 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipeInfer: Accelerating LLM Inference using Asynchronous Pipelined Speculation
Jul 16, 2024



Inference of Large Language Models (LLMs) across computer clusters has become a focal point of research in recent times, with many acceleration techniques taking inspiration from CPU speculative execution. These techniques reduce bottlenecks associated with memory bandwidth, but also increase end-to-end latency per inference run, requiring high speculation acceptance rates to improve performance. Combined with a variable rate of acceptance across tasks, speculative inference techniques can result in reduced performance. Additionally, pipeline-parallel designs require many user requests to maintain maximum utilization. As a remedy, we propose PipeInfer, a pipelined speculative acceleration technique to reduce inter-token latency and improve system utilization for single-request scenarios while also improving tolerance to low speculation acceptance rates and low-bandwidth interconnects. PipeInfer exhibits up to a 2.15$\times$ improvement in generation speed over standard speculative inference. PipeInfer achieves its improvement through Continuous Asynchronous Speculation and Early Inference Cancellation, the former improving latency and generation speed by running single-token inference simultaneously with several speculative runs, while the latter improves speed and latency by skipping the computation of invalidated runs, even in the middle of inference.
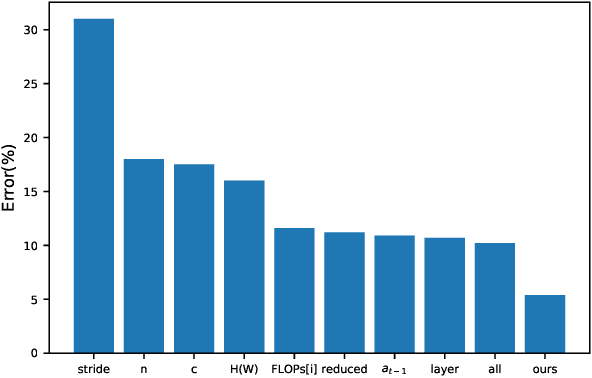
GNN-RL Compression: Topology-Aware Network Pruning using Multi-stage Graph Embedding and Reinforcement Learning
Feb 05, 2021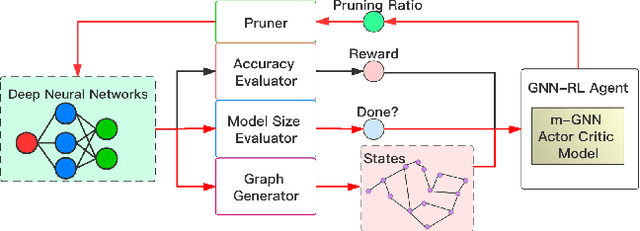
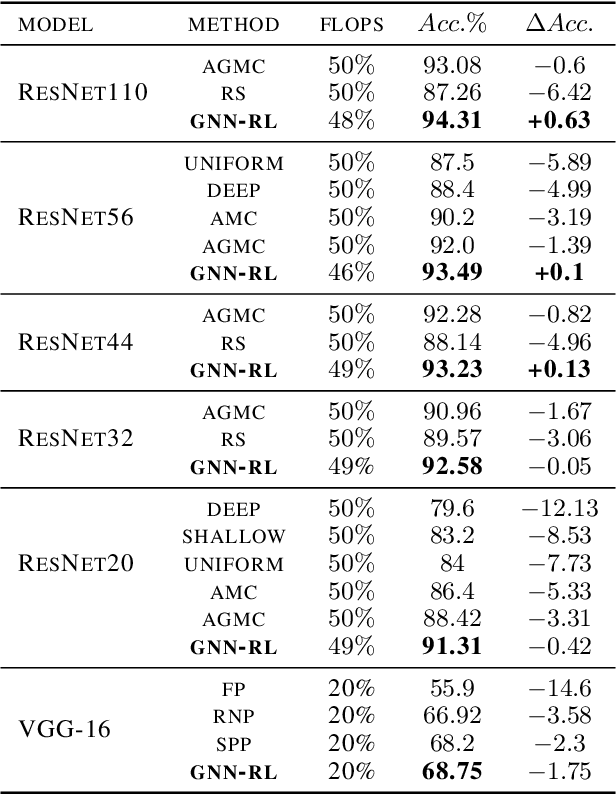

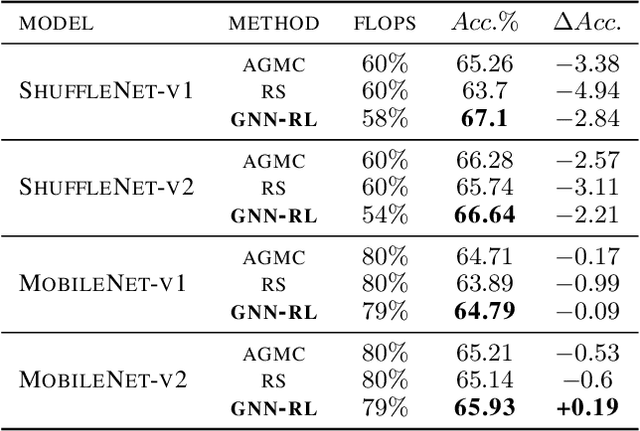
Model compression is an essential technique for deploying deep neural networks (DNNs) on power and memory-constrained resources. However, existing model-compression methods often rely on human expertise and focus on parameters' local importance, ignoring the rich topology information within DNNs. In this paper, we propose a novel multi-stage graph embedding technique based on graph neural networks (GNNs) to identify the DNNs' topology and use reinforcement learning (RL) to find a suitable compression policy. We performed resource-constrained (i.e., FLOPs) channel pruning and compared our approach with state-of-the-art compression methods using over-parameterized DNNs (e.g., ResNet and VGG-16) and mobile-friendly DNNs (e.g., MobileNet and ShuffleNet). We evaluated our method on various models from typical to mobile-friendly networks, such as ResNet family, VGG-16, MobileNet-v1/v2, and ShuffleNet. The results demonstrate that our method can prune dense networks (e.g., VGG-16) by up to 80% of their original FLOPs. More importantly, our method outperformed state-of-the-art methods and achieved a higher accuracy by up to 1.84% for ShuffleNet-v1. Furthermore, following our approach, the pruned VGG-16 achieved a noticeable 1.38$\times$ speed up and 141 MB GPU memory reduction.
Auto Graph Encoder-Decoder for Model Compression and Network Acceleration
Dec 31, 2020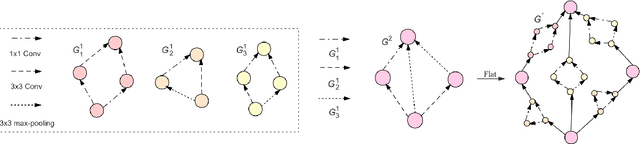
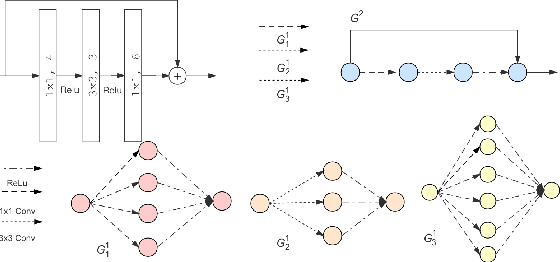

Model compression aims to deploy deep neural networks (DNN) to mobile devices with limited computing power and storage resource. However, most of the existing model compression methods rely on manually defined rules, which requires domain expertise. In this paper, we propose an Auto Graph encoder-decoder Model Compression (AGMC) method combined with graph neural networks (GNN) and reinforcement learning (RL) to find the best compression policy. We model the target DNN as a graph and use GNN to learn the embeddings of the DNN automatically. In our experiments, we first compared our method with rule-based DNN embedding methods to show the graph auto encoder-decoder's effectiveness. Our learning-based DNN embedding achieved better performance and a higher compression ratio with fewer search steps. Moreover, we evaluated the AGMC on CIFAR-10 and ILSVRC-2012 datasets and compared handcrafted and learning-based model compression approaches. Our method outperformed handcrafted and learning-based methods on ResNet-56 with 3.6% and 1.8% higher accuracy, respectively. Furthermore, we achieved a higher compression ratio than state-of-the-art methods on MobileNet-V2 with just 0.93% accuracy loss.