 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptiML: An End-to-End Framework for Program Synthesis and CUDA Kernel Optimization
Feb 12, 2026Generating high-performance CUDA kernels remains challenging due to the need to navigate a combinatorial space of low-level transformations under noisy and expensive hardware feedback. Although large language models can synthesize functionally correct CUDA code, achieving competitive performance requires systematic exploration and verification of optimization choices. We present OptiML, an end-to-end framework that maps either natural-language intent or input CUDA code to performance-optimized CUDA kernels by formulating kernel optimization as search under verification. OptiML consists of two decoupled stages. When the input is natural language, a Mixture-of-Thoughts generator (OptiML-G) acts as a proposal policy over kernel implementation strategies, producing an initial executable program. A search-based optimizer (OptiML-X) then refines either synthesized or user-provided kernels using Monte Carlo Tree Search over LLM-driven edits, guided by a hardware-aware reward derived from profiler feedback. Each candidate transformation is compiled, verified, and profiled with Nsight Compute, and evaluated by a composite objective that combines runtime with hardware bottleneck proxies and guardrails against regressions. We evaluate OptiML in both synthesis-and-optimize and optimization-only settings on a diverse suite of CUDA kernels. Results show that OptiML consistently discovers verified performance improvements over strong LLM baselines and produces interpretable optimization trajectories grounded in profiler evidence.
OMPILOT: Harnessing Transformer Models for Auto Parallelization to Shared Memory Computing Paradigms
Nov 11, 2025Recent advances in large language models (LLMs) have significantly accelerated progress in code translation, enabling more accurate and efficient transformation across programming languages. While originally developed for natural language processing, LLMs have shown strong capabilities in modeling programming language syntax and semantics, outperforming traditional rule-based systems in both accuracy and flexibility. These models have streamlined cross-language conversion, reduced development overhead, and accelerated legacy code migration. In this paper, we introduce OMPILOT, a novel domain-specific encoder-decoder transformer tailored for translating C++ code into OpenMP, enabling effective shared-memory parallelization. OMPILOT leverages custom pre-training objectives that incorporate the semantics of parallel constructs and combines both unsupervised and supervised learning strategies to improve code translation robustness. Unlike previous work that focused primarily on loop-level transformations, OMPILOT operates at the function level to capture a wider semantic context. To evaluate our approach, we propose OMPBLEU, a novel composite metric specifically crafted to assess the correctness and quality of OpenMP parallel constructs, addressing limitations in conventional translation metrics.
VeriMoA: A Mixture-of-Agents Framework for Spec-to-HDL Generation
Oct 31, 2025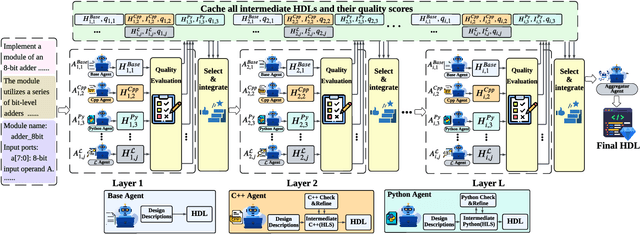
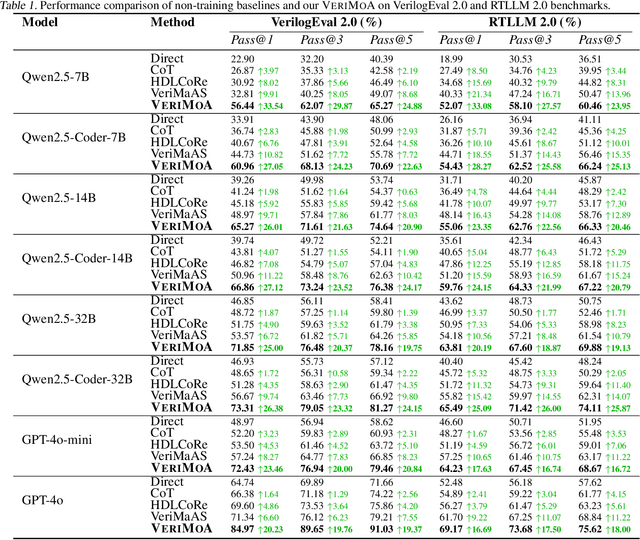
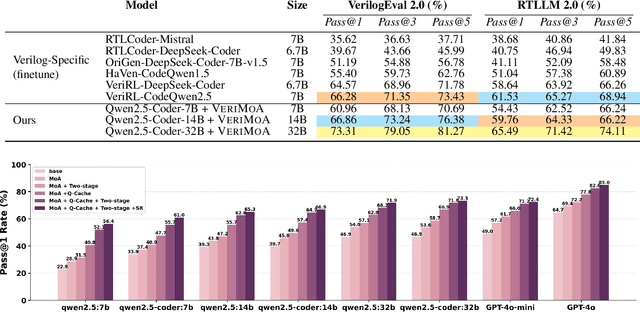
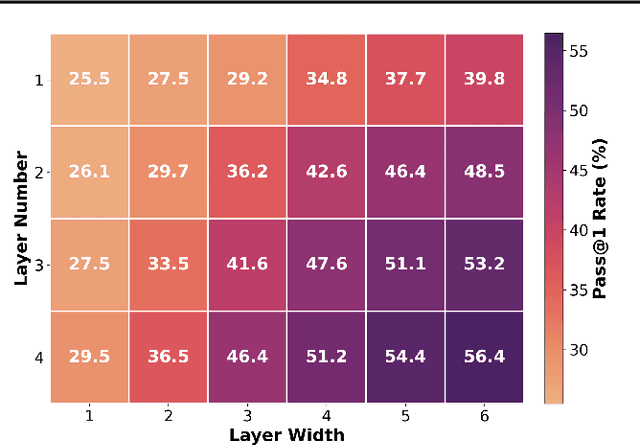
Automation of Register Transfer Level (RTL) design can help developers meet increasing computational demands. Large Language Models (LLMs) show promise for Hardware Description Language (HDL) generation, but face challenges due to limited parametric knowledge and domain-specific constraints. While prompt engineering and fine-tuning have limitations in knowledge coverage and training costs, multi-agent architectures offer a training-free paradigm to enhance reasoning through collaborative generation. However, current multi-agent approaches suffer from two critical deficiencies: susceptibility to noise propagation and constrained reasoning space exploration. We propose VeriMoA, a training-free mixture-of-agents (MoA) framework with two synergistic innovations. First, a quality-guided caching mechanism to maintain all intermediate HDL outputs and enables quality-based ranking and selection across the entire generation process, encouraging knowledge accumulation over layers of reasoning. Second, a multi-path generation strategy that leverages C++ and Python as intermediate representations, decomposing specification-to-HDL translation into two-stage processes that exploit LLM fluency in high-resource languages while promoting solution diversity. Comprehensive experiments on VerilogEval 2.0 and RTLLM 2.0 benchmarks demonstrate that VeriMoA achieves 15--30% improvements in Pass@1 across diverse LLM backbones, especially enabling smaller models to match larger models and fine-tuned alternatives without requiring costly training.
CodeRosetta: Pushing the Boundaries of Unsupervised Code Translation for Parallel Programming
Oct 27, 2024



Recent advancements in Large Language Models (LLMs) have renewed interest in automatic programming language translation. Encoder-decoder transformer models, in particular, have shown promise in translating between different programming languages. However, translating between a language and its high-performance computing (HPC) extensions remains underexplored due to challenges such as complex parallel semantics. In this paper, we introduce CodeRosetta, an encoder-decoder transformer model designed specifically for translating between programming languages and their HPC extensions. CodeRosetta is evaluated on C++ to CUDA and Fortran to C++ translation tasks. It uses a customized learning framework with tailored pretraining and training objectives to effectively capture both code semantics and parallel structural nuances, enabling bidirectional translation. Our results show that CodeRosetta outperforms state-of-the-art baselines in C++ to CUDA translation by 2.9 BLEU and 1.72 CodeBLEU points while improving compilation accuracy by 6.05%. Compared to general closed-source LLMs, our method improves C++ to CUDA translation by 22.08 BLEU and 14.39 CodeBLEU, with 2.75% higher compilation accuracy. Finally, CodeRosetta exhibits proficiency in Fortran to parallel C++ translation, marking it, to our knowledge, as the first encoder-decoder model for this complex task, improving CodeBLEU by at least 4.63 points compared to closed-source and open-code LLMs.
The Landscape and Challenges of HPC Research and LLMs
Feb 07, 2024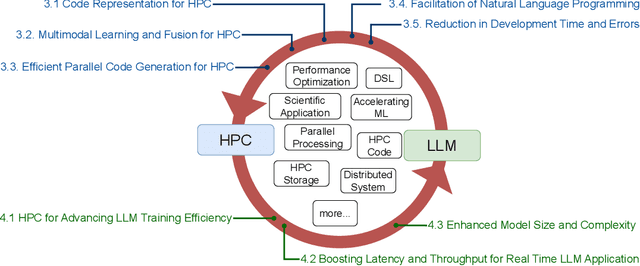

Recently, language models (LMs), especially large language models (LLMs), have revolutionized the field of deep learning. Both encoder-decoder models and prompt-based techniques have shown immense potential for natural language processing and code-based tasks. Over the past several years, many research labs and institutions have invested heavily in high-performance computing, approaching or breaching exascale performance levels. In this paper, we posit that adapting and utilizing such language model-based techniques for tasks in high-performance computing (HPC) would be very beneficial. This study presents our reasoning behind the aforementioned position and highlights how existing ideas can be improved and adapted for HPC tasks.
OMPGPT: A Generative Pre-trained Transformer Model for OpenMP
Jan 28, 2024Large language models (LLMs), as epitomized by models like ChatGPT, have revolutionized the field of natural language processing (NLP). Along with this trend, code-based large language models such as StarCoder, WizardCoder, and CodeLlama have emerged, trained extensively on vast repositories of code data. Yet, inherent in their design, these models primarily focus on generative tasks like code generation, code completion, and comment generation, and general support for multiple programming languages. While the generic abilities of code LLMs are useful for many programmers, the area of high-performance computing (HPC) has a narrower set of requirements that make a smaller and more domain-specific LM a smarter choice. This paper introduces OMPGPT, a novel model meticulously designed to harness the inherent strengths of language models for OpenMP pragma generation. Furthermore, we adopt and adapt prompt engineering techniques from the NLP domain to create chain-of-OMP, an innovative strategy designed to enhance OMPGPT's effectiveness. Our extensive evaluations demonstrate that OMPGPT outperforms existing large language models specialized in OpenMP tasks and maintains a notably smaller size, aligning it more closely with the typical hardware constraints of HPC environments. We consider our contribution as a pivotal bridge, connecting the advantage of language models with the specific demands of HPC tasks. The success of OMPGPT lays a solid foundation, suggesting its potential applicability and adaptability to a wider range of HPC tasks, thereby opening new avenues in the field of computational efficiency and effectiveness.
CompCodeVet: A Compiler-guided Validation and Enhancement Approach for Code Dataset
Nov 11, 2023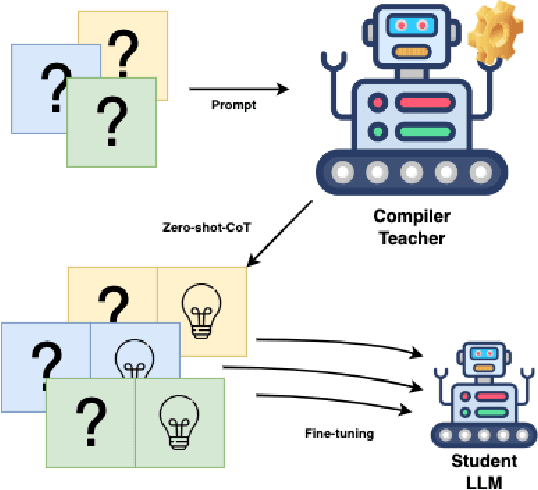
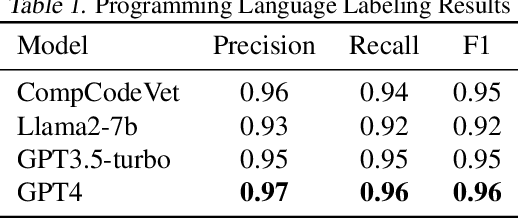

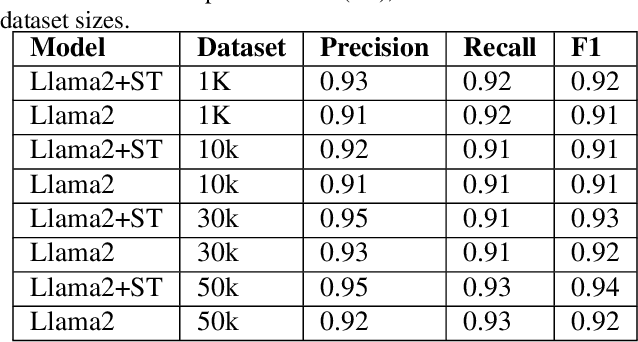
Large language models (LLMs) have become increasingly prominent in academia and industry due to their remarkable performance in diverse applications. As these models evolve with increasing parameters, they excel in tasks like sentiment analysis and machine translation. However, even models with billions of parameters face challenges in tasks demanding multi-step reasoning. Code generation and comprehension, especially in C and C++, emerge as significant challenges. While LLMs trained on code datasets demonstrate competence in many tasks, they struggle with rectifying non-compilable C and C++ code. Our investigation attributes this subpar performance to two primary factors: the quality of the training dataset and the inherent complexity of the problem which demands intricate reasoning. Existing "Chain of Thought" (CoT) prompting techniques aim to enhance multi-step reasoning. This approach, however, retains the limitations associated with the latent drawbacks of LLMs. In this work, we propose CompCodeVet, a compiler-guided CoT approach to produce compilable code from non-compilable ones. Diverging from the conventional approach of utilizing larger LLMs, we employ compilers as a teacher to establish a more robust zero-shot thought process. The evaluation of CompCodeVet on two open-source code datasets shows that CompCodeVet has the ability to improve the training dataset quality for LLMs.