 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNN-RL Compression: Topology-Aware Network Pruning using Multi-stage Graph Embedding and Reinforcement Learning
Paper and Code
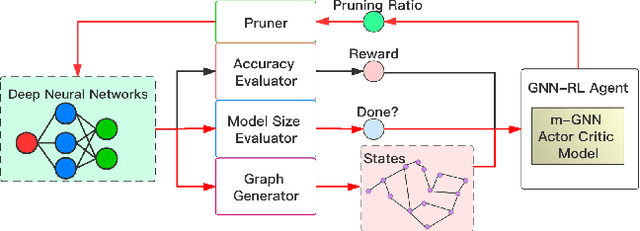
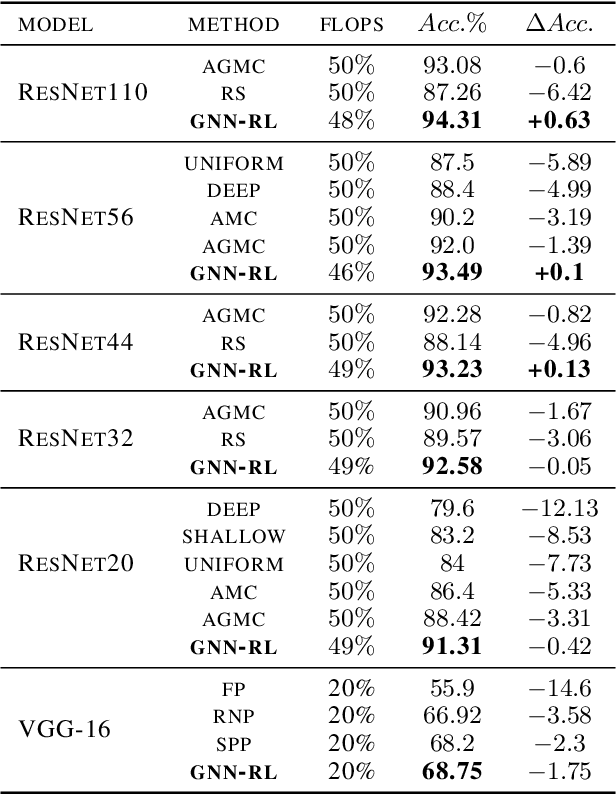

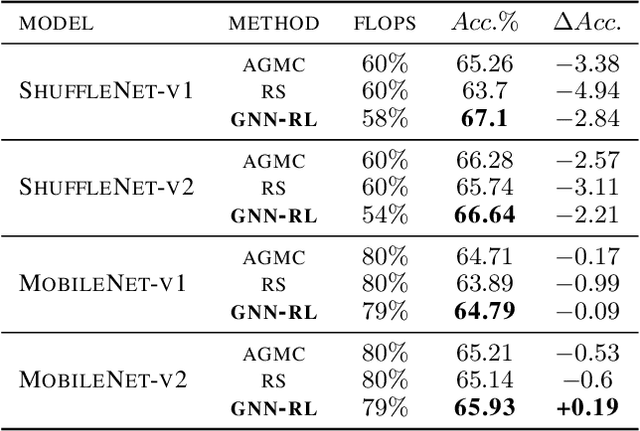
Model compression is an essential technique for deploying deep neural networks (DNNs) on power and memory-constrained resources. However, existing model-compression methods often rely on human expertise and focus on parameters' local importance, ignoring the rich topology information within DNNs. In this paper, we propose a novel multi-stage graph embedding technique based on graph neural networks (GNNs) to identify the DNNs' topology and use reinforcement learning (RL) to find a suitable compression policy. We performed resource-constrained (i.e., FLOPs) channel pruning and compared our approach with state-of-the-art compression methods using over-parameterized DNNs (e.g., ResNet and VGG-16) and mobile-friendly DNNs (e.g., MobileNet and ShuffleNet). We evaluated our method on various models from typical to mobile-friendly networks, such as ResNet family, VGG-16, MobileNet-v1/v2, and ShuffleNet. The results demonstrate that our method can prune dense networks (e.g., VGG-16) by up to 80% of their original FLOPs. More importantly, our method outperformed state-of-the-art methods and achieved a higher accuracy by up to 1.84% for ShuffleNet-v1. Furthermore, following our approach, the pruned VGG-16 achieved a noticeable 1.38$\times$ speed up and 141 MB GPU memory reduction.