 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Landscape and Challenges of HPC Research and LLMs
Feb 07, 2024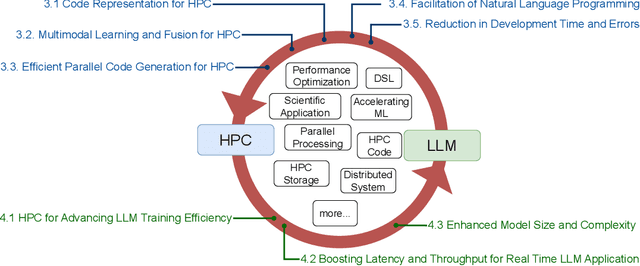

Recently, language models (LMs), especially large language models (LLMs), have revolutionized the field of deep learning. Both encoder-decoder models and prompt-based techniques have shown immense potential for natural language processing and code-based tasks. Over the past several years, many research labs and institutions have invested heavily in high-performance computing, approaching or breaching exascale performance levels. In this paper, we posit that adapting and utilizing such language model-based techniques for tasks in high-performance computing (HPC) would be very beneficial. This study presents our reasoning behind the aforementioned position and highlights how existing ideas can be improved and adapted for HPC tasks.
AUTOPARLLM: GNN-Guided Automatic Code Parallelization using Large Language Models
Oct 09, 2023



Parallelizing sequentially written programs is a challenging task. Even experienced developers need to spend considerable time finding parallelism opportunities and then actually writing parallel versions of sequentially written programs. To address this issue, we present AUTOPARLLM, a framework for automatically discovering parallelism and generating the parallel version of the sequentially written program. Our framework consists of two major components: i) a heterogeneous Graph Neural Network (GNN) based parallelism discovery and parallel pattern detection module, and ii) an LLM-based code generator to generate the parallel counterpart of the sequential programs. We use the GNN to learn the flow-aware characteristics of the programs to identify parallel regions in sequential programs and then construct an enhanced prompt using the GNN's results for the LLM-based generator to finally produce the parallel counterparts of the sequential programs. We evaluate AUTOPARLLM on 11 applications of 2 well-known benchmark suites: NAS Parallel Benchmark and Rodinia Benchmark. Our results show that AUTOPARLLM is indeed effective in improving the state-of-the-art LLM-based models for the task of parallel code generation in terms of multiple code generation metrics. AUTOPARLLM also improves the average runtime of the parallel code generated by the state-of-the-art LLMs by as high as 3.4% and 2.9% for the NAS Parallel Benchmark and Rodinia Benchmark respectively. Additionally, to overcome the issue that well-known metrics for translation evaluation have not been optimized to evaluate the quality of the generated parallel code, we propose OMPScore for evaluating the quality of the generated code. We show that OMPScore exhibits a better correlation with human judgment than existing metrics, measured by up to 75% improvement of Spearman correlation.
PERFOGRAPH: A Numerical Aware Program Graph Representation for Performance Optimization and Program Analysis
May 31, 2023



The remarkable growth and significant success of machine learning have expanded its applications into programming languages and program analysis. However, a key challenge in adopting the latest machine learning methods is the representation of programming languages, which directly impacts the ability of machine learning methods to reason about programs. The absence of numerical awareness, composite data structure information, and improper way of presenting variables in previous representation works have limited their performances. To overcome the limitations and challenges of current program representations, we propose a novel graph-based program representation called PERFOGRAPH. PERFOGRAPH can capture numerical information and the composite data structure by introducing new nodes and edges. Furthermore, we propose an adapted embedding method to incorporate numerical awareness. These enhancements make PERFOGRAPH a highly flexible and scalable representation that can effectively capture program intricate dependencies and semantics. Consequently, it serves as a powerful tool for various applications such as program analysis, performance optimization, and parallelism discovery. Our experimental results demonstrate that PERFOGRAPH outperforms existing representations and sets new state-of-the-art results by reducing the error rate by 7.4% (AMD dataset) and 10% (NVIDIA dataset) in the well-known Device Mapping challenge. It also sets new state-of-the-art results in various performance optimization tasks like Parallelism Discovery and Numa and Prefetchers Configuration prediction.
Learning to Parallelize with OpenMP by Augmented Heterogeneous AST Representation
May 09, 2023Detecting parallelizable code regions is a challenging task, even for experienced developers. Numerous recent studies have explored the use of machine learning for code analysis and program synthesis, including parallelization, in light of the success of machine learning in natural language processing. However, applying machine learning techniques to parallelism detection presents several challenges, such as the lack of an adequate dataset for training, an effective code representation with rich information, and a suitable machine learning model to learn the latent features of code for diverse analyses. To address these challenges, we propose a novel graph-based learning approach called Graph2Par that utilizes a heterogeneous augmented abstract syntax tree (Augmented-AST) representation for code. The proposed approach primarily focused on loop-level parallelization with OpenMP. Moreover, we create an OMP\_Serial dataset with 18598 parallelizable and 13972 non-parallelizable loops to train the machine learning models. Our results show that our proposed approach achieves the accuracy of parallelizable code region detection with 85\% accuracy and outperforms the state-of-the-art token-based machine learning approach. These results indicate that our approach is competitive with state-of-the-art tools and capable of handling loops with complex structures that other tools may overlook.