of the algorithms in logic synthesis rely on SAT and Boolean methods to exactly implement the care set, we investigate learning in logic synthesis, attempting to trade exactness for generalization. This work is directly related to machine learning where the care set is the training set and the implementation is expected to generalize on a validation set. We present learning incompletely-specified functions based on the results of a competition conducted at IWLS 2020. The goal of the competition was to implement 100 functions given by a set of care minterms for training, while testing the implementation using a set of validation minterms sampled from the same function. We make this benchmark suite available and offer a detailed comparative analysis of the different approaches to learning
Improving Neural Network Quantization without Retraining using Outlier Channel Splitting
Jan 30, 2019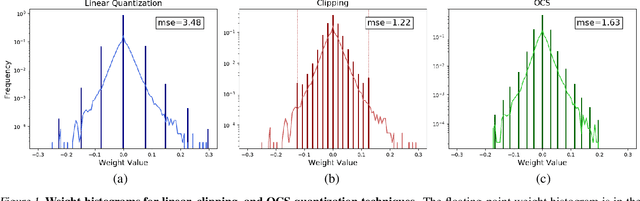
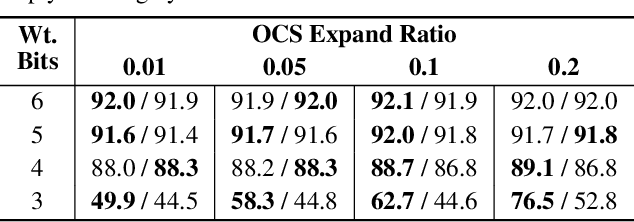
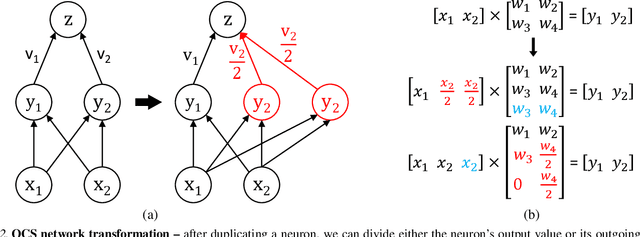
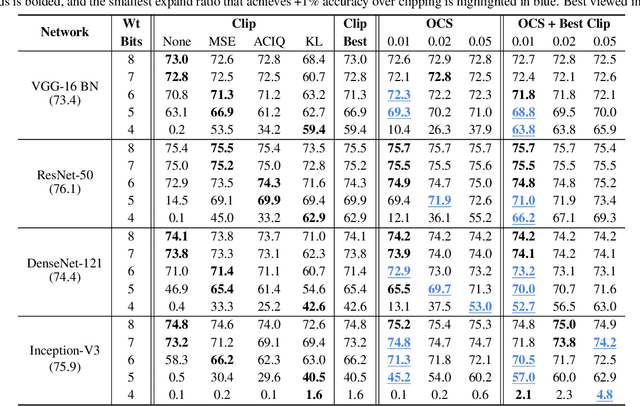
Quantization can improve the execution latency and energy efficiency of neural networks on both commodity GPUs and specialized accelerators. The majority of existing literature focuses on training quantized DNNs, while this work examines the less-studied topic of quantizing a floating-point model without (re)training. DNN weights and activations follow a bell-shaped distribution post-training, while practical hardware uses a linear quantization grid. This leads to challenges in dealing with outliers in the distribution. Prior work has addressed this by clipping the outliers or using specialized hardware. In this work, we propose outlier channel splitting (OCS), which duplicates channels containing outliers, then halves the channel values. The network remains functionally identical, but affected outliers are moved toward the center of the distribution. OCS requires no additional training and works on commodity hardware. Experimental evaluation on ImageNet classification and language modeling shows that OCS can outperform state-of-the-art clipping techniques with only minor overhead.