 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparAMX: Accelerating Compressed LLMs Token Generation on AMX-powered CPUs
Feb 18, 2025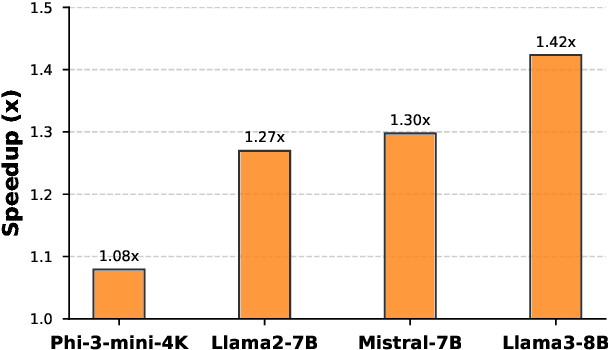

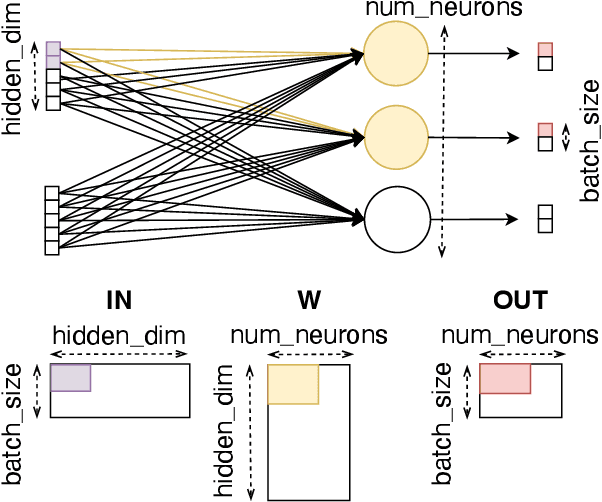
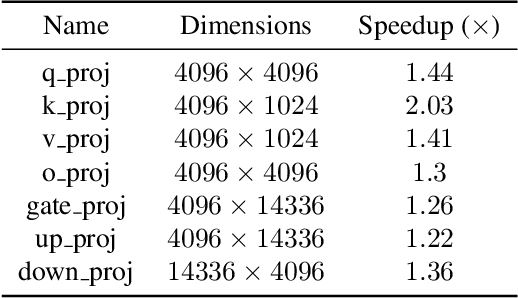
Large language models have high compute, latency, and memory requirements. While specialized accelerators such as GPUs and TPUs typically run these workloads, CPUs are more widely available and consume less energy. Accelerating LLMs with CPUs enables broader AI access at a lower cost and power consumption. This acceleration potential for CPUs is especially relevant during the memory-bound decoding stage of LLM inference, which processes one token at a time and is becoming increasingly utilized with reasoning models. We utilize Advanced Matrix Extensions (AMX) support on the latest Intel CPUs together with unstructured sparsity to achieve a $1.42 \times$ reduction in end-to-end latency compared to the current PyTorch implementation by applying our technique in linear layers. We provide a set of open-source customized sparse kernels that can speed up any PyTorch model by automatically replacing all linear layers with our custom sparse implementation. Furthermore, we demonstrate for the first time the use of unstructured sparsity in the attention computation achieving a $1.14 \times$ speedup over the current systems without compromising accuracy. Code: https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning/tree/main/SparAMX
Mamba-Shedder: Post-Transformer Compression for Efficient Selective Structured State Space Models
Jan 28, 2025



Large pre-trained models have achieved outstanding results in sequence modeling. The Transformer block and its attention mechanism have been the main drivers of the success of these models. Recently, alternative architectures, such as Selective Structured State Space Models (SSMs), have been proposed to address the inefficiencies of Transformers. This paper explores the compression of SSM-based models, particularly Mamba and its hybrids. We study the sensitivity of these models to the removal of selected components at different granularities to reduce the model size and computational overhead, thus improving their efficiency while maintaining accuracy. The proposed solutions, collectively referred to as Mamba-Shedder, achieve a speedup of up to 1.4x during inference, demonstrating that model efficiency can be improved by eliminating several redundancies with minimal impact on the overall model performance. The code is available at https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning.
MultiPruner: Balanced Structure Removal in Foundation Models
Jan 17, 2025



Recently, state-of-the-art approaches for pruning large pre-trained models (LPMs) have demonstrated that the training-free removal of non-critical residual blocks in Transformers is viable for reducing model size, achieving results that outperform previous training-free pruning approaches. Motivated by these findings, we extend BlockPruner (Zhong et al., 2024) and propose MultiPruner, a pruning approach that surpasses recent training-free pruning methods by adopting a multidimensional, iterative, fine-grained pruning strategy. In MultiPruner, multidimensional pruning reinstates the structural balance in block-pruned models by sequentially compressing along three dimensions: i) residual blocks, ii) channels of multilayer perceptrons (MLP), and iii) attention heads. This solution enhances zero-shot accuracy on downstream tasks compared to other techniques while improving model compression ratios, producing compressed models with fewer computing and memory requirements. Extensive experiments demonstrate the advantages of the proposed method across various large pre-trained models. The code and pruning configurations are available at https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning.
Shears: Unstructured Sparsity with Neural Low-rank Adapter Search
Apr 16, 2024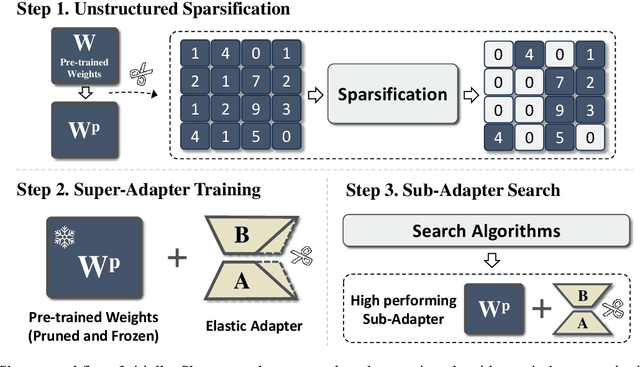
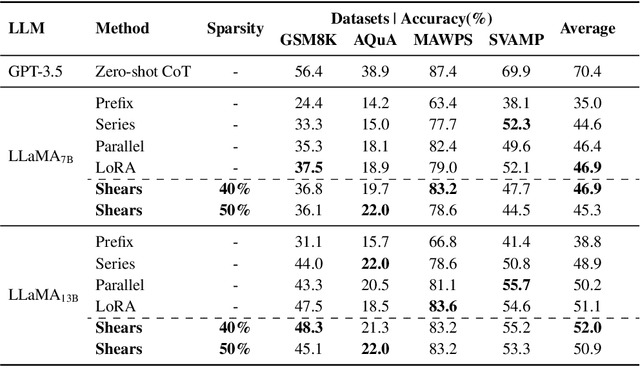

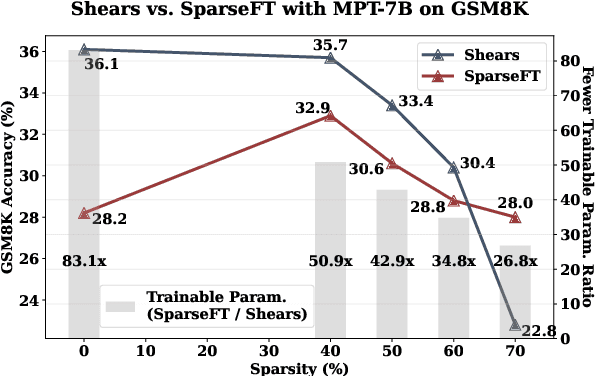
Recently, several approaches successfully demonstrated that weight-sharing Neural Architecture Search (NAS) can effectively explore a search space of elastic low-rank adapters (LoRA), allowing the parameter-efficient fine-tuning (PEFT) and compression of large language models. In this paper, we introduce a novel approach called Shears, demonstrating how the integration of cost-effective sparsity and a proposed Neural Low-rank adapter Search (NLS) algorithm can further improve the efficiency of PEFT approaches. Results demonstrate the benefits of Shears compared to other methods, reaching high sparsity levels while improving or with little drop in accuracy, utilizing a single GPU for a pair of hours.
Bridging the Gap Between Foundation Models and Heterogeneous Federated Learning
Oct 04, 2023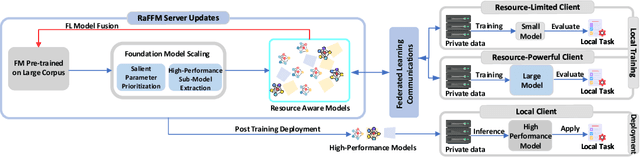
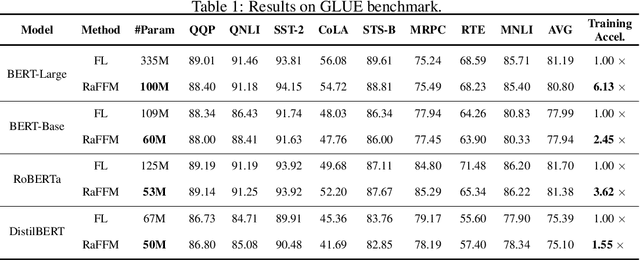
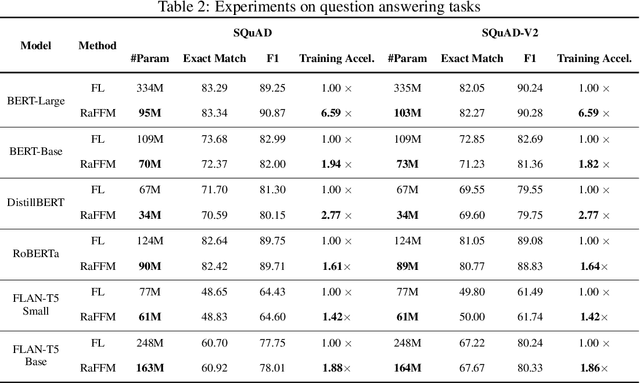

Federated learning (FL) offers privacy-preserving decentralized machine learning, optimizing models at edge clients without sharing private data. Simultaneously, foundation models (FMs) have gained traction in the artificial intelligence (AI) community due to their exceptional performance across various tasks. However, integrating FMs into FL presents challenges, primarily due to their substantial size and intensive resource requirements. This is especially true when considering the resource heterogeneity in edge FL systems. We present an adaptive framework for Resource-aware Federated Foundation Models (RaFFM) to address these challenges. RaFFM introduces specialized model compression algorithms tailored for FL scenarios, such as salient parameter prioritization and high-performance subnetwork extraction. These algorithms enable dynamic scaling of given transformer-based FMs to fit heterogeneous resource constraints at the network edge during both FL's optimization and deployment stages. Experimental results demonstrate that RaFFM shows significant superiority in resource utilization efficiency and uses fewer resources to deploy FMs to FL. Despite the lower resource consumption, target models optimized by RaFFM achieve performance on par with traditional FL methods applied to full-sized FMs. This is evident across tasks in both natural language processing and computer vision domains.
Federated Foundation Models: Privacy-Preserving and Collaborative Learning for Large Models
May 19, 2023



Foundation Models (FMs), such as BERT, GPT, ViT, and CLIP, have demonstrated remarkable success in a wide range of applications, driven by their ability to leverage vast amounts of data for pre-training. However, optimizing FMs often requires access to sensitive data, raising privacy concerns and limiting their applicability in certain domains. In this paper, we introduce the concept of Federated Foundation Models (FFMs), a novel approach that combines the benefits of FMs and Federated Learning (FL) to enable privacy-preserving and collaborative learning across multiple institutions. We discuss the potential benefits and challenges of integrating FL into the lifespan of FMs, covering pre-training, fine-tuning, and application. We further provide formal definitions of FFM tasks, including FFM pre-training, FFM fine-tuning, and federated prompt engineering, allowing for more personalized and context-aware models while maintaining data privacy. Moreover, we explore the possibility of continual/lifelong learning in FFMs, as increased computational power at the edge unlocks the potential for optimizing FMs using newly generated private data at edges. We present experiments and evaluations comparing the performance of FFMs to traditional FMs on various downstream tasks, demonstrating the effectiveness of our approach in preserving privacy, reducing overfitting, and improving model generalizability. The proposed Federated Foundation Models offer a flexible and scalable framework for training large language models in a privacy-preserving manner, paving the way for future advancements in both FM pre-training and federated learning.
Enabling NAS with Automated Super-Network Generation
Dec 20, 2021
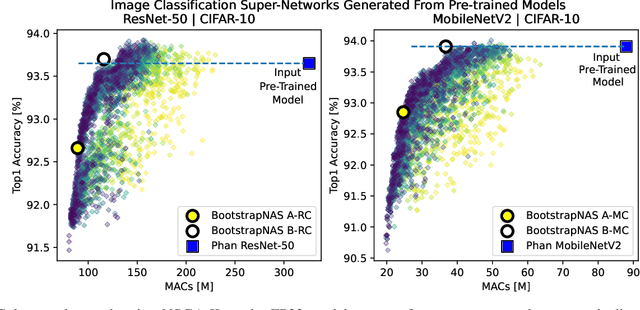
Recent Neural Architecture Search (NAS) solutions have produced impressive results training super-networks and then deriving subnetworks, a.k.a. child models that outperform expert-crafted models from a pre-defined search space. Efficient and robust subnetworks can be selected for resource-constrained edge devices, allowing them to perform well in the wild. However, constructing super-networks for arbitrary architectures is still a challenge that often prevents the adoption of these approaches. To address this challenge, we present BootstrapNAS, a software framework for automatic generation of super-networks for NAS. BootstrapNAS takes a pre-trained model from a popular architecture, e.g., ResNet- 50, or from a valid custom design, and automatically creates a super-network out of it, then uses state-of-the-art NAS techniques to train the super-network, resulting in subnetworks that significantly outperform the given pre-trained model. We demonstrate the solution by generating super-networks from arbitrary model repositories and make available the resulting super-networks for reproducibility of the results.
RHNAS: Realizable Hardware and Neural Architecture Search
Jun 17, 2021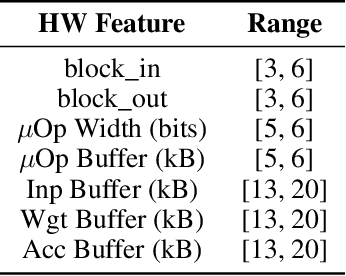
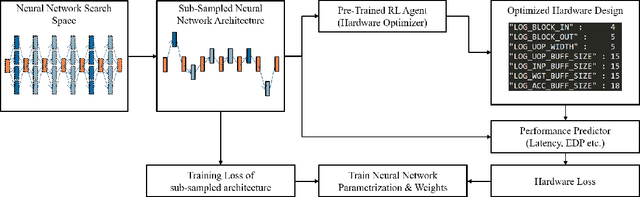
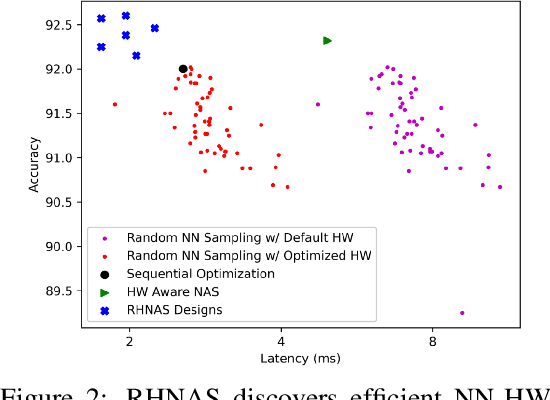

The rapidly evolving field of Artificial Intelligence necessitates automated approaches to co-design neural network architecture and neural accelerators to maximize system efficiency and address productivity challenges. To enable joint optimization of this vast space, there has been growing interest in differentiable NN-HW co-design. Fully differentiable co-design has reduced the resource requirements for discovering optimized NN-HW configurations, but fail to adapt to general hardware accelerator search spaces. This is due to the existence of non-synthesizable (invalid) designs in the search space of many hardware accelerators. To enable efficient and realizable co-design of configurable hardware accelerators with arbitrary neural network search spaces, we introduce RHNAS. RHNAS is a method that combines reinforcement learning for hardware optimization with differentiable neural architecture search. RHNAS discovers realizable NN-HW designs with 1.84x lower latency and 1.86x lower energy-delay product (EDP) on ImageNet and 2.81x lower latency and 3.30x lower EDP on CIFAR-10 over the default hardware accelerator design.