 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipeInfer: Accelerating LLM Inference using Asynchronous Pipelined Speculation
Jul 16, 2024



Inference of Large Language Models (LLMs) across computer clusters has become a focal point of research in recent times, with many acceleration techniques taking inspiration from CPU speculative execution. These techniques reduce bottlenecks associated with memory bandwidth, but also increase end-to-end latency per inference run, requiring high speculation acceptance rates to improve performance. Combined with a variable rate of acceptance across tasks, speculative inference techniques can result in reduced performance. Additionally, pipeline-parallel designs require many user requests to maintain maximum utilization. As a remedy, we propose PipeInfer, a pipelined speculative acceleration technique to reduce inter-token latency and improve system utilization for single-request scenarios while also improving tolerance to low speculation acceptance rates and low-bandwidth interconnects. PipeInfer exhibits up to a 2.15$\times$ improvement in generation speed over standard speculative inference. PipeInfer achieves its improvement through Continuous Asynchronous Speculation and Early Inference Cancellation, the former improving latency and generation speed by running single-token inference simultaneously with several speculative runs, while the latter improves speed and latency by skipping the computation of invalidated runs, even in the middle of inference.
The Landscape and Challenges of HPC Research and LLMs
Feb 07, 2024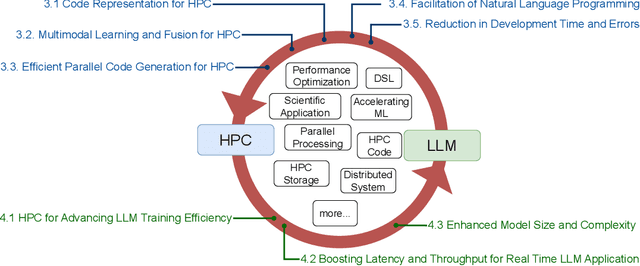

Recently, language models (LMs), especially large language models (LLMs), have revolutionized the field of deep learning. Both encoder-decoder models and prompt-based techniques have shown immense potential for natural language processing and code-based tasks. Over the past several years, many research labs and institutions have invested heavily in high-performance computing, approaching or breaching exascale performance levels. In this paper, we posit that adapting and utilizing such language model-based techniques for tasks in high-performance computing (HPC) would be very beneficial. This study presents our reasoning behind the aforementioned position and highlights how existing ideas can be improved and adapted for HPC tasks.