 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperSAM: Crafting a SAM Supernetwork via Structured Pruning and Unstructured Parameter Prioritization
Jan 15, 2025



Neural Architecture Search (NAS) is a powerful approach of automating the design of efficient neural architectures. In contrast to traditional NAS methods, recently proposed one-shot NAS methods prove to be more efficient in performing NAS. One-shot NAS works by generating a singular weight-sharing supernetwork that acts as a search space (container) of subnetworks. Despite its achievements, designing the one-shot search space remains a major challenge. In this work we propose a search space design strategy for Vision Transformer (ViT)-based architectures. In particular, we convert the Segment Anything Model (SAM) into a weight-sharing supernetwork called SuperSAM. Our approach involves automating the search space design via layer-wise structured pruning and parameter prioritization. While the structured pruning applies probabilistic removal of certain transformer layers, parameter prioritization performs weight reordering and slicing of MLP-blocks in the remaining layers. We train supernetworks on several datasets using the sandwich rule. For deployment, we enhance subnetwork discovery by utilizing a program autotuner to identify efficient subnetworks within the search space. The resulting subnetworks are 30-70% smaller in size compared to the original pre-trained SAM ViT-B, yet outperform the pretrained model. Our work introduces a new and effective method for ViT NAS search-space design.
PipeInfer: Accelerating LLM Inference using Asynchronous Pipelined Speculation
Jul 16, 2024



Inference of Large Language Models (LLMs) across computer clusters has become a focal point of research in recent times, with many acceleration techniques taking inspiration from CPU speculative execution. These techniques reduce bottlenecks associated with memory bandwidth, but also increase end-to-end latency per inference run, requiring high speculation acceptance rates to improve performance. Combined with a variable rate of acceptance across tasks, speculative inference techniques can result in reduced performance. Additionally, pipeline-parallel designs require many user requests to maintain maximum utilization. As a remedy, we propose PipeInfer, a pipelined speculative acceleration technique to reduce inter-token latency and improve system utilization for single-request scenarios while also improving tolerance to low speculation acceptance rates and low-bandwidth interconnects. PipeInfer exhibits up to a 2.15$\times$ improvement in generation speed over standard speculative inference. PipeInfer achieves its improvement through Continuous Asynchronous Speculation and Early Inference Cancellation, the former improving latency and generation speed by running single-token inference simultaneously with several speculative runs, while the latter improves speed and latency by skipping the computation of invalidated runs, even in the middle of inference.
The Landscape and Challenges of HPC Research and LLMs
Feb 07, 2024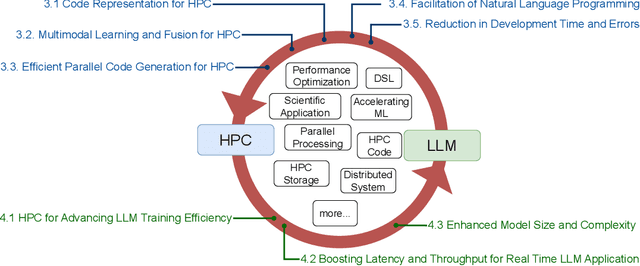

Recently, language models (LMs), especially large language models (LLMs), have revolutionized the field of deep learning. Both encoder-decoder models and prompt-based techniques have shown immense potential for natural language processing and code-based tasks. Over the past several years, many research labs and institutions have invested heavily in high-performance computing, approaching or breaching exascale performance levels. In this paper, we posit that adapting and utilizing such language model-based techniques for tasks in high-performance computing (HPC) would be very beneficial. This study presents our reasoning behind the aforementioned position and highlights how existing ideas can be improved and adapted for HPC tasks.
Bridging the Gap Between Foundation Models and Heterogeneous Federated Learning
Oct 04, 2023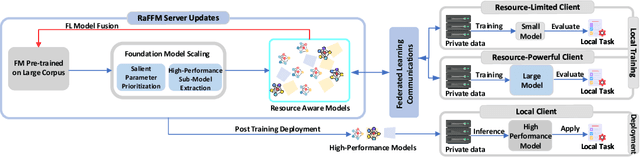
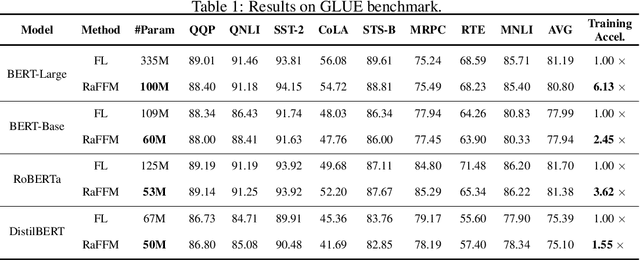
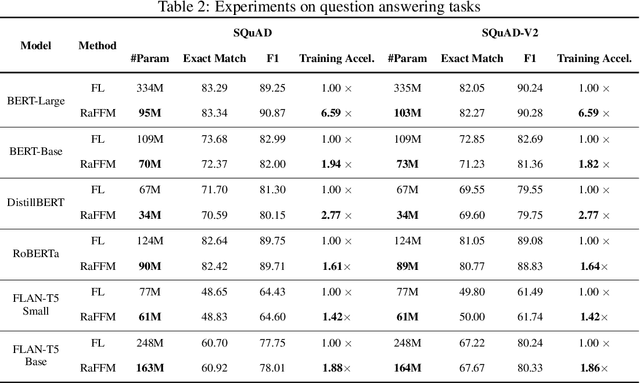

Federated learning (FL) offers privacy-preserving decentralized machine learning, optimizing models at edge clients without sharing private data. Simultaneously, foundation models (FMs) have gained traction in the artificial intelligence (AI) community due to their exceptional performance across various tasks. However, integrating FMs into FL presents challenges, primarily due to their substantial size and intensive resource requirements. This is especially true when considering the resource heterogeneity in edge FL systems. We present an adaptive framework for Resource-aware Federated Foundation Models (RaFFM) to address these challenges. RaFFM introduces specialized model compression algorithms tailored for FL scenarios, such as salient parameter prioritization and high-performance subnetwork extraction. These algorithms enable dynamic scaling of given transformer-based FMs to fit heterogeneous resource constraints at the network edge during both FL's optimization and deployment stages. Experimental results demonstrate that RaFFM shows significant superiority in resource utilization efficiency and uses fewer resources to deploy FMs to FL. Despite the lower resource consumption, target models optimized by RaFFM achieve performance on par with traditional FL methods applied to full-sized FMs. This is evident across tasks in both natural language processing and computer vision domains.
Federated Foundation Models: Privacy-Preserving and Collaborative Learning for Large Models
May 19, 2023



Foundation Models (FMs), such as BERT, GPT, ViT, and CLIP, have demonstrated remarkable success in a wide range of applications, driven by their ability to leverage vast amounts of data for pre-training. However, optimizing FMs often requires access to sensitive data, raising privacy concerns and limiting their applicability in certain domains. In this paper, we introduce the concept of Federated Foundation Models (FFMs), a novel approach that combines the benefits of FMs and Federated Learning (FL) to enable privacy-preserving and collaborative learning across multiple institutions. We discuss the potential benefits and challenges of integrating FL into the lifespan of FMs, covering pre-training, fine-tuning, and application. We further provide formal definitions of FFM tasks, including FFM pre-training, FFM fine-tuning, and federated prompt engineering, allowing for more personalized and context-aware models while maintaining data privacy. Moreover, we explore the possibility of continual/lifelong learning in FFMs, as increased computational power at the edge unlocks the potential for optimizing FMs using newly generated private data at edges. We present experiments and evaluations comparing the performance of FFMs to traditional FMs on various downstream tasks, demonstrating the effectiveness of our approach in preserving privacy, reducing overfitting, and improving model generalizability. The proposed Federated Foundation Models offer a flexible and scalable framework for training large language models in a privacy-preserving manner, paving the way for future advancements in both FM pre-training and federated learning.
Resource-Aware Heterogeneous Federated Learning using Neural Architecture Search
Nov 09, 2022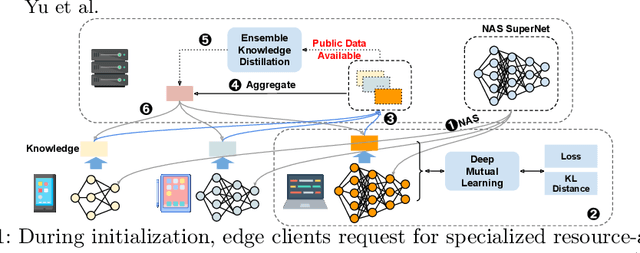
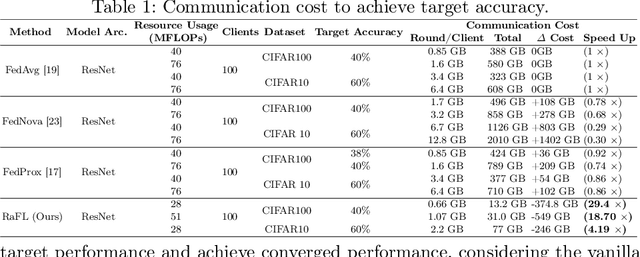
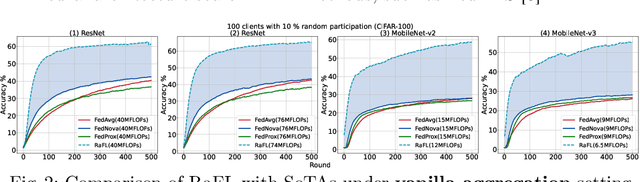
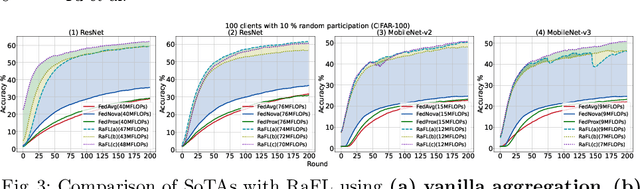
Federated Learning (FL) is extensively used to train AI/ML models in distributed and privacy-preserving settings. Participant edge devices in FL systems typically contain non-independent and identically distributed~(Non-IID) private data and unevenly distributed computational resources. Preserving user data privacy while optimizing AI/ML models in a heterogeneous federated network requires us to address data heterogeneity and system/resource heterogeneity. Hence, we propose \underline{R}esource-\underline{a}ware \underline{F}ederated \underline{L}earning~(RaFL) to address these challenges. RaFL allocates resource-aware models to edge devices using Neural Architecture Search~(NAS) and allows heterogeneous model architecture deployment by knowledge extraction and fusion. Integrating NAS into FL enables on-demand customized model deployment for resource-diverse edge devices. Furthermore, we propose a multi-model architecture fusion scheme allowing the aggregation of the distributed learning results. Results demonstrate RaFL's superior resource efficiency compared to SoTA.
Resource-aware Federated Learning using Knowledge Extraction and Multi-model Fusion
Aug 16, 2022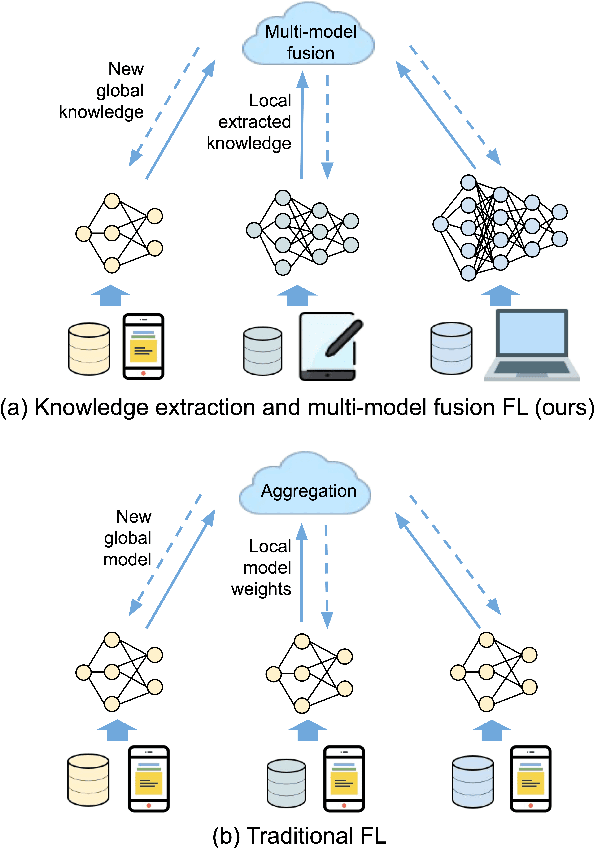
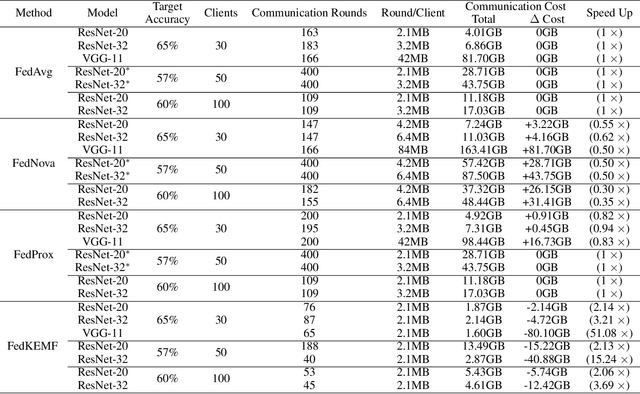
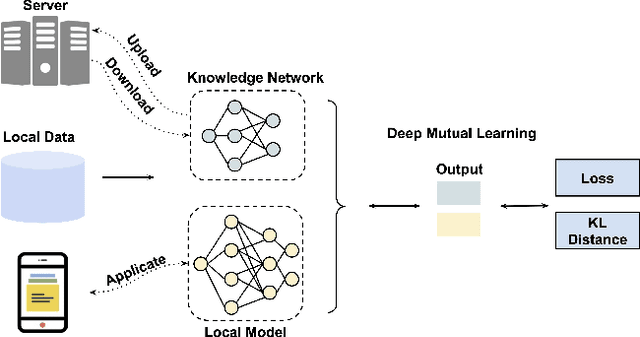
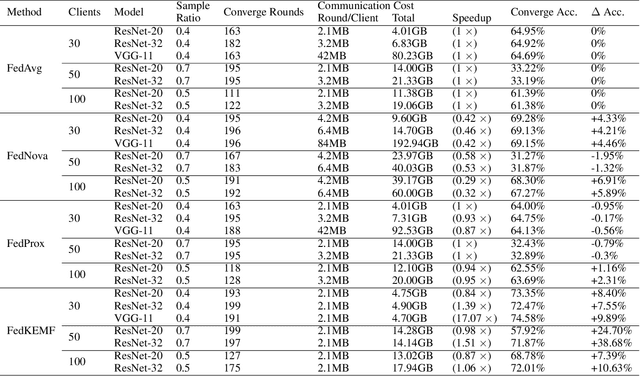
With increasing concern about user data privacy, federated learning (FL) has been developed as a unique training paradigm for training machine learning models on edge devices without access to sensitive data. Traditional FL and existing methods directly employ aggregation methods on all edges of the same models and training devices for a cloud server. Although these methods protect data privacy, they are not capable of model heterogeneity, even ignore the heterogeneous computing power, and incur steep communication costs. In this paper, we purpose a resource-aware FL to aggregate an ensemble of local knowledge extracted from edge models, instead of aggregating the weights of each local model, which is then distilled into a robust global knowledge as the server model through knowledge distillation. The local model and the global knowledge are extracted into a tiny size knowledge network by deep mutual learning. Such knowledge extraction allows the edge client to deploy a resource-aware model and perform multi-model knowledge fusion while maintaining communication efficiency and model heterogeneity. Empirical results show that our approach has significantly improved over existing FL algorithms in terms of communication cost and generalization performance in heterogeneous data and models. Our approach reduces the communication cost of VGG-11 by up to 102$\times$ and ResNet-32 by up to 30$\times$ when training ResNet-20 as the knowledge network.
SPATL: Salient Parameter Aggregation and Transfer Learning for Heterogeneous Clients in Federated Learning
Nov 29, 2021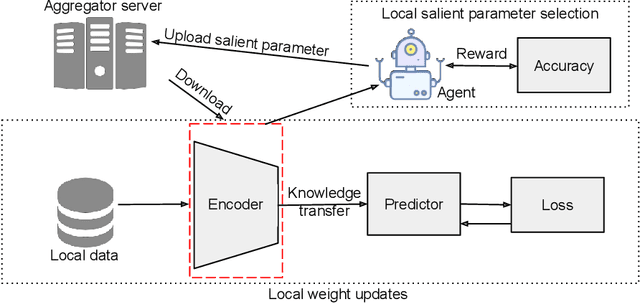
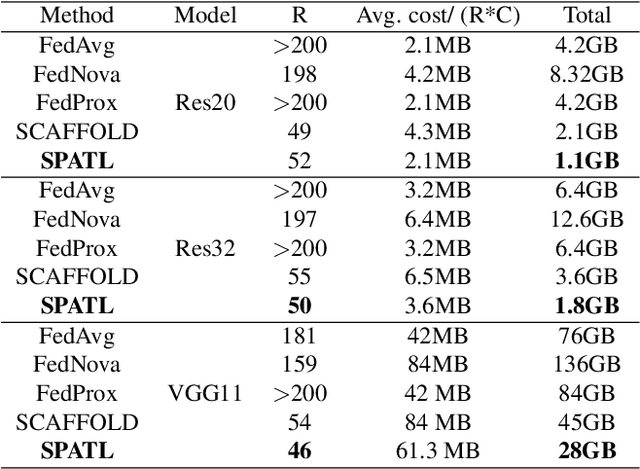
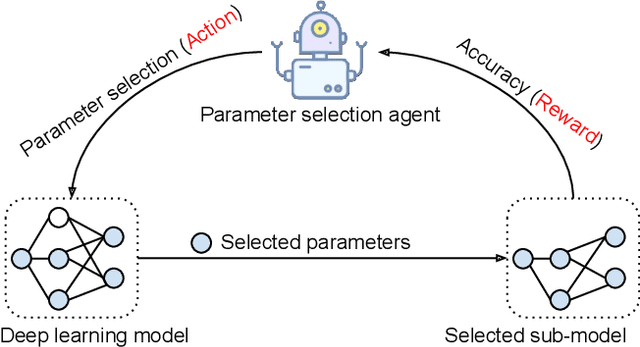
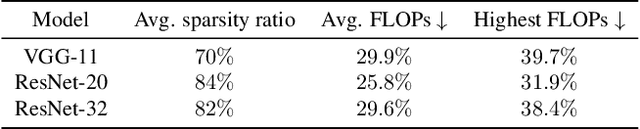
Efficient federated learning is one of the key challenges for training and deploying AI models on edge devices. However, maintaining data privacy in federated learning raises several challenges including data heterogeneity, expensive communication cost, and limited resources. In this paper, we address the above issues by (a) introducing a salient parameter selection agent based on deep reinforcement learning on local clients, and aggregating the selected salient parameters on the central server, and (b) splitting a normal deep learning model~(e.g., CNNs) as a shared encoder and a local predictor, and training the shared encoder through federated learning while transferring its knowledge to Non-IID clients by the local customized predictor. The proposed method (a) significantly reduces the communication overhead of federated learning and accelerates the model inference, while method (b) addresses the data heterogeneity issue in federated learning. Additionally, we leverage the gradient control mechanism to correct the gradient heterogeneity among clients. This makes the training process more stable and converge faster. The experiments show our approach yields a stable training process and achieves notable results compared with the state-of-the-art methods. Our approach significantly reduces the communication cost by up to 108 GB when training VGG-11, and needed $7.6 \times$ less communication overhead when training ResNet-20, while accelerating the local inference by reducing up to $39.7\%$ FLOPs on VGG-11.
Adaptive Dynamic Pruning for Non-IID Federated Learning
Jun 13, 2021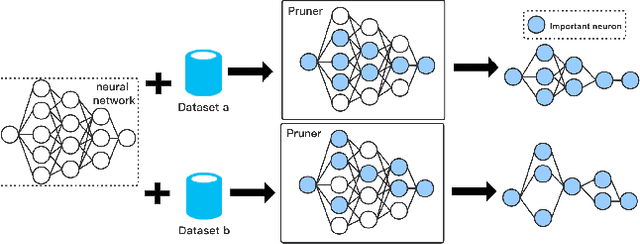
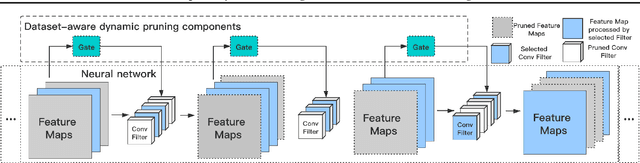
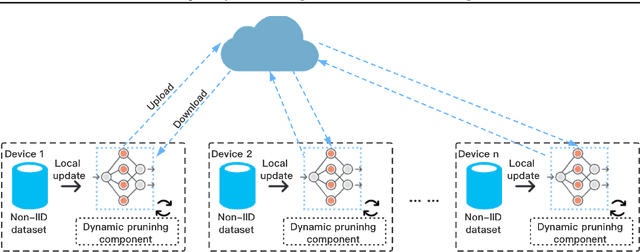
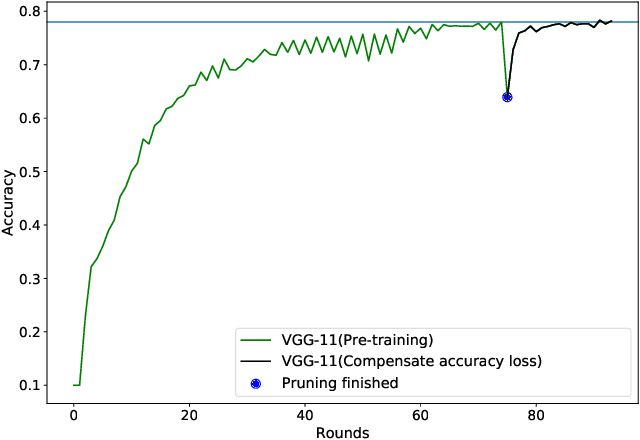
Federated Learning~(FL) has emerged as a new paradigm of training machine learning models without sacrificing data security and privacy. Learning models at edge devices such as cell phones is one of the most common use case of FL. However, the limited computing power and energy constraints of edge devices hinder the adoption of FL for both model training and deployment, especially for the resource-hungry Deep Neural Networks~(DNNs). To this end, many model compression methods have been proposed and network pruning is among the most well-known. However, a pruning policy for a given model is highly dataset-dependent, which is not suitable for non-Independent and Identically Distributed~(Non-IID) FL edge devices. In this paper, we present an adaptive pruning scheme for edge devices in an FL system, which applies dataset-aware dynamic pruning for inference acceleration on Non-IID datasets. Our evaluation shows that the proposed method accelerates inference by $2\times$~($50\%$ FLOPs reduction) while maintaining the model's quality on edge devices.
GNN-RL Compression: Topology-Aware Network Pruning using Multi-stage Graph Embedding and Reinforcement Learning
Feb 05, 2021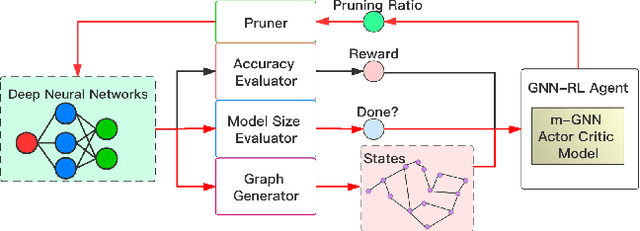
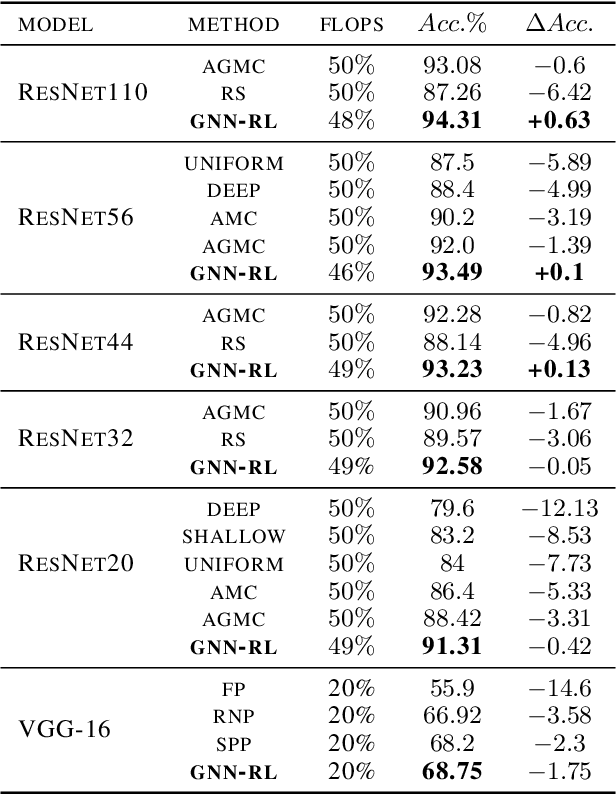

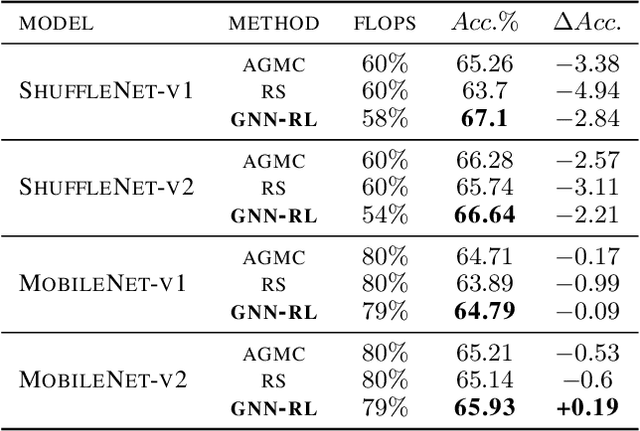
Model compression is an essential technique for deploying deep neural networks (DNNs) on power and memory-constrained resources. However, existing model-compression methods often rely on human expertise and focus on parameters' local importance, ignoring the rich topology information within DNNs. In this paper, we propose a novel multi-stage graph embedding technique based on graph neural networks (GNNs) to identify the DNNs' topology and use reinforcement learning (RL) to find a suitable compression policy. We performed resource-constrained (i.e., FLOPs) channel pruning and compared our approach with state-of-the-art compression methods using over-parameterized DNNs (e.g., ResNet and VGG-16) and mobile-friendly DNNs (e.g., MobileNet and ShuffleNet). We evaluated our method on various models from typical to mobile-friendly networks, such as ResNet family, VGG-16, MobileNet-v1/v2, and ShuffleNet. The results demonstrate that our method can prune dense networks (e.g., VGG-16) by up to 80% of their original FLOPs. More importantly, our method outperformed state-of-the-art methods and achieved a higher accuracy by up to 1.84% for ShuffleNet-v1. Furthermore, following our approach, the pruned VGG-16 achieved a noticeable 1.38$\times$ speed up and 141 MB GPU memory reduction.